| kafka-01 |
10.0.0.21 |
| kafka-02 |
10.0.0.22 |
| kafka-03 |
10.0.0.23 |
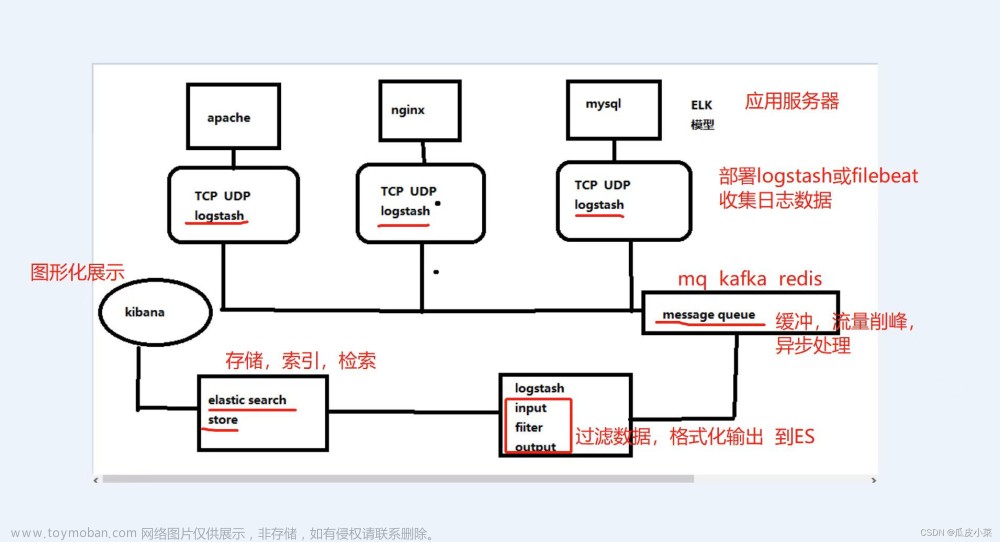
【1】安装zk集群、配置
[root@es-01 ~]# yum -y install java maven
[root@es-01 ~]# tar xf apache-zookeeper-3.5.9-bin.tar.gz -C /opt/
[root@es-01 ~]# cd /opt/apache-zookeeper-3.5.9-bin/conf/
[root@es-01 conf]# cp zoo_sample.cfg zoo.cfg
[root@es-01 conf]# vim zoo.cfg
# 服务器之间或客户端与服务器之间维持心跳的时间间隔。tickTime以毫秒为单位
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间的厨师连接心跳数 10* tickTime
initLimit=10
# 集群中的follower服务器于leader服务器之间请求和应答之间能容忍的最多心跳 5
syncLimit=5
# 数据保存目录
dataDir=../data
# 日志保存目录
dataLogDir=../logs
# 客户端连接端口
clientPort=2181
# 客户端最大连接数,默认是 60 个
maxClientCnxns=60
# 三个节点配置,格式为:server、服务编号=服务地址、LF通信端口、选举端口
server.1=10.0.0.21:2888:3888
server.2=10.0.0.22:2888:3888
server.3=10.0.0.23:2888:3888
[root@es-01 conf]# mkdir ../data
# 将配置好的zook 拷贝到其他两台节点中
[root@es-01 conf]# scp -rp /opt/apache-zookeeper-3.5.9-bin/ root@10.0.0.22:/opt
[root@es-01 conf]# scp -rp /opt/apache-zookeeper-3.5.9-bin/ root@10.0.0.23:/opt
# 在节点上写入节点标记
[root@es-01 conf]# echo "1" > /opt/apache-zookeeper-3.5.9-bin/data/myid
[root@es-02 ~]# echo "2" > /opt/apache-zookeeper-3.5.9-bin/data/myid
[root@es-03 ~]# echo "3" > /opt/apache-zookeeper-3.5.9-bin/data/myid
# 启动zook集群
[root@es-01 conf]# cd /opt/apache-zookeeper-3.5.9-bin/bin/
[root@es-01 bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# 检查集群状态,每个节点都要执行
[root@es-01 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@es-02 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@es-03 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.5.9-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
# 检查端口,leader(3888,2888)follower(3888)
[root@es-03 bin]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1963/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2027/master
tcp6 0 0 10.0.0.23:3888 :::* LISTEN 2518/java
tcp6 0 0 :::8080 :::* LISTEN 2518/java
tcp6 0 0 10.0.0.23:9200 :::* LISTEN 2281/java
tcp6 0 0 10.0.0.23:9300 :::* LISTEN 2281/java
tcp6 0 0 :::22 :::* LISTEN 1963/sshd
tcp6 0 0 ::1:25 :::* LISTEN 2027/master
tcp6 0 0 :::37308 :::* LISTEN 2518/java
tcp6 0 0 :::2181 :::* LISTEN 2518/java
tcp6 0 0 10.0.0.23:2888 :::* LISTEN 2518/java 【2】安装kafka集群
[root@es-01 ~]# tar xf kafka_2.12-2.8.1.tgz -C /opt/
[root@es-01 ~]# cd /opt/kafka_2.12-2.8.1/config/
[root@es-01 config]# vim server.properties
# broker的id,值为整数,且唯一,在一个集群中不能重复
broker.id=1
# kafka监听的端口,默认是9092
listeners=PLAINTEXT://10.0.0.21:9092
# 处理网络请求的线程数量,默认是3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认是8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接收数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认是100M
socket.request.max.bytes=104857600
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当leader的replication故障,会进行故障自动转移
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔1s
log.flush.interval.ms=1000
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每个多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
# zookeeper简介信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.21:2181,10.0.0.22:2181,10.0.0.23:2181
# 简介zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=60000
# 创建数据目录
[root@es-01 config]# mkdir ../data
# 将kafka拷贝至其他节点中
[root@es-01 config]# scp -rp /opt/kafka_2.12-2.8.1/ root@10.0.0.22:/opt/
[root@es-01 config]# scp -rp /opt/kafka_2.12-2.8.1/ root@10.0.0.23:/opt/
# 修改22、23配置文件中的broker.id 、listeners
[root@es-02 ~]# vim /opt/kafka_2.12-2.8.1/config/server.properties
# broker的id,值为整数,且唯一,在一个集群中不能重复
broker.id=2
# kafka监听的端口,默认是9092
listeners=PLAINTEXT://10.0.0.22:9092
......
[root@es-03 ~]# vim /opt/kafka_2.12-2.8.1/config/server.properties
# broker的id,值为整数,且唯一,在一个集群中不能重复
broker.id=3
# kafka监听的端口,默认是9092
listeners=PLAINTEXT://10.0.0.23:9092
......
# 启动kafka集群
[root@es-01 ~]# export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
[root@es-02 ~]# export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
[root@es-03 ~]# export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
[root@es-01 ~]# /opt/kafka_2.12-2.8.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.8.1/config/server.properties
[root@es-02 ~]# /opt/kafka_2.12-2.8.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.8.1/config/server.properties
[root@es-03 ~]# /opt/kafka_2.12-2.8.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.8.1/config/server.properties
[root@es-01 ~]# yum install java-1.8.0-openjdk.x86_64
[root@es-01 ~]# yum install java-1.8.0-openjdk-devel.x86_64
[root@es-01 ~]# jps
4456 Jps
4380 Kafka
3358 QuorumPeerMain
639 cerebro.cerebro-0.8.5-launcher.jar
# 验证集群
# 使用kafka创建一个topic
[root@es-01 bin]# /opt/kafka_2.12-2.8.1/bin/kafka-topics.sh --create --zookeeper 10.0.0.21:2181,10.0.0.22:2181,10.0.0.23:2181 --partitions 1 --replication-factor 3 --topic xiaocheng
# 生产者
[root@es-02 ~]# /opt/kafka_2.12-2.8.1/bin/kafka-console-producer.sh --broker-list 10.0.0.21:9092,10.0.0.22:9092,10.0.0.0.23:9092 --topic xiaocheng
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
[2023-07-13 07:04:02,171] WARN Couldn't resolve server 10.0.0.0.23:9092 from bootstrap.servers as DNS resolution failed for 10.0.0.0.23 (org.apache.kafka.clients.ClientUtils)
>hello
>你好?
# 消费者
[root@es-03 ~]# /opt/kafka_2.12-2.8.1/bin/kafka-console-consumer.sh --bootstrap-server 10.0.0.21:9092,10.0.0.22:9092,10.0.0.23:9092 --topic xiaocheng --from-beginning
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
hello
你好? 文章来源:https://www.toymoban.com/news/detail-562353.html
文章来源:https://www.toymoban.com/news/detail-562353.html
文章来源地址https://www.toymoban.com/news/detail-562353.html
到了这里,关于ELK-日志服务【kafka-配置使用】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!