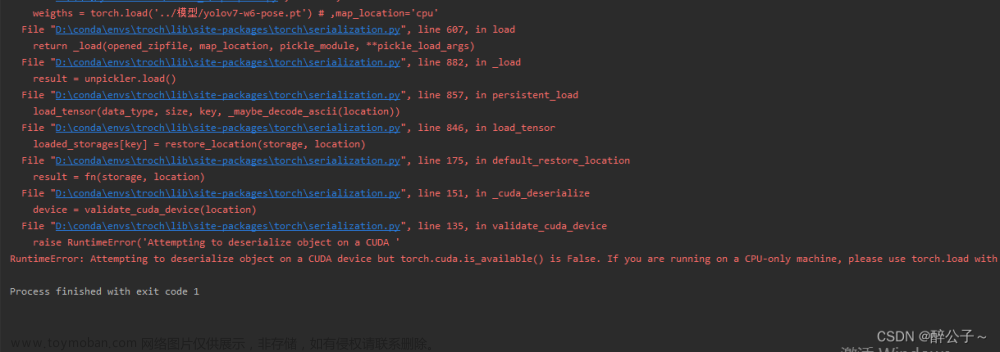
问题描述:
mobilenetv3在残差块中加入了注意力机制 用GPU 进行训练时报的错
解决方法1:
1,不用GPU 用CPU 就可以 CUDA 设置为False,确实可以解决,但是不用GPU 好像意义不大
解决方法2 :
用仍然用GPU ,看下面的的解决方案:
报错的原因:2
1,我直接在倒残差块的前向传播内对导入的注意力模块进行了实例化然后直接调用
错误范例

2,错误分析:参照这个链接得到启发原文链接:https://blog.csdn.net/qq_42902997/article/details/122594017
这个时候就会报错,而报错的原因,就是因为 torch 的流程是这样的:
首先将所有的模型加载,先从 主干网络 开始,进入主干网络的 init 中把所有的内容加载,然后,通过 main 函数中的 to(cuda) 操作,就把加载的所有内容和网络定义都放到 cuda 上了,但是注意!!
第二步开始训练,训练的过程中,都是通过 forward 函数来调用的,但是这个时候程序发现,当进入 主干的 forward 中运行的时候,出现了几个 注意力模块 的网络层,但是注意:这些 注意力模块中定义的网络层,在网络加载的过程中可是没有出现在 主干网络 的 __init__里面,也就理所当然地没有加载到 cuda上,因此在 主干网络 的 forward 中出现的时候,注意力模块的这几个网络层的 weight 依然在 cpu 上,这就导致了错误。
正确的解决方法
1,首先在_inti_里对导入的模块进行实例化,对于混合注意力机制可能不同阶段需要传入不同的通道参数和卷积核大小参数,这个时候应该用下图的方式分别对每类参数进行实例化定义,这个时候注意力模块就会和整个主干一起初始化,然后再一起传入到cuda上。就不会出现网络模型或者数据一部分在GPU一部分在CPU上了。
2,初始化定义好之后,就可以在forward里面调用了,调用范例
 文章来源:https://www.toymoban.com/news/detail-562166.html
文章来源:https://www.toymoban.com/news/detail-562166.html
这样就不会报错了文章来源地址https://www.toymoban.com/news/detail-562166.html
到了这里,关于RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!