代码随想录
1. 链表类型:单列表,双列表,循环列表。
单列表:

双列表:

循环列表:

2. 链表的操作:删除节点,增加节点。
删除节点:

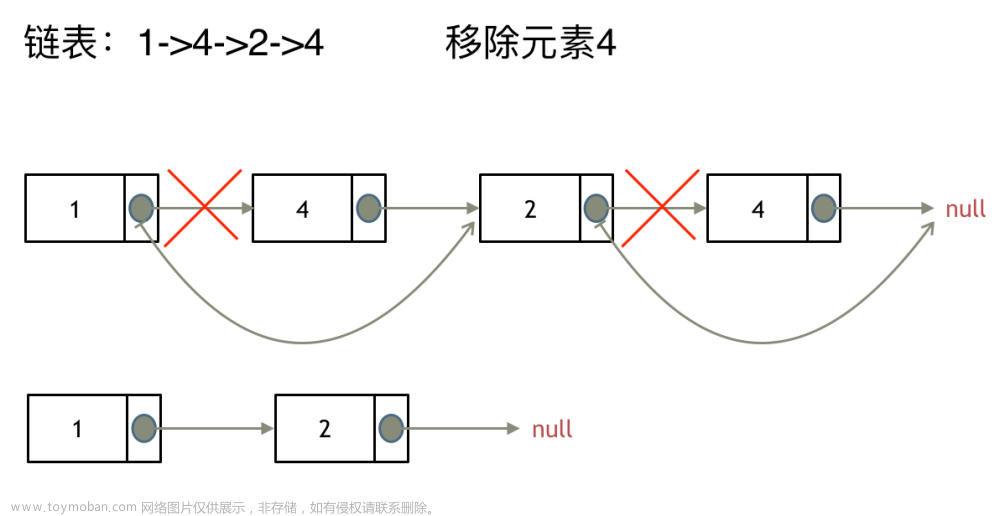
其中对于普通的节点删除,就如上图所示,直接让前一个节点的指向下一个节点即可。
但是对于头节点,应该让头节点往下移一个,让下一个节点作为新的头节点,即 head = head.next 。
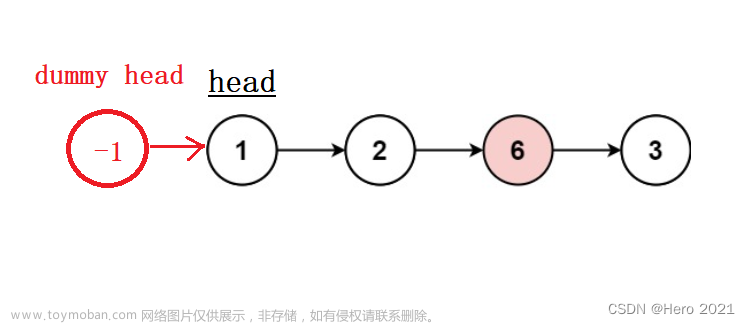
以上我们可以看到,删除头节点和其他节点的方法是两种方法,方法不统一。我们是否可以用一种统一的方法来删除头节点呢?答案是肯定的。这个方法叫做虚拟头节点。
即我们设置一个dummy head, 并让这个虚拟的节点指向我们的头节点。
添加节点:

可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
3. 性能分析
再把链表的特性和数组的特性进行一个对比:

数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
题目练习
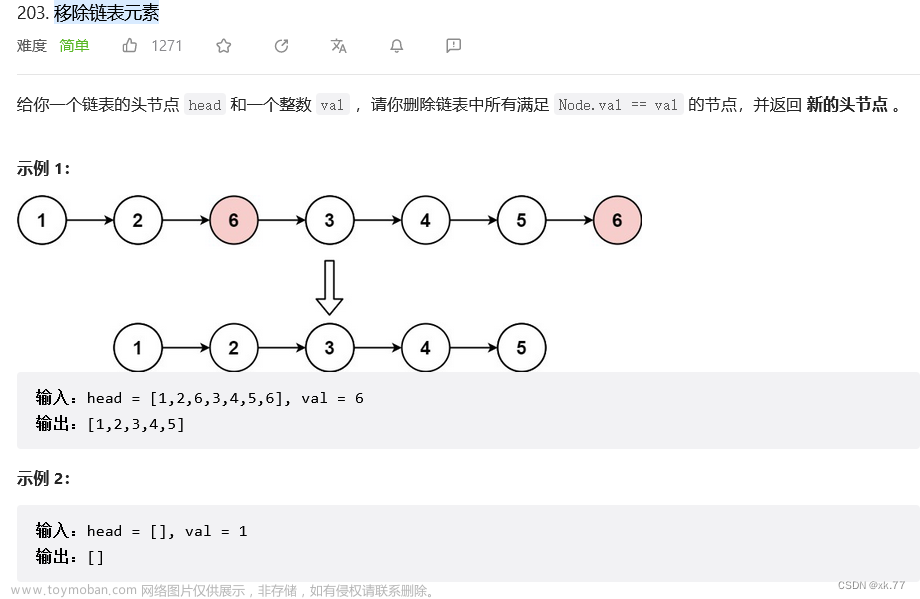
203. 移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:输入:head = [], val = 1
输出:[]
示例 3:输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50

删除的思路和重点:

定义一个临时指针curr用来遍历整个列表, head指向为返回的列表。
方法一:正常的方法
我们先用第一种正常的方法,头节点和正常节点不同的删除操作来写一下,具体规则为:
其中对于普通的节点删除,直接让前一个节点的指向下一个节点即可,即curr.next = curr.next.next。如果不删除就直接让curr指向下一个节点即可,即curr = curr.next.next
但是对于头节点,应该让头节点往下移一个,让下一个节点作为新的头节点,即 head = head.next 。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def removeElements(self, head, val):
"""
:type head: ListNode
:type val: int
:rtype: ListNode
"""
# 方法一
# 删除head
while head is not None and head.val == val:
head = head.next
# 删除其他节点
curr = head
while curr is not None and curr.next is not None:
if curr.next.val == val:
curr.next = curr.next.next
else:
curr = curr.next
return head方法二:虚拟头节点的方法
先实例化一个虚拟头节点dummy head,让dummy head指向原来的head。
dummy = ListNode(0)
dummy.next = head
创建一个哑节点来处理头结点可能被删除的情况。然后遍历链表,对于每个节点,如果节点的值和目标值相等,那么跳过这个节点;否则,将这个节点接在新链表的后面。
这里的curr应该等于dummy。
这里值得注意的是,最后return的是dummy.next,而不是head了,因为head可能已经被删了。而dummy.next指向的删除完后的新链表的所有节点。

代码如下:
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def removeElements(self, head, val):
"""
:type head: ListNode
:type val: int
:rtype: ListNode
time: O(n)。需要遍历整个链表一次,n 是链表的长度。需要检查每一个节点看其值是否等于 val。
space: O(1)。没有使用任何额外的空间来存储数据。
你只是使用了几个指针(如 curr 和 head)。这些指针的数量不随 n 的大小改变
"""
# 方法二 虚拟头节点
# 定义一个新的头节点
dummy = ListNode(0)
dummy.next = head
curr = dummy # 用来便利链表
while curr is not None and curr.next is not None:
if curr.next.val == val:
curr.next = curr.next.next
else:
curr = curr.next
return dummy.next707. 设计链表
你可以选择使用单链表或者双链表,设计并实现自己的链表。
单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。
如果是双向链表,则还需要属性 prev 以指示链表中的上一个节点。假设链表中的所有节点下标从 0 开始。
实现 MyLinkedList 类:
MyLinkedList() 初始化 MyLinkedList 对象。
int get(int index) 获取链表中下标为 index 的节点的值。如果下标无效,则返回 -1 。
void addAtHead(int val) 将一个值为 val 的节点插入到链表中第一个元素之前。在插入完成后,新节点会成为链表的第一个节点。
void addAtTail(int val) 将一个值为 val 的节点追加到链表中作为链表的最后一个元素。
void addAtIndex(int index, int val) 将一个值为 val 的节点插入到链表中下标为 index 的节点之前。如果 index 等于链表的长度,那么该节点会被追加到链表的末尾。如果 index 比长度更大,该节点将 不会插入 到链表中。
void deleteAtIndex(int index) 如果下标有效,则删除链表中下标为 index 的节点。
示例:
输入
["MyLinkedList", "addAtHead", "addAtTail", "addAtIndex", "get", "deleteAtIndex", "get"]
[[], [1], [3], [1, 2], [1], [1], [1]]
输出
[null, null, null, null, 2, null, 3]解释
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // 链表变为 1->2->3
myLinkedList.get(1); // 返回 2
myLinkedList.deleteAtIndex(1); // 现在,链表变为 1->3
myLinkedList.get(1); // 返回 3
提示:
0 <= index, val <= 1000
请不要使用内置的 LinkedList 库。
调用 get、addAtHead、addAtTail、addAtIndex 和 deleteAtIndex 的次数不超过 2000 。
这道题把链表常考的操作都包括了,分别为:
1)获取第几个节点的值
2)头部插入节点
3)尾部插入节点
4)第n个节点前插入节点
5)删除第n个节点
为了方便我们对链表进行增和删的操作,在这道题中统一使用虚拟头节点的方法。
我们仍然需要定义一个指针curr,用于遍历整个链表。
具体的一些细节:
1)获取第几个节点的值
- 默认列表是从0开始的
- 合法性判断, n不能 n < 0 或 n > size -1,n = size -1返回链表最后一个元素。
- curr = dummy.next, 用于获取当前的节点
2)头部插入节点
- 插入顺序需要注意,应该先使new node指向下一个节点head,然后再让上一个节点dummy指向new node。
核心思想 1: 第n个节点一定是curr.next。这样我们才能使用curr对链表进行增加和删除的操作。

核心思想 2: 插入节点的时候,一定是先更新new node指向下一个节点,再更新前一个节点指向new node。

下面是代码:
class ListNode:
def __init__(self, val = 0, next = None):
self.val = val
self.next = next
class MyLinkedList(object):
# time: 涉及 index 的相关操作为 O(index), 其余为 O(1)
# space: O(1)
def __init__(self):
self.dummy_head = ListNode(0) # 虚拟头节点,指向head
self.size = 0
def get(self, index):
"""
:type index: int
:rtype: int
"""
if index < 0 or index >= self.size:
return -1
curr = self.dummy_head # curr指向head节点
for i in range(index + 1):
curr = curr.next
return curr.val
def addAtHead(self, val):
"""
:type val: int
:rtype: None
"""
# 在头部添加一个新的节点。新的节点的值是 val,并且它的下一个节点是当前的
# 第一个节点( 即 self.dummy_head.next)。
self.dummy_head.next = ListNode(val,self.dummy_head.next)
self.size += 1
def addAtTail(self, val):
"""
:type val: int
:rtype: None
"""
curr = self.dummy_head
while curr.next:
curr = curr.next
curr.next = ListNode(val, None)
self.size += 1
def addAtIndex(self, index, val):
"""
:type index: int
:type val: int
:rtype: None
"""
if index < 0 or index > self.size:
# index = self.size等同于在链表尾端插入
return
curr = self.dummy_head
for i in range(index):
curr = curr.next
curr.next = ListNode(val, curr.next)
self.size += 1
def deleteAtIndex(self, index):
"""
:type index: int
:rtype: None
"""
if index < 0 or index >= self.size:
return
curr = self.dummy_head
for i in range(index):
curr = curr.next
curr.next = curr.next.next
self.size -= 1
# Your MyLinkedList object will be instantiated and called as such:
# obj = MyLinkedList()
# param_1 = obj.get(index)
# obj.addAtHead(val)
# obj.addAtTail(val)
# obj.addAtIndex(index,val)
# obj.deleteAtIndex(index)我列了张表总结了一下各个方法的方法,用于总结和对比:

基于上表可以总结:
- 所有涉及index的操作(get, addAtIndex, deleteAtIndex) 都需要判断index是否在合理区间。其中get和deleteAtIndex方法的合理区间都为if index < 0 or index >= self.size,因为索引是从0开始的, 如果 index = self.size,则超出索引区间了,要报错。 但是对于addAtIndex方法,合理区间为 if index < 0 or index > self.size, 这是因为index = self.size等同于在链表尾端插入。
- 除了addAtHead方法可以直接对dummy head进行操作,剩下的都需要遍历链表,遍历的时候需要curr。其中curr = self.dummy_head。
- 除了addAtHead方法,剩下的都需要遍历链表。对于涉及index的操作(get, addAtIndex, deleteAtIndex) :get方法是for i in range(index + 1),因为需要先获取的是dummy的下一位,+1表示这个操作;addAtInde 和 deleteAtIndex 方法则直接 for i in range(index) 遍历链表即可。而对于 addAtTail 方法,和index无关,只需要判断是否遍历到链表的tail处,因此直接判断 while curr.next,为 True则表示没到达, curr = curr.next 即可。
- 对于增删操作,要注意第n个节点一定是curr.next,因此第n个节点的前一个节点为curr,后一个节点为curr.next.next。增加操作插入的值都是 当前值.next = ListNode(val, 当前值.next)。
- 对于增删操作,都涉及增加的 self.size += 1或者删除的 self.size -= 1。
206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
输入:head = [1,2]
输出:[2,1]
示例 3:输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?


思路:翻转链表其实就是对链表next指向的翻转。


这道题有两种解法,一个是双指针解法,一个是递归解法。我们先看双指针解法。理解了双指针后,对照着其再写递归方法。
双指针解法:
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
time: O(n)
space: O(1)
"""
pre = None # 最终返回的值,指向头节点
curr = head #用于遍历
while curr:
temp = curr.next #临时储存值,因为下一步curr的值会变
curr.next = pre
pre = curr
curr = temp
return pre递归解法:
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution(object):
def reverse(self, curr, pre):
if curr is None: return pre
temp = curr.next
curr.next = pre
return self.reverse(temp,curr)
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
time: O(n)
space: O(n)
"""
# 递归解法
return self.reverse(head, None)两种代码的伪代码比较:文章来源:https://www.toymoban.com/news/detail-560907.html
 文章来源地址https://www.toymoban.com/news/detail-560907.html
文章来源地址https://www.toymoban.com/news/detail-560907.html
到了这里,关于Day 3 链表: 203.移除链表元素, 707.设计链表, 206.反转链表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!