导模块
pip install scrapy-redis 原来scrapy的Scheduler维护的是本机的任务队列(待爬取的地址)+本机的去重队列(放在集合中)---》在本机内存中
如果把scrapy项目,部署到多台机器上,多台机器爬取的内容是重复的
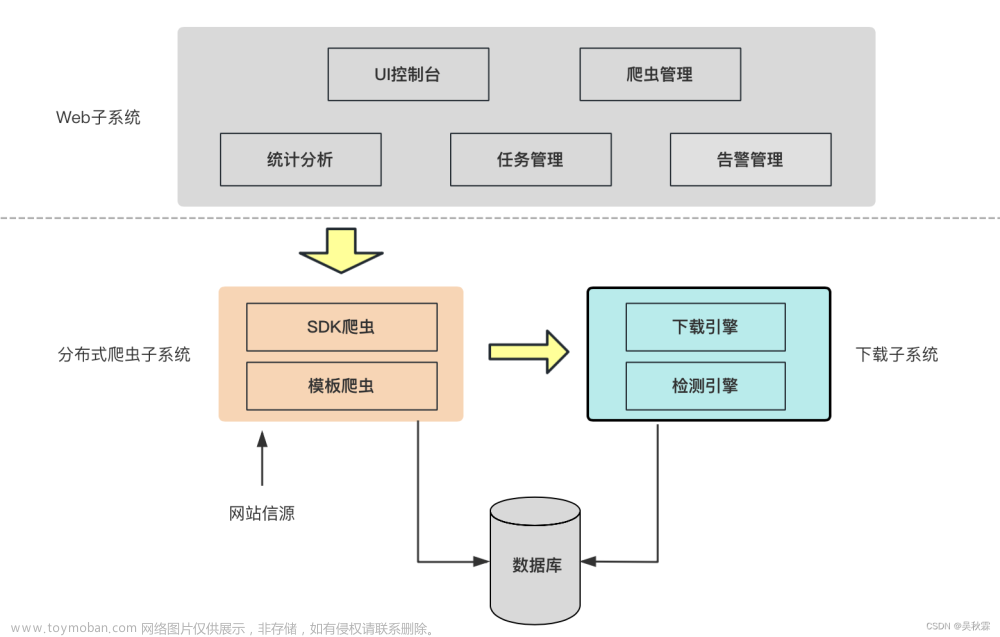
流程图

所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
#1、多台机器共享队列
#2、重写Scheduler,让其无论是去重还是任务都去访问共享队列
#3、为Scheduler定制去重规则(利用redis的集合类型)
# scrapy-redis实现分布式爬虫
-公共的去重
-公共的待爬取地址队列
使用步骤
from scrapy_redis.spiders import RedisSpider
1 把之前爬虫类,继承class CnblogsSpider(RedisSpider):
2 去掉起始爬取的地址,加入一个类属性
去掉它:start_urls = ["https://www.cnblogs.com"] #爬取的初始地址
redis_key = 'myspider:start_urls' # redis列表的key,后期我们需要手动插入起始地址
3 配置文件中配置
scrapy redis去重类,使用redis的集合去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
不使用原生的调度器了,使用scrapy_redis提供的调度器,它就是使用了redis的列表
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
ITEM_PIPELINES = {
# 'mysfirstscrapy.pipelines.MyCnblogsPipeline': 300,
'mysfirstscrapy.pipelines.MyCnblogsMySqlPipeline': 301,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 再不同多台机器上运行scrapy的爬虫,就实现了分布式爬虫
4.将初始爬取的地址传到redis队列中---cmd启动redis
lpush key value [value ...]key------就是第二步 redis_key对应的值
value--------就是爬取的地址初始地址文章来源:https://www.toymoban.com/news/detail-562062.html
分布式爬虫 - 刘清政 - 博客园 (cnblogs.com)文章来源地址https://www.toymoban.com/news/detail-562062.html
到了这里,关于scrapy ---分布式爬虫的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[爬虫]3.2.2 分布式爬虫的架构](https://imgs.yssmx.com/Uploads/2024/02/597077-1.jpg)