一. 概述
1.1 整体结构
GLM-6B模型服务器
↓ 8000端口
chatgpt-mirai-qq-bot
↓ 接收转发 添加头信息
go-cqhttp qq群机器人
- 以下chatgpt-mirai-qq-bot简称GPT转发程序
1.2 目标
实现本地化部署的GLM q群机器人
1.3 需求
- 最好16GB的显存 显卡性能要求不高
- window环境
1.4 流程说明
该项目的是利用lss233大佬的项目一头对接GLM模型将其消息处理成go-cqhttp可以处理的形式最后发送到qq群内
lss233大佬的项目地址
https://github.com/lss233/chatgpt-mirai-qq-bot
二. 部署流程
看的出流程的核心是GPT转发程序
2.1 使用GPT转发程序帮助文档
2.1.1 使用git安装GLM
首先我们跟着GPT转发程序的文档一步一步来
文档地址
https://chatgpt-qq.lss233.com/pei-zhi-wen-jian-jiao-cheng/jie-ru-ai-ping-tai/jie-ru-chatglm
# 下载项目
git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
# 安装依赖
pip install -r requirements.txt
pip install fastapi uvicorn
# 启动
python api.py

- 所以这里我们需要安装git和python没啥好说的
python最好使用3.10.10 git直接next next安装就完事了
2.1.2 不使用git安装GLM
这里安装Chat的时候你可以不使用git来进行安装
因为这里面的模型文件特别大 容易下不下来 不会科学的下的很慢
如果出现这种情况 删掉下载的项目
https://www.bilibili.com/video/BV1gX4y1C7Ak/?spm_id_from=333.337.search-card.all.click&vd_source=ac6f57cbd263a9d994cdb0bece060fc9
跟着这个视频前面做
这里如果我们跟着帮助文档的走python api.py它就会报错
E:\AI\GLM6b\ChatGLM-6B>Python api.py
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Symbol cudaLaunchKernel not found in C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common\cudart64_65.dll
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 8/8 [00:07<00:00, 1.01it/s]
Traceback (most recent call last):
File "E:\AI\GLM6b\ChatGLM-6B\api.py", line 54, in <module>
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 905, in cuda
return self._apply(lambda t: t.cuda(device))
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 797, in _apply
module._apply(fn)
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 797, in _apply
module._apply(fn)
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 820, in _apply
param_applied = fn(param)
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 905, in <lambda>
return self._apply(lambda t: t.cuda(device))
File "C:\Users\jsp\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\cuda\__init__.py", line 239, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
这一坨的报错一共两个意思
- 装cuda
- 装torch
所以这里我们因该是去装这两玩意 但是我装了半天没装好
步骤因该是 先装cuda 再装 torch 但是这个torch在windows上对cuda的版本要求严格 所以如果你要正常装 我建议你先看torch的版本然后找到对应的cuda版本进行安装
我这里跳到另外一个up的Anaconda Navigator视频
https://www.bilibili.com/video/BV1gX4y1C7Ak/?spm_id_from=333.337.search-card.all.click&vd_source=ac6f57cbd263a9d994cdb0bece060fc9
当时都没想着能用但是这个Anaconda Navigator模拟了一个python环境3.10.10的环境结果就能用了
2.2 使用Anaconda Navigator 虚拟运行GLM
感谢这个BillBum up做了排除问题的视频 不然我还不知道咋搞
实在不知道怎么弄的跟视频
2.2.1 https://www.anaconda.com/上下载Anaconda

2.2.2 安装的时候最好不要安在c盘 同时注意


修改环境文件路径
2.2.3 找到安装好的anaconda 运行anaconda Navigator





2.2.4 启动anconda的终端

2.2.5 anconda环境依赖安装
cd到我们刚才操作的代码的目录

依赖不放心就再安装一次
2.2.6 启动躺雷

- up主的视频是想使用web网站 但我们是要用api接口 但是可以用它的文件来下载相关的依赖 其实是当时想跟着做出来

2.2.7 处理同样的报错
- 输入启动命令 出现同样的报错

2.2.8 虚拟环境中下载pytorch




- 这里如果没有就重新启动anaconda一次再进来

- 再次启动调试

- 尝试启动发现差依赖 差什么装什么


- 差什么装什么
- 能启动他的web当然好 同时我们也要尝试我们的 python api.py
2.2.9 成功运行GLM

- 可以看到它端口开在8000
三. GPT转发程序接入 GLM
3.1 下载接入程序
git上下载lss233大佬的转接程序
https://github.com/lss233/chatgpt-mirai-qq-bot


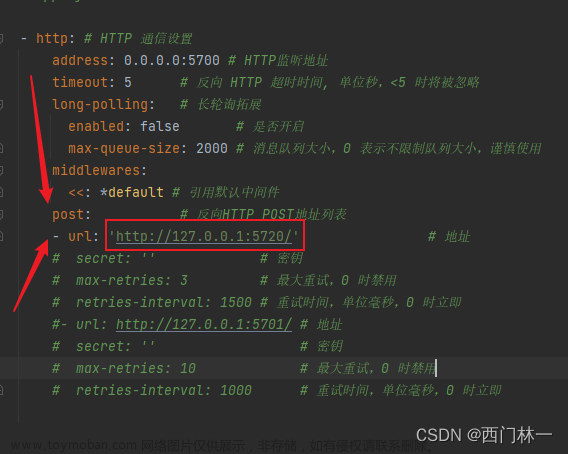
3.2 参考接入程序教程修改配置文件

3.2.1 修改接入

3.2.2 修改对接go-cqhttp

四. go-cqhttp对接和使用
go-cq也是一个很有名的项目了
项目地址https://github.com/Mrs4s/go-cqhttp
找一个喜欢的版本安装 我用的这个
4.1 下载 go-cqhttp
你可以在这里下载最新的 go-cqhttp:https://github.com/Mrs4s/go-cqhttp/releases
4.2 初始化 go-cqhttp
解压并启动 go-cqhttp,选 3 后回车,退出程序。
4.3 设置 go-cqhttp
编辑 go-cqhttp 的 config.yaml,设置机器人的 QQ 号和反向 Universal 地址 (这个反向 Universal 地址和前面的 reverse_ws_host 、reverse_ws_port )有关


这里的 universal 地址的写法如下:
- 如果你的 go-cqhttp 和 chatgpt 在同一台机器上,那么就写: ws://localhost:8566/ws ,这里的 8566 和 reverse_ws_port的值是一样的。
- 如果你的 go-cqhttp 和 chatgpt 在不同的机器上,那么就在上面的基础上,把 localhost 改成你 chatgpt 服务器的 IP 地址。
4.4 启动 go-cqhttp,生成配置文件
首次启动时我们不要登录 QQ,我们只是需要它生成的 device.json文件。

4.5 打开 device.json,修改协议
找到 protocol,把后面的数字改成 2,然后保存并退出即可。
这会让 go-cqhttp 使用 Android Watch 协议进行登录。
4.6 启动 go-cqhttp,扫码并登录

- 注意事项
这个go-cqhttp 的扫码登录,是需要你自己的手机 QQ 和 go-cqhttp 在同一个网络环境下的才能成功的。
五. 最后按顺序启动
5.1 anaconda状态下的GLM api.py → go-cqhttp →GPT转发程序
5.1.1 qq成功页面

5.1.2 GPT转发程序成功页面

5.1.3 go-cqhttp成功页面
 文章来源:https://www.toymoban.com/news/detail-560942.html
文章来源:https://www.toymoban.com/news/detail-560942.html
5.1.4 GLM成功页面
 文章来源地址https://www.toymoban.com/news/detail-560942.html
文章来源地址https://www.toymoban.com/news/detail-560942.html
到了这里,关于GLM联合go-cqhttp实现qq群GLM机器人服务器的本地化部署笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!