ceph分布式存储—cephFS的使用
1、cephfs的概念
ceph FS 即 ceph filesystem,可以实现文件系统共享功能,客户端通过 ceph 协议挂载并使
用 ceph 集群作为数据存储服务器。
Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds
进程管理与 cephFS 上存储的文件相关的元数据,并协调对 ceph 存储集群的访问。
cephfs 的元数据使用的动态子树分区,把元数据划分名称空间对应到不同的 mds,写入元数
据的时候将元数据按照名称保存到不同主mds上,有点类似于nginx中的缓存目录分层一样.
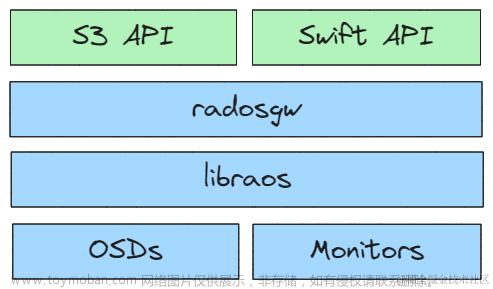
1.1 cephfs的架构图

2、部署MDS服务
2.1 下载部署cephfs(mds)服务的安装包
#在ceph-mgr1管理节点下载mds服务安装包
root@ceph-mgr1:~# apt-cache madison ceph-mds
root@ceph-mgr1:~# apt install ceph-mds
#在部署节点上创建mds服务
cephadmin@ceph-mon1:~/ceph-cluster$ ceph-deploy mds create ceph-mgr1
2.2创建cephFS metadata和data存储池
使用 CephFS 之前需要事先为集群创建一个文件系统,并为其分别指定元数据和数据相
关的存储池。
#创建存放文件元数据的存储池
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs-metadata 32 32
#创建存放文件数据的存储池
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs-data 64 64
#验证
cephadmin@ceph-mon1:~/ceph-cluster$ ceph osd pool ls
cephfs-metadata #存放元数据
cephfs-data #存放数据
2.3在部署节点上创建cephFS文件系统并验证
下面创建一个名为my cephfs 的文件系统用于测试,cephfs-metadata存储池为其存放文件的元数据
,cephfs-data存储池为其存放文件的数据.
#创建cephfs文件系统:mycephfs
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs new mycephfs cephfs-metadata cephfs-data
#列出当前Ceph集群中存在的文件系统
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs ls
name: mycephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
#当前Ceph元数据服务器(Metadata Server)的状态信息。它返回了与Ceph集群中正在运行的元数据服务器相关的详细统计数据。
(该命令会列出每个元数据服务器的编号、名称、所在的存储池、活动状态、操作数、目录数量等信息。通过运行ceph mds stat,你可以获得关于元数据服务器的实时状态,以便监视和诊断Ceph文件系统中的元数据服务情况。这对于故障排除和性能调优非常有用。)
#获取当前Ceph元数据服务器(Metadata Server)的状态信息
(该命令会列出每个元数据服务器的编号、名称、所在的存储池、活动状态、操作数、目录数量等信息。通过运行ceph mds stat,你可以获得关于元数据服务器的实时状态,以便监视和诊断Ceph文件系统中的元数据服务情况。这对于故障排除和性能调优非常有用。)
cephadmin@ceph-mon1:~/ceph-cluster$ ceph mds stat
mycephfs - 0 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr1 Reqs: 0 /s 15 17 13 10
POOL TYPE USED AVAIL
cephfs-metadata metadata 413k 569G
cephfs-data data 600M 569G
STANDBY MDS
MDS version: ceph version 16.2.13 (5378749ba6be3a0868b51803968ee9cde4833a3e) pacific (stable)
#参数详解如下:
mycephfs - 0 clients: 表示当前文件系统名称为"mycephfs",且没有客户端连接到该文件系统。
RANK: 元数据服务器的编号。
STATE: 元数据服务器的状态。在此示例中,元数据服务器0处于活动状态。
MDS: 元数据服务器名称。在此示例中,活动的元数据服务器名称为"ceph-mgr1"。
ACTIVITY: 元数据服务器的活动统计信息,包括每秒请求数(Reqs)等。在此示例中,平均每秒请求数为0。
DNS, INOS, DIRS, CAPS: 具体表示域名数(dentries)、索引节点数(inodes)、目录数和打开的文件描述符数。
POOL: 存储池名。
TYPE: 池的类型(metadata / data)。
USED, AVAIL: 用于表示存储池中已使用和可用的空间量。
STANDBY MDS: 表示有一个处于待命状态的元数据服务器。
MDS version: 表示Ceph集群中正在运行的元数据服务器软件版本
2.4 创建客户端账户
#创建账户
[ceph@ceph-deploy ceph-cluster]$ ceph auth add client.wsq mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data'
#验证账户
cephadmin@ceph-mon1:~/ceph-cluster$ ceph auth get client.wsq
[client.wsq]
key = AQDYZ65kIHuWGBAAdFExyLsWVzEQ+lyFyHcNpA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
exported keyring for client.wsq
#创建keyring文件
[ceph@ceph-deploy ceph-cluster]$ ceph auth get client.wsq -o ceph.client.yanyan.keyring
#创建key文件
[ceph@ceph-deploy ceph-cluster]$ ceph auth print-key client.wsq > wsq.key
#验证用户的keyring文件
cephadmin@ceph-mon1:~/ceph-cluster$ cat ceph.client.wsq.keyring
[client.wsq]
key = AQDYZ65kIHuWGBAAdFExyLsWVzEQ+lyFyHcNpA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
2.5 客户端安装ceph
root@ceph-client:~# apt update
root@ceph-client:~# apt install ceph-common -y
2.6同步客户端认证文件
[ceph@ceph-deploy ceph-cluster]$ scp ceph.conf ceph.client.wsq.keyring wsq.key root@172.17.10.69:/etc/ceph/
#客户端验证权限
root@ceph-client:~# ceph --user wsq -s
cluster:
id: 3bc181dd-a0ef-4d72-a58d-ee4776e9870f
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 8m)
mgr: ceph-mgr1(active, since 8m), standbys: ceph-mgr2
mds: 2/2 daemons up, 2 standby
osd: 9 osds: 9 up (since 8m), 9 in (since 22h)
data:
volumes: 1/1 healthy
pools: 3 pools, 97 pgs
objects: 93 objects, 200 MiB
usage: 679 MiB used, 1.8 TiB / 1.8 TiB avail
pgs: 97 active+clean
3、cephfs的使用方式
客户端挂载有两种方式,内核空间和用户空间,其中内核空间挂载需要系统内核支持ceph模块,用户空间挂载需要安装ceph-fuse
3.1 客户端使用内核空间挂载ceph-fs
3.1.1客户端通过key文件挂载
#挂载
root@ceph-client:~# mkdir /data
root@ceph-client:~# mount -t ceph 172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789:/ /data -o name=wsq,secretfile=/etc/ceph/wsq.key
#验证写入数据
root@ceph-client:~# dd if=/dev/zero of=/data/testfile bs=1M count=100
#设置开机自启动挂载
root@ceph-client:~# cat /etc/fstab
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda3 during curtin installation
/dev/disk/by-uuid/f570731e-f73a-4f9e-96a7-1648efb29cb8 / ext4 defaults 0 1
# /boot was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/f44ce411-83f2-4152-9e82-8334567a867d /boot ext4 defaults 0 1
172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789:/ /data ceph defaults,name=wsq,secretfile=/etc/ceph/wsq.key,_netdev 0 0
root@ceph-client:~# mount -a
#验证
root@ceph-client:~#reboot
root@ceph-client:~#df -Th
3.1.2客户端通过密钥key挂载
root@ceph-client:/etc/ceph# ll
total 24
drwxr-xr-x 2 root root 4096 Jul 13 12:36 ./
drwxr-xr-x 100 root root 4096 Jul 13 12:56 ../
-rw-r--r-- 1 root root 147 Jul 13 10:05 ceph.client.wsq.keyring
-rw-r--r-- 1 root root 354 Jul 13 09:44 ceph.conf
-rw-r--r-- 1 root root 92 Apr 19 23:37 rbdmap
-rw-r--r-- 1 root root 40 Jul 13 10:05 wsq.key
root@ceph-client:/etc/ceph# cat wsq.key
AQDYZ65kIHuWGBAAdFExyLsWVzEQ+lyFyHcNpA==
root@ceph-client:~# mount -t ceph 172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789:/ /data -o name=wsq,secret=AQDYZ65kIHuWGBAAdFExyLsWVzEQ+lyFyHcNpA==
#验证写入数据
root@ceph-client:~# dd if=/dev/zero of=/data/testfile bs=1M count=100
#设置开机自启动挂载
root@ceph-client:~# cat /etc/fstab
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda3 during curtin installation
/dev/disk/by-uuid/f570731e-f73a-4f9e-96a7-1648efb29cb8 / ext4 defaults 0 1
# /boot was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/f44ce411-83f2-4152-9e82-8334567a867d /boot ext4 defaults 0 1
172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789:/ /data ceph defaults,name=wsq,secret=AQDYZ65kIHuWGBAAdFExyLsWVzEQ+lyFyHcNpA==,_netdev 0 0
root@ceph-client:~# mount -a
#验证
root@ceph-client:~#reboot
root@ceph-client:~#df -Th
3.2用户空间挂载ceph-fs
如果内核版本比较低而没有ceph模块,那么可以安装ceph-fuse挂载,但是推荐使用内核模块挂载。
注意:我用的是ubuntu1804系统内核支持ceph.ko模块挂载cephfs文件系统故无需安装ceph-fuse
root@ceph-client:~# lsmod |grep ceph
ceph 380928 1
libceph 315392 1 ceph
fscache 65536 1 ceph
libcrc32c 16384 2 raid456,libceph
root@ceph-client:~# modinfo ceph
filename: /lib/modules/4.15.0-213-generic/kernel/fs/ceph/ceph.ko
license: GPL
description: Ceph filesystem for Linux #ceph文件系统
author: Patience Warnick <patience@newdream.net>
author: Yehuda Sadeh <yehuda@hq.newdream.net>
author: Sage Weil <sage@newdream.net>
alias: fs-ceph
srcversion: 7719B0A9AE35739551E438E
depends: libceph,fscache
retpoline: Y
intree: Y
name: ceph
vermagic: 4.15.0-213-generic SMP mod_unload modversions
signat: PKCS#7
signer:
sig_key:
sig_hashalgo: md4
#通过ceph-fuse挂载ceph
[root@ceph-client ~]# mkdir /data
[root@ceph-client ~]# ceph-fuse --name client.wsq -m 172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789 /data
ceph-fuse[1628]: starting ceph client
2021-06-08 10:51:24.332 7f5a3898ec00 -1 init, newargv = 0x556a48c77da0 newargc=7
ceph-fuse[1628]: starting fuse
[root@ceph-client2 ~]# vim /etc/fstab
none /data fuse.ceph ceph.id=yanyan,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0
[root@ceph-client2 ~]# mount -a
4、ceph mds高可用
4.1 ceph mds高可用的作用
ceph mds作为ceph的访问入口,需要实现高性能及数据备份,假设启动4个MDS进程,设置2个Rank。这时候有2个MDS进程会分配给两个Rank,还剩下2个MDS进程分别作为另外两个的备份。

设置每个 Rank 备份 MDS,也就是如果此 Rank 当前的 MDS 出现问题马上切换到另个
MDS。设置备份的方法有很多,常用选项如下。
mds_standby_replay:值为 true 或 false,true 表示开启 replay 模式,这种模式下主 MDS
内的数量将实时与从 MDS 同步,如果主宕机,从可以快速的切换。如果为 false 只有宕机
的时候才去同步数据,这样会有一段时间的中断。
mds_standby_for_name:设置当前 MDS 进程只用于备份于指定名称的 MDS。
mds_standby_for_rank:设置当前 MDS 进程只用于备份于哪个 Rank,通常为 Rank 编号。
另外在存在之个 CephFS 文件系统中,还可以使用 mds_standby_for_fscid 参数来为指定不
同的文件系统。
mds_standby_for_fscid:指定 CephFS 文件系统 ID,需要联合 mds_standby_for_rank 生
效,如果设置 mds_standby_for_rank,那么就是用于指定文件系统的指定 Rank,如果没有
设置,就是指定文件系统的所有 Rank。
4.2搭建MDS高可用
ceph-mgr2 和 ceph-mon1 和 ceph-mon2 作为 mds 服务角色添加至 ceph 集群,最后实两主两备的 mds 高可用和高性能结构
4.2.1 安装mds服务
注意:安装前要查看存储的状态和当前MDS服务的状态
#安装前的检查
cephadmin@ceph-mon1:~/ceph-cluster$ ceph -s
cluster:
id: 3bc181dd-a0ef-4d72-a58d-ee4776e9870f
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 67m)
mgr: ceph-mgr1(active, since 67m), standbys: ceph-mgr2
mds: 2/2 daemons up, 2 standby
osd: 9 osds: 9 up (since 67m), 9 in (since 23h)
data:
volumes: 1/1 healthy
pools: 3 pools, 97 pgs
objects: 93 objects, 200 MiB
usage: 679 MiB used, 1.8 TiB / 1.8 TiB avail
pgs: 97 active+clean
cephadmin@ceph-mon1:~/ceph-cluster$ ceph mds stat
#将分别在ceph-mon1、ceph-mon2、ceph-mon3安装mds服务
[root@ceph-mon1 ~]# apt install ceph-mds -y
[root@ceph-mon2 ~]# apt install ceph-mds -y
[root@ceph-mgr2 ~]# apt install ceph-mds -y
#在ceph-mon1部署节点上把mds服务器添加至ceph存储集群
[ceph@ceph-mon1 ceph-cluster]$ ceph-deploy mds create ceph-mgr2
[ceph@ceph-mon1 ceph-cluster]$ ceph-deploy mds create ceph-mon2
[ceph@ceph-mon1 ceph-cluster]$ ceph-deploy mds create ceph-mon1
#添加完成后验证mds服务器当前的状态
cephadmin@ceph-mon1:~/ceph-cluster$ ceph mds stat
mycephfs:1 {0=ceph-mgr1=up:active} 3 up:standby
#验证ceph集群当前状态
当前处于激活状态的mds服务器有一台,处于备份状态的mds服务器有三台
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs status
mycephfs - 2 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr1 Reqs: 0 /s 16 17 13 1
POOL TYPE USED AVAIL
cephfs-metadata metadata 445k 569G
cephfs-data data 600M 569G
STANDBY MDS
ceph-mon2
ceph-mgr2
ceph-mon1
MDS version: ceph version 16.2.13 (5378749ba6be3a0868b51803968ee9cde4833a3e) pacific (stable)
#查看当前的文件系统状态
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 108
flags 12
created 2023-07-12T08:32:08.110331+0000
modified 2023-07-13T06:24:40.794921+0000
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 141
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,7=mds uses inline data,8=no anchortable,9=file layout v2,10=snaprealm v2}
max_mds 2
in 0,1
up {0=114104,1=114103}
failed
damaged
stopped
data_pools [4]
metadata_pool 3
inline_data disabled
balancer
standby_count_wanted 1
[mds.ceph-mgr1{0:114104} state up:active seq 19 addr [v2:172.17.10.64:6800/118428332,v1:172.17.10.64:6801/118428332]compat {c=[1],r=[1],i=[7ff]}]
[mds.ceph-mon1{1:114103} state up:active seq 21 addr [v2:172.17.10.61:6800/3442732995,v1:172.17.10.61:6801/3442732995] compat {c=[1],r=[1],i=[7ff]}]
#设置处于激活状态mds的数量
目前有四个 mds 服务器,但是有一个主三个备,可以优化一下部署架构,设置为为两主两
备。
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs set mycephfs max_mds 2 #设置同时活跃的主mds最大值为2
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs status
mycephfs - 2 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr1 Reqs: 0 /s 16 17 13 1
1 active ceph-mon1 Reqs: 0 /s 10 13 11 1
POOL TYPE USED AVAIL
cephfs-metadata metadata 445k 569G
cephfs-data data 600M 569G
STANDBY MDS
ceph-mon2
ceph-mgr2
MDS version: ceph version 16.2.13 (5378749ba6be3a0868b51803968ee9cde4833a3e) pacific (stable)
5、MDS 高可用优化
目前的状态是 ceph-mgr1 和 ceph-mon1 分别是 active 状态,ceph-mon2 和 ceph-mgr2
分别处于 standby 状态,现在可以将 ceph-mgr2 设置为 ceph-mgr1 的 standby,将
ceph-mon2 设置为 ceph-mon1 的 standby,以实现每个主都有一个固定备份角色的结构,
则修改配置文件如下:
[ceph@ceph-deploy ceph-cluster]$ vim ceph.conf
[global]
fsid = 23b0f9f2-8db3-477f-99a7-35a90eaf3dab
public_network = 172.17.10.0/16
cluster_network = 192.168.10.0/24
mon_initial_members = ceph-mon1
mon_host = 172.17.10.61
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon clock drift allowed = 2
mon clock drift warn backoff = 30
mon_allow_pool_delete = true
osd pool default ec profile = /var/log/ceph_pool_healthy
[mds.ceph-mgr2]
#mds_standby_for_fscid = mycephfs
mds_standby_for_name = ceph-mgr1
mds_standby_replay = true
[mds.ceph-mon2]
mds_standby_for_name = ceph-mon1
mds_standby_replay = true
#分发配置文件并重启mds服务
#分发配置文件保证各 mds 服务重启有效
$ ceph-deploy --overwrite-conf config push ceph-mon1
$ ceph-deploy --overwrite-conf config push ceph-mon2
$ ceph-deploy --overwrite-conf config push ceph-mgr1
$ ceph-deploy --overwrite-conf config push ceph-mgr2
[root@ceph-mon2 ~]# systemctl restart ceph-mds@ceph-mon2.service
[root@ceph-mon1 ~]# systemctl restart ceph-mds@ceph-mon1.service
[root@ceph-mgr2 ~]# systemctl restart ceph-mds@ceph-mgr2.service
[root@ceph-mgr1 ~]# systemctl restart ceph-mds@ceph-mgr1.service
#验证
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs status
mycephfs - 2 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr1 Reqs: 0 /s 16 17 13 1
1 active ceph-mon1 Reqs: 0 /s 10 13 11 1
POOL TYPE USED AVAIL
cephfs-metadata metadata 445k 569G
cephfs-data data 600M 569G
STANDBY MDS
ceph-mon2
ceph-mgr2
MDS version: ceph version 16.2.13 (5378749ba6be3a0868b51803968ee9cde4833a3e) pacific (stable)
#查看active和standby对应关系
cephadmin@ceph-mon1:~/ceph-cluster$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 108
flags 12
created 2023-07-12T08:32:08.110331+0000
modified 2023-07-13T06:24:40.794921+0000
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 141
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,7=mds uses inline data,8=no anchortable,9=file layout v2,10=snaprealm v2}
max_mds 2
in 0,1
up {0=114104,1=114103}
failed
damaged
stopped
data_pools [4]
metadata_pool 3
inline_data disabled
balancer
standby_count_wanted 1
[mds.ceph-mgr1{0:114104} state up:active seq 19 addr [v2:172.17.10.64:6800/118428332,v1:172.17.10.64:6801/118428332]compat {c=[1],r=[1],i=[7ff]}]
[mds.ceph-mon1{1:114103} state up:active seq 21 addr [v2:172.17.10.61:6800/3442732995,v1:172.17.10.61:6801/3442732995] compat {c=[1],r=[1],i=[7ff]}]
6、通过ganesha将cephfs导出为NFS
通过 ganesha 将 cephfs 通过 NFS 协议共享使用。文章来源:https://www.toymoban.com/news/detail-561911.html
https://www.server-world.info/en/note?os=Ubuntu_20.04&p=ceph15&f=8文章来源地址https://www.toymoban.com/news/detail-561911.html
6.1服务端配置
root@ceph-mgr1:~# apt -y install nfs-ganesha-ceph
#修改配置文件
root@ceph-mgr1:~# cd /etc/ganesha/
root@ceph-mgr1:/etc/ganesha#
root@ceph-mgr1:/etc/ganesha# cat ganesha.conf
###################################################
#
# EXPORT
#
# To function, all that is required is an EXPORT
#
# Define the absolute minimal export
#
###################################################
NFS_CORE_PARAM {
# disable NLM
Enable_NLM = false;
# disable RQUOTA (not suported on CephFS)
Enable_RQUOTA = false;
# NFS protocol
Protocols = 4;
}
EXPORT_DEFAULTS {
# default access mode
Access_Type = RW;
}
EXPORT {
# uniq ID
Export_Id = 1;
# mount path of CephFS
Path = "/";
FSAL {
name = CEPH;
# hostname or IP address of this Node
hostname="172.17.10.64";
}
# setting for root Squash
Squash="No_root_squash";
# NFSv4 Pseudo path
Pseudo="/magedu";
# allowed security options
SecType = "sys";
}
LOG {
# default log level
Default_Log_Level = WARN;
}
EXPORT
{
# Export Id (mandatory, each EXPORT must have a unique Export_Id)
Export_Id = 77;
# Exported path (mandatory)
Path = /nonexistant;
# Pseudo Path (required for NFS v4)
Pseudo = /nonexistant;
# Required for access (default is None)
# Could use CLIENT blocks instead
Access_Type = RW;
# Exporting FSAL
FSAL {
Name = VFS;
}
}
6.2客户端挂载测试
root@ceph-client:/etc/ceph# mount -t nfs 172.17.10.64:/magedu /data/data-nfs/
root@ceph-client:/etc/ceph# df -Th
Filesystem Type Size Used Avail Use% Mounted on
udev devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs tmpfs 392M 13M 380M 4% /run
/dev/sda3 ext4 98G 6.3G 87G 7% /
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda2 ext4 9.8G 152M 9.1G 2% /boot
172.17.10.61:6789,172.17.10.62:6789,172.17.10.63:6789:/ ceph 570G 200M 570G 1% /data
tmpfs tmpfs 392M 0 392M 0% /run/user/0
172.17.10.64:/magedu nfs4 570G 200M 570G 1% /data/data-nfs
#验证
root@ceph-client: dd if=/dev/zero of=/data/data-nfs/test.file bs=1M count=100
root@ceph-client:/data/data-nfs# mkdir test
root@ceph-client:/data/data-nfs# ll
total 204802
drwxr-xr-x 4 nobody 4294967294 209715226 Jul 13 16:27 ./
drwxr-xr-x 1 root root 5 Jul 13 16:27 ../
drwxr-xr-x 2 nobody 4294967294 0 Jul 13 16:27 test/
-rw-r--r-- 1 nobody 4294967294 104857600 Jul 13 12:58 test.file
#验证
root@ceph-client: dd if=/dev/zero of=/data/data-nfs/test.file bs=1M count=100
root@ceph-client:/data/data-nfs# mkdir test
root@ceph-client:/data/data-nfs# ll
total 204802
drwxr-xr-x 4 nobody 4294967294 209715226 Jul 13 16:27 ./
drwxr-xr-x 1 root root 5 Jul 13 16:27 ../
drwxr-xr-x 2 nobody 4294967294 0 Jul 13 16:27 test/
-rw-r--r-- 1 nobody 4294967294 104857600 Jul 13 12:58 test.file
到了这里,关于ceph--cephFS的使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!