背景
秘鲁食品评论中的情绪和地理空间分析
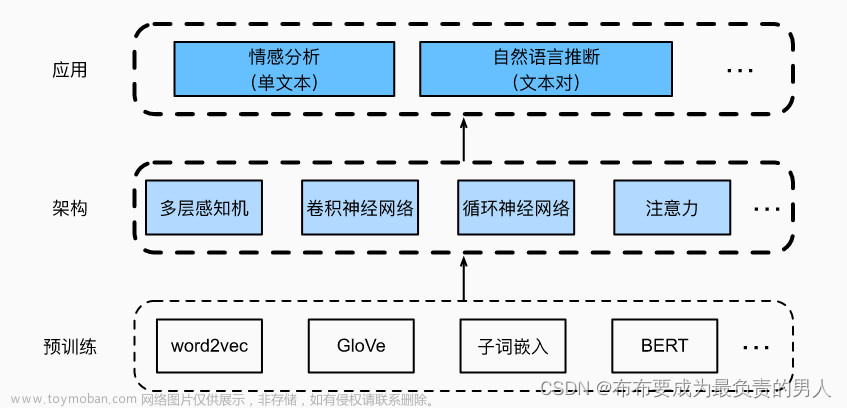
自然语言处理 (NLP) 是人工智能的一个分支,致力于让计算机能够像人类一样理解文本和口语单词。 另一方面,地理空间分析是对图像、GPS、卫星摄影和历史数据的收集、显示和操作,这些数据以地理坐标明确描述,或以街道地址、邮政编码或林分标识符隐式描述。 因为它们应用于地理模型。
关于这个话题,秘鲁是世界上最好、最独特的美食目的地之一。 这个国家有不同的气候和生态底线,种植了各种农作物。 这样一来,它就有了很多天然的、独特的投入。 因此,秘鲁菜是一种相反的菜系:同一盘中的热菜和冷菜。 酸味与淀粉混合。 坚固又精致。 一切都取得了优异的成绩。
关于 Kaggle 数据集,秘鲁美食评论有多种信息。 这具有文本、空间和时间特征! 这是展示有关情感分析、地理空间分析和时间序列分析的一些混合想法的好机会。 这里可能的用途是:市场研究、为客户创建指南应用程序。
思路示意
总的来说,我所做的项目是以下步骤:
网络数据提取:在 TripAdvisor 和 GoogleMaps 平台中使用网络抓取。
预处理:计算机应读取所有特征。 那里存在一组步骤。
探索性分析:一些初步绘图并初步了解数据。
聚类:评论可以按情感或情绪进行分类。 使用西班牙语 NrcLexicon 可以实现这一点。
分类:确定哪些评论是好的、差的或一般,以及发生这种情况的概率是多少。
报道:这些餐厅(或地区)都有独特的特色,并且很有趣地看到每个餐厅(或地区)的模式多样性。
仪表板:存在与用户交互的所有项目的摘要。
数据预处理
# GET DATA
# General data
reviews_df=pd.read_csv('../input/peruvian-food-reviews/data/data/reviews.csv')
reviews_df.dropna(subset=['review'],inplace=True)
reviews_df.drop_duplicates(subset=['review'],inplace=True,keep=False)
restaurants_df=pd.read_csv('../input/peruvian-food-reviews/data/data/restaurants.csv')
# Auxiliar data
borders=gpd.read_file('../input/peruvian-food-reviews/data/data/geospatial/districts.shp')
nrc=pd.read_csv('../input/peruvian-food-reviews/data/data/spanish-nrc/lexico_nrc.csv')
# PREPROCESSING
trans=str.maketrans('áéíóúüñÁÉÍÓÚÜ','aeiouunAEIOUU')
lemma_n={'limar':'lima','increiblemente':'increible','normalito':'normal','encantado':'encantar','lamentablemente':'lamentable','buenazo':'bueno','buenisimo':'bueno','buenisima':'bueno','zoolog':'zoo','abuelit':'abuel','malisimo':'malo','decepcion':'decepcio','decepcionado':'decepcio','decepcioado':'decepcio','decepcioante':'decepcio','riquisimo':'rico','recomendado':'recome','recomendacion':'recome','recomeir':'recome','recomer':'recome','recomendar':'recome','recomendarr':'recome','recomer':'recome','recomendarrr':'recome','recomendable':'recome','deliciosa':'delicia','delicioso':'delicia','delicios':'delicia','pesima':'pesimo','fria':'frio','atencion':'atender','comida':'comer','ambientar':'ambiente','venezuela':'venezolano','preciar':'precio','malisima':'malo'}
list_stopwords=list(set(stopwords_nltk+list(STOP_WORDS)+['\n','\t','nan','','aa',' ','q','pq','and','xd','xq']))
def remove_translate(x):
x=str(x)
if x.__contains__('(Traducción de Google)'): return x[len('(Traducción de Google)')+1:x.find('(Original)')]
else: return x
def create_lemma(x,dc):
if any(ext in x for ext in dc.keys()):
for k in dc.keys():
x=str(x).replace(k, str(dc[k]))
return x.replace('recome','recomendar').replace('ceviche','cebiche')
else: return x.replace('recome','recomendar').replace('ceviche','cebiche')
def preprocess_text(x):
try:
x=remove_translate(x)
x=x.lower()
x = re.sub('\[.*?¿\]\%', '', x)
x = re.sub('[%s]' % re.escape(string.punctuation), '', x)
x = re.sub('\w*\d\w*', '', x)
x = re.sub('[‘’“”…«»]', '', x)
x = re.sub('\n', ' ', x)
x=x.replace('<br>','').replace('</br>','')
x= [t.lemma_.lower().translate(trans) for t in nlp(x) if (not t.is_stop) &(t.text not in list_stopwords)]
x=' '.join(x)
return create_lemma(x,lemma_n)
except Exception as e: return ''
def get_entities(x):
try: return ' '.join([token.text for token in nlp(x) if (token.ent_type!=0) & (token.is_stop==False)])
except: return ''
def get_labels(x):
if x>3: return 'Excellent'
elif x<3: return 'Bad'
else: return 'Ok'
def translate_lg(x):
try: return detect(x)
except: return ' '
reviews_df['language']=reviews_df['review'].apply(translate_lg) #Is not precise
reviews_df=reviews_df[reviews_df['language']=='es']
reviews_df['label']=reviews_df['score'].apply(lambda x: 'Excellent' if x>3 else 'Bad' if x<3 else 'Ok')
reviews_df['pre_review']=reviews_df['review'].apply(preprocess_text)
#reviews_df['entity']=reviews_df['review'].apply(get_entities) In 1rst and 2nd version
reviews_df['date']=pd.Categorical(reviews_df['date'],categories=['1 months ago','2 months ago','3 months ago','4 months ago','5 months ago','6 months ago','7 months ago','8 months ago','9 months ago','10 months ago','11 months ago','12 months ago','1 years ago','2 years ago','3 years ago','4 years ago','5 years ago','6 years ago','7 years ago','8 years ago','9 years ago','10 years ago','11 years ago','12 years ago','13 years ago'],ordered=True)
def get_tags(df):
vectorizer=CountVectorizer(tokenizer = lambda x:[x.split('||', 1)[0].strip()])
mat=vectorizer.fit_transform(df.tag).toarray()
mat=pd.DataFrame(mat,columns=vectorizer.get_feature_names())
mat.drop(['','$', '$$ - $$$', '$$$$'],axis=1,inplace = True)
mat=pd.concat([df.id,mat],axis = 1)
mat.to_csv('./tag.csv',index=False)
#get_tags(restaurants_df) In 1rst and 2nd version
all_df=reviews_df.merge(restaurants_df,how='left',left_on='service',right_on='id')[['id_review', 'review', 'title', 'score', 'likes', 'id_nick', 'service','date', 'label', 'pre_review', 'id', 'name', 'tag','x', 'y', 'district', 'IDDIST']]
all_df.to_csv('./all.csv')
保存信息以便稍后使用:
全部:具有新功能的评论:预处理文本、实体检测、分数中的新标签以及与获取区域、x、y 和餐厅名称的餐厅的连接。
标签:餐厅类型。 他们销售什么产品?文章来源:https://www.toymoban.com/news/detail-563511.html
地理因素分析
def geo_map(df,dg,districts):
districts = districts[["IDDIST", "geometry"]].set_index("IDDIST")
map = Map(location=[-12.3101093,-76.8850579], tiles='Stamen Toner', zoom_start=9.2)
Choropleth(geo_data=districts.__geo_interface__,
data=df['stars'],
key_on="feature.id",
fill_color='Blues',
# legend_name="Satisfaction of restaurant's services in Lima by district"
).add_to(map)
HeatMap(data=zip(dg['x'], dg['y'],dg['n_reviews']), radius=30).add_to(map)
mc = MarkerCluster()
for idx, row in dg.iterrows():
html=f"""
<h1 style="color:DodgerBlue;"> <b> {row['name']} </b></h1>
<p> {row['stars']/10} estrellas </p>
<p> {row['n_reviews']} reseñas </p>
<p> {row['direction']} </p>
"""
popup = Popup(folium.IFrame(html=html, width=500, height=300), max_width=2650)
mc.add_child(Marker([row['x'], row['y']],color='red',popup = popup,icon=Icon(color='blue')))#
map.add_child(mc)
return embed_map(map,'./map.html')
def embed_map(m, file_name):
m.save(file_name)
return IFrame(file_name, width='100%', height='500px')
dgs=restaurants_df[restaurants_df['IDDIST']!='Out']
dg=dgs.groupby(by="IDDIST").mean()
ds=borders[borders['PROVINCIA']=='LIMA']
geo_map(dg,dgs,ds)


热图和红色刻度代表评论数量。
分区统计图和蓝色刻度代表各区的平均得分。
标记中餐厅的普遍化。
Pd:该地图可以适用于其他情况。 例如:分析 COVID-19 疫苗接种的进展,或者分析任何州的事故。文章来源地址https://www.toymoban.com/news/detail-563511.html
生成报告
class report:
def __init__(self,x,c,ids):
self.df=x
self.element=c
self.ids=ids
def generate_all(self):
for idx in self.ids:
print(f'Analyzing the {self.element} {idx}')
df=self.df[self.df[self.element]==idx]
self.get_score(df)
self.generate_wordcloud(df,idx)
self.get_reviews(df)
self.get_timeseries(df)
def get_reviews(self,df):
fill_color = []; n = len(df)
for i in range(n):
if df.iloc[i]['label']=='Excellent':fill_color.append('rgb(102, 178, 255)')
elif df.iloc[i]['label']=='Bad':fill_color.append("rgb(255, 102, 102)")
else:fill_color.append('rgb(153, 255, 204)')
fig = go.Figure(data=[
go.Table(columnorder = [1,2], columnwidth = [440,40],
header=dict(values=['<b>Reviews</b>', '<b>Score</b>'],
line_color='black', fill_color='black',
align='center',font=dict(color='white', size=12)),
cells=dict(values=[df.review, df.score],
line_color=['black']*2,fill_color=[fill_color,fill_color],
align='center', font=dict(color='black', size=11)))
])
fig.show()
def generate_wordcloud(self,df,save):
wordcloud = WordCloud(width=1640, height=1200,stopwords=set(stopwords.words('spanish')).union(set(['pre_review','Length','dtype','object','comida','comer','rico','atender','restaurante','servicio','plato','excelente','recomendar','delicia','ambiente','sabor','pedir','precio','agradable','local','calidad'])),
max_font_size=500,scale=3,random_state=60).generate(" ".join(df['pre_review'])) #Removing very common words in restaurants
wordcloud.recolor(random_state=1)
plt.figure(figsize=(25, 21))
plt.imshow(wordcloud)
plt.axis('off')
plt.savefig(f'./wordcloud_{save}.png')
plt.show()
def get_score(self,df):
dg=pd.DataFrame(df['score'].value_counts())
dg.sort_index(inplace=True)
dg.columns=['Number of reviews']
clrs=['red' if (x > dg['Number of reviews'].sum()/3) else 'lightcoral' for x in dg['Number of reviews'] ]
fig = go.Figure(data=[go.Bar(
x=['Stars_1','Stars_2','Stars_3','Stars_4','Stars_5'],
y=dg['Number of reviews'],
marker_color=clrs
)])
fig.show()
def get_timeseries(self,df):
dg=df.groupby(by="date").agg(['count', 'mean'])
dg.sort_index(inplace=True,ascending=False)
dg.dropna(inplace=True)
fig=go.Figure([go.Scatter(x=dg['score']['mean'].index, y=dg['score']['mean'].values)])
fig.update_layout(paper_bgcolor='rgba(0,0,0,1)', plot_bgcolor='rgba(0,0,0,1)',font=dict(size=10, color='#ffffff'),)
fig.show()
分析区域
report(all_df,'district',['MIRAFLORES','SANTIAGO DE SURCO']).generate_all()
分类
def model(c=1):
return Pipeline([('vect', CountVectorizer(analyzer = "word",min_df=20,stop_words = stopwords_nltk)),
('tfidf', TfidfTransformer(norm = 'l2',use_idf = True)),
('model', LogisticRegression(solver = 'newton-cg',max_iter = 1000,tol=1e-4,C = c))])
def training_cv(X_train,y_train,mod):
skf=StratifiedKFold(n_splits = 10,shuffle = True,random_state = 60)
yv=np.zeros(len(X_train))
yvs=np.zeros((len(X_train),5))
fi=pd.DataFrame(columns=[f"W_Class_{k}" for k in range(5)])
for fold,(idx_tr,idx_vl) in enumerate(skf.split(X_train,y_train)):
X_tr,y_tr=X_train.iloc[idx_tr],y_train.iloc[idx_tr]
X_vl,y_vl=X_train.iloc[idx_vl],y_train.iloc[idx_vl]
model = mod.fit(X_tr,y_tr)
fi = pd.DataFrame(model['vect'].get_feature_names(), columns = ["Features"])
for k in range(5): fi[f"W_Class_{k}"] = +pow(math.e, model['model'].coef_[k])
yv[idx_vl]=model.predict(X_vl)
yvs[idx_vl]=model.predict_proba(X_vl)
return yv,yvs,fi
def evaluation(yreal,y,ys):
print(classification_report(yreal, y))
print('AUC: ',roc_auc_score(yreal, ys, multi_class='ovo', average='weighted'))
print('Accuracy: ',accuracy_score(yreal, y))
print('Log_Loss: ',log_loss(yreal, ys))
plt.figure(figsize=(6,5))
sns.heatmap(pd.DataFrame(confusion_matrix(yreal, y)), annot=True, linewidths=.5, fmt="d")
plt.savefig('./confusion_matrix.png')
plt.show()
col=['red','orange','yellow','blue','green']
plt.figure(figsize=(7,6))
for k in range(5): sns.kdeplot(x=ys[:,k],fill=True,color = col[k])
plt.savefig('./distributions.png')
plt.show()
def model_weights(df):
# df["OddsRatio_4-3"] = df['W_Class_4']/df['W_Class_3']
print(df)
i,j=0,0
fig, axes = plt.subplots(nrows=2, ncols=3,figsize=(8,7))
for k in range(5):
df=df.sort_values(by = [f"W_Class_{k}"], ascending=False)
plt.subplot(2,3,k+1)
if j>2: i=1;j=0
df[:10].plot.barh(x='Features', y=f"W_Class_{k}",color='blue',ax=axes[i,j])
j=j+1
plt.savefig(f'feat_importance.png')
plt.show()
reviews_df.drop_duplicates(inplace=True,subset=['pre_review'])
reviews_df.reset_index(inplace=True)
yv,yvs,fi=training_cv(reviews_df['pre_review'],reviews_df['score'],model())
model_weights(fi)
evaluation(reviews_df['score'],yv,yvs)
dfx=pd.DataFrame({'stars_1':yvs[:,0],'stars_2':yvs[:,1],'stars_3':yvs[:,2],'stars_4':yvs[:,3],'stars_5':yvs[:,4]})
pd.concat([reviews_df['id_review'],dfx],axis=1).to_csv('./model.csv',index=False)
到了这里,关于kaggle学习笔记-情感和地理空间分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!