1可选实验:使用Scikit-Learn进行线性回归
有一个开源的、商业上可用的机器学习工具包,叫做 scikit-learn。本工具包包含您将在本课程中使用的许多算法的实现。
1.1工具
您将利用 scikit-learn 以及 matplotlib 和 NumPy 中的函数。
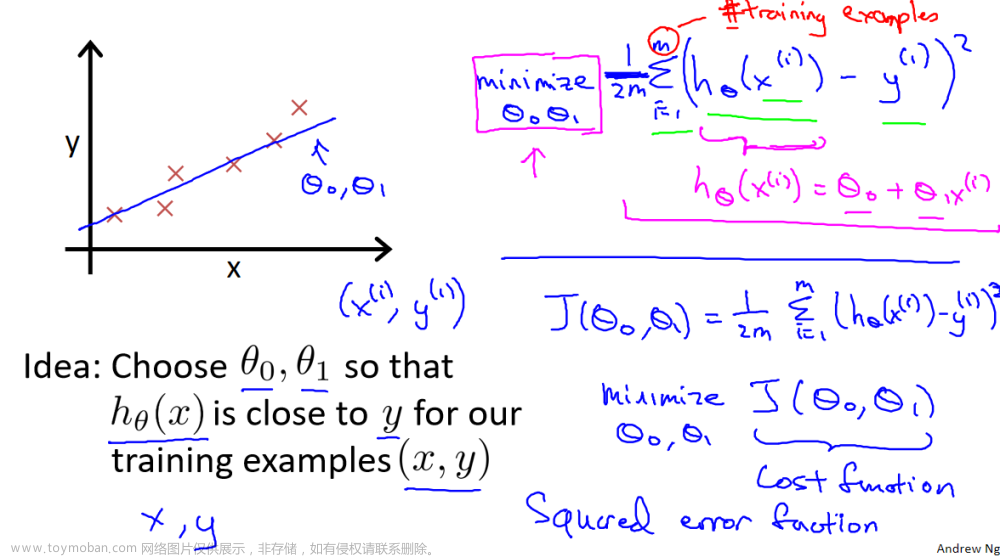
2线性回归封闭式解决方案
Scikit-learn 的线性回归模型实现了一种封闭式的线性回归。
让我们使用早期实验室的数据——一栋1000平方英尺的房子售价为30万美元,一栋2000平方英尺的房子售价为50万美元。
2.1载入数据集
import numpy as np
np.set_printoptions(precision=2)
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.preprocessing import StandardScaler
from lab_utils_multi import load_house_data
import matplotlib.pyplot as plt
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')
X_train = np.array([1.0, 2.0]) #features
y_train = np.array([300, 500]) #target value2.2创建并适应模型
下面的代码使用 scikit-learn 执行回归。
第二步利用与对象关联的方法之一 fit。这将执行回归,将参数拟合到输入数据。该工具包需要一个二维 X 矩阵。
linear_model = LinearRegression()
#X must be a 2-D Matrix
linear_model.fit(X_train.reshape(-1, 1), y_train) 输出:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
2.3参数视图
W 和 b 参数在 scikit-learn 中称为“系数”和“截距”。
b = linear_model.intercept_
w = linear_model.coef_
print(f"w = {w:}, b = {b:0.2f}")
print(f"'manual' prediction: f_wb = wx+b : {1200*w + b}")输出:
w = [200.], b = 100.00 'manual' prediction: f_wb = wx+b : [240100.]
2.4预测
调用predict函数生成预测。
y_pred = linear_model.predict(X_train.reshape(-1, 1))
print("Prediction on training set:", y_pred)
X_test = np.array([[1200]])
print(f"Prediction for 1200 sqft house: ${linear_model.predict(X_test)[0]:0.2f}")输出:
Prediction on training set: [300. 500.] Prediction for 1200 sqft house: $240100.00
3另一个实例
第二个例子来自一个早期的具有多个特性的实验室。最终的参数值和预测结果非常接近那个实验室的非标准化“长期运行”的结果。那次非正常化的运行花了几个小时才产生结果,而这几乎是瞬间的。封闭形式的解决方案在这样的小型数据集上运行良好,但是在大型数据集上可能需要计算。
闭式解决方案不需要规范化。文章来源:https://www.toymoban.com/news/detail-562449.html
# load the dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)
b = linear_model.intercept_
w = linear_model.coef_
print(f"w = {w:}, b = {b:0.2f}")
print(f"Prediction on training set:\n {linear_model.predict(X_train)[:4]}" )
print(f"prediction using w,b:\n {(X_train @ w + b)[:4]}")
print(f"Target values \n {y_train[:4]}")
x_house = np.array([1200, 3,1, 40]).reshape(-1,4)
x_house_predict = linear_model.predict(x_house)[0]
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.2f}")输出:文章来源地址https://www.toymoban.com/news/detail-562449.html
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
w = [ 0.27 -32.62 -67.25 -1.47], b = 220.42
Prediction on training set: [295.18 485.98 389.52 492.15] prediction using w,b: [295.18 485.98 389.52 492.15] Target values [300. 509.8 394. 540. ] predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = $318709.09
到了这里,关于吴恩达机器学习2022-Jupyter-用scikitlearn实现线性回归的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!