简介
准备写个系列博客介绍机器学习实战中的部分公开项目。首先从初级项目开始。
本文为初级项目第三篇:利用NSE-TATA数据集预测股票价格。
项目原网址为:Stock Price Prediction – Machine Learning Project in Python。
第一篇为:机器学习实战 | emojify 使用Python创建自己的表情符号(深度学习初级)
第二篇为:机器学习实战 | MNIST手写数字分类项目(深度学习初级)
技术流程
项目构想:
机器学习在股票价格预测中具有重要应用。在这个机器学习项目中,我们将讨论预测股票价格。这是一项非常复杂的任务,并且具有不确定性。
我们将学习如何使用 LSTM 神经网络预测股票价格。
1. 载入依赖包
import matplotlib
matplotlib.use('Qt5Agg') # 防止画图时画图软件崩溃
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20, 10 # 设置画板尺寸
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense
from sklearn.preprocessing import MinMaxScaler
项目中主要用了pandas、sklearn、Keras和TensorFlow包,pandas和sklearn安装命令为:
pip install pandas
pip install scikit-learn
Keras和TensorFlow的安装命令为:
pip install keras==2.10.0
pip install TensorFlow==2.10.0
在最后输出结果的时候发现每次画图软件都崩溃导致程序中断,解决办法就是在前面加上这句话:matplotlib.use('Qt5Agg') ,防止画图时画图软件崩溃。
2. 读取数据集
df = pd.read_csv("NSE-TATA.csv") # 读取.csv文件
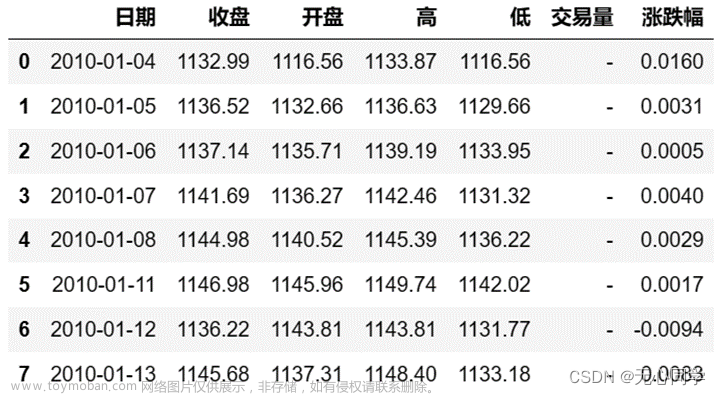
df.head() # 默认只读取dataframe数据表中前5行内容
为了构建股票价格预测模型,我们将使用 NSE-TATA数据集。这是来自印度国家证券交易所塔塔全球饮料有限公司的塔塔饮料数据集,官方网址可能不好下载,这里给出了数据集下载地址:NSE-TATA数据集。
- df.head():读取dataframe数据表,默认只读取dataframe数据表中前5行内容
3. 从数据集中分析价格
df["Date"] = pd.to_datetime(df.Date, format="%Y-%m-%d") # 将一个字符串解析为时间,并指定字符串的格式
df.index = df['Date']
plt.figure(figsize=(8, 4)) # 指定图片大小
plt.plot(df["Close"], label='Close Price history') # 绘图展示历史数据
- pd.to_datetime:将字符串解析为时间,并指定字符串的格式
- plt.plot: 绘图展示历史数据,绘图结果为:

4. 对数据排序
data = df.sort_index(ascending=True, axis=0) # 索引排序:默认按行从小到大
new_dataset = pd.DataFrame(index=range(0, len(df)), columns=['Date', 'Close']) # 创建新的数据集
for i in range(0, len(data)):
new_dataset["Date"][i] = data['Date'][i]
new_dataset["Close"][i] = data["Close"][i]
- df.sort_index:对数据进行排序,默认按照从小到大、按行排序
- pd.DataFrame:创建新的数据集,用object类保存数据。pandas(pd)数据类型,类似字典,可以直接按照名称、索引寻找数据。
5. 数据标准化
final_dataset = new_dataset.values # 读取新数据的数值
train_data = final_dataset[0:987, :]
valid_data = final_dataset[987:, :]
new_dataset.index = new_dataset.Date
new_dataset.drop("Date", axis=1, inplace=True) # 删除Date行头,只保留数据
scaler = MinMaxScaler(feature_range=(0, 1)) # 数据归一化,创建MinmaxScaler实例,归一化区间[0,1]
scaled_data = scaler.fit_transform(new_dataset) # 执行数据归一化操作,输出归一化后的数据
x_train_data, y_train_data = [], []
for i in range(60, len(train_data)):
x_train_data.append(scaled_data[i - 60:i, 0])
y_train_data.append(scaled_data[i, 0])
x_train_data, y_train_data = np.array(x_train_data), np.array(y_train_data)
x_train_data = np.reshape(x_train_data, (x_train_data.shape[0], x_train_data.shape[1], 1))
- drop:删除指定航头,只保留数据
- MinMaxScaler:sklearn.preprocessing.MinMaxScaler(),将数据归一化,创建实例,括号中表示归一化区间
- fit_transform:执行归一化操作,输入参数为待归一化数据
6. 创建、训练和保存LSTM网络
lstm_model = Sequential()
lstm_model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train_data.shape[1], 1)))
lstm_model.add(LSTM(units=50))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error', optimizer='adam')
lstm_model.fit(x_train_data, y_train_data, epochs=1, batch_size=1, verbose=2)
lstm_model.save("saved_model.h5")
经过机器学习实战初级项目第一课和第二课后,这段话就很好看懂了:编译-训练-保存权重的过程。输入参数细节这里就不再介绍了,下面只简单描述一下编译、训练和保存函数。
- complie: 编译神经网络结构,参数包括:loss,字符串结构,指定损失函数(包括MSE等);optimizer,表示优化方式(优化器),用于控制梯度裁剪;metrics,列表,用来衡量模型指标,表示评价指标。
- fit: 在搭建完成后,将数据送入模型进行训练。参数包括:
- x:训练数据输入;
- y:训练数据输出;
- batch_size: batch样本数量,即训练一次网络所用的样本数;
- epochs:迭代次数,即全部样本数据将被“轮”多少次,轮完训练停止;
- verbose:可选训练过程中信息是否输出参数,0表示不输出信息,1表示显示进度条(一般默认为1),2表示每个epoch输出一行记录;
- save: 保存训练模型权重,训练成功后,会在源目录下保存
saved_model.h5文件,即为权重文件。
7. 使用LSTM模型进行股票价格预测
inputs_data = new_dataset[len(new_dataset) - len(valid_data) - 60:].values
inputs_data = inputs_data.reshape(-1, 1)
inputs_data = scaler.transform(inputs_data)
X_test = []
for i in range(60, inputs_data.shape[0]):
X_test.append(inputs_data[i - 60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
predicted_closing_price = lstm_model.predict(X_test)
predicted_closing_price = scaler.inverse_transform(predicted_closing_price)
这段话的意思是首先筛选/构建测试数据集,保存在X_test中,接着利用predict函数对测试数据进行预测,预测结果保存在predicted_closing_price中。
- predict:利用训练好的模型权重lstm_model,对测试数据进行预测。
8. 可视化预测和实际结果
train_data = new_dataset[:987]
valid_data = new_dataset[987:]
valid_data['Predictions'] = predicted_closing_price
plt.plot(train_data["Close"])
plt.plot(valid_data[['Close', "Predictions"]])
plt.show()
将训练数据和测试数据画到一幅图中,同时展示股票预测结果和真实结果。
完整程序
train.py: 训练程序,输出结果saved_model.h5保存在项目源目录下。
"""
stock price prediction
"""
"""
1. imports
"""
import matplotlib
matplotlib.use('Qt5Agg') # 防止画图时画图软件崩溃
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20, 10 # 设置画板尺寸
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense
from sklearn.preprocessing import MinMaxScaler
"""
2. read the dataset
"""
df = pd.read_csv("NSE-TATA.csv") # 读取.csv文件
df.head() # 默认只读取dataframe数据表中前5行内容
"""
3. analyze the closing prices from dataframe
"""
df["Date"] = pd.to_datetime(df.Date, format="%Y-%m-%d") # 将一个字符串解析为时间,并指定字符串的格式
df.index = df['Date']
plt.figure(figsize=(8, 4)) # 指定图片大小
plt.plot(df["Close"], label='Close Price history') # 绘图展示历史数据
"""
4. sort the dataset on data time and filter "data" and "close" columns
"""
data = df.sort_index(ascending=True, axis=0) # 索引排序:默认按行从小到大
new_dataset = pd.DataFrame(index=range(0, len(df)), columns=['Date', 'Close']) # 创建新的数据集
for i in range(0, len(data)):
new_dataset["Date"][i] = data['Date'][i]
new_dataset["Close"][i] = data["Close"][i]
"""
5. normalize the new filtered dataset
"""
final_dataset = new_dataset.values # 读取新数据的数值
train_data = final_dataset[0:987, :]
valid_data = final_dataset[987:, :]
new_dataset.index = new_dataset.Date
new_dataset.drop("Date", axis=1, inplace=True) # 删除Date行头,只保留数据
scaler = MinMaxScaler(feature_range=(0, 1)) # 数据归一化,创建MinmaxScaler实例,归一化区间[0,1]
scaled_data = scaler.fit_transform(new_dataset) # 执行数据归一化操作,输出归一化后的数据
x_train_data, y_train_data = [], []
for i in range(60, len(train_data)):
x_train_data.append(scaled_data[i - 60:i, 0])
y_train_data.append(scaled_data[i, 0])
x_train_data, y_train_data = np.array(x_train_data), np.array(y_train_data)
x_train_data = np.reshape(x_train_data, (x_train_data.shape[0], x_train_data.shape[1], 1))
"""
6. build and train the LSTM model
"""
lstm_model = Sequential()
lstm_model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train_data.shape[1], 1)))
lstm_model.add(LSTM(units=50))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error', optimizer='adam')
lstm_model.fit(x_train_data, y_train_data, epochs=1, batch_size=1, verbose=2)
lstm_model.save("saved_model.h5") # save the LSTM model
"""
7. take a sample of a dataset to make stock price predictions using the LSTM model
"""
inputs_data = new_dataset[len(new_dataset) - len(valid_data) - 60:].values
inputs_data = inputs_data.reshape(-1, 1)
inputs_data = scaler.transform(inputs_data)
X_test = []
for i in range(60, inputs_data.shape[0]):
X_test.append(inputs_data[i - 60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
predicted_closing_price = lstm_model.predict(X_test)
predicted_closing_price = scaler.inverse_transform(predicted_closing_price)
"""
8. visualize the predicted stock costs with actual stock costs
"""
train_data = new_dataset[:987]
valid_data = new_dataset[987:]
valid_data['Predictions'] = predicted_closing_price
plt.plot(train_data["Close"])
plt.plot(valid_data[['Close', "Predictions"]])
plt.show()
运行后测试结果为:

该图中左侧黄色曲线表示训练数据,右侧红色曲线和绿色曲线分别表示股票价格真实结果和预测结果。
从图中可以看出, LSTM 预测股票价格与实际股票价格基本一致。文章来源:https://www.toymoban.com/news/detail-561284.html
如有问题,欢迎指出和讨论。文章来源地址https://www.toymoban.com/news/detail-561284.html
到了这里,关于机器学习实战 | 股票价格预测项目(深度学习初级)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!