在之前的扩散模型介绍中,入门-1,主要考虑的是无条件下的图片生成,涉及到的问题主要是如何保证图片的质量,这个过程需要考虑很多的参数项,参数设定的不同会对图片的质量和多样性产生很大的影响。
能够让diffusion模型在工业界中大放异彩的模型,比如条件控制模型,是在diffusion模型的基础上改进起来的
我个人感觉这篇文章还挺有趣的
一般在想到控制生成的情况下,会考虑在原始的训练阶段中就加入控制语句,但这需要从头开始训练一个大模型。
另一种情况是在训练后,考虑加入控制语句,但再训练后怎么使用提示的方式达到控制生成的目的,效果很难改善。
这篇文章似乎是结合两种情况的折中方案,在保留大模型参数的情况下,还能够通过简单的微调达到模型更新的目的,进而实现条件控制生成。
1.简介
先猜一下,为神魔会有这种方案出来?我想是因为end-2-end的调优是比较简单快速,而且效果相较而言还能够接受的一种,但是,在LLM上的微调,参数规模太大了,很难有效的调整,又能够适应小游玩家,又能提高效率,在LLM中加入条件控制语句就成了一种方案。
文中还解释了一种场景,是在比较细节的调整中,比如人的姿势,如果使用prompt的方式的话,很难调整效果达到一个可接受的情况。
2.模型方法
在LLM的基础上,加入新的参数作为condition部分的参数,作为模型微调过程中更新的参数,以支持模型能够学习得到条件控制语句下的结果。
在操作上,将LLM的整个架构分为了几个模块,按照参数是否更新,将LLM的参数分为lock 和 unlock的两部分,对于unloack的部分,是在copy这一部分参数的条件下,来训练的。
lock 部分的参数是为了让模型能够保持大模型的能力,毕竟大模型是在上亿图片下的参数学习。train部分的参数是为了使模型学习得到条件下的控制结果。
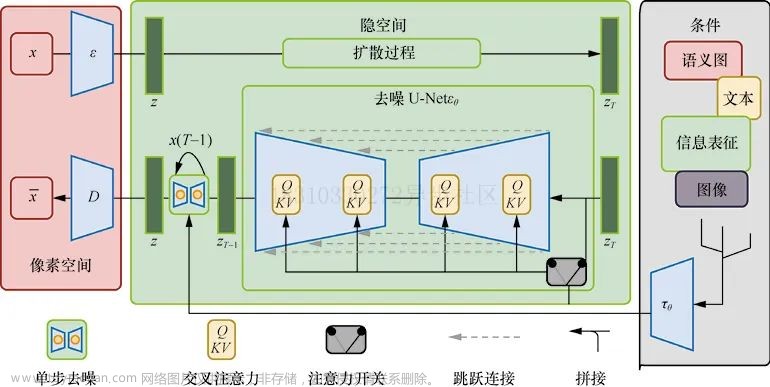
模型简图:
当ControlNet应用于某些神经网络块时,在任何优化之前,它不会对深度神经特征造成任何影响。当在反向传播时,尽管convolution的参数是0,但是y的参数不是0,所以,反向传导时,参数还是有更新的。权重会通过反向梯度下降,变为非0值。
2.1 相关模型方法上的其他研究
怎么在训练期间得到更好的初始化参数?——缩放扩散模型中几个卷积层的初始权重,以提高训练效果。还有一些是直接采用zero weights的方式作为卷积层的权重项。
其余的扩散模型有哪些在diffusion模型提出来后,对他的一些改进,比如Denoising Diffusion Probabilistic Model (DDPM) [17],Disco Diffusion,Denoising Diffusion Implicit Model (DDIM)等等模型。
这些是对于扩散模型的扩展。
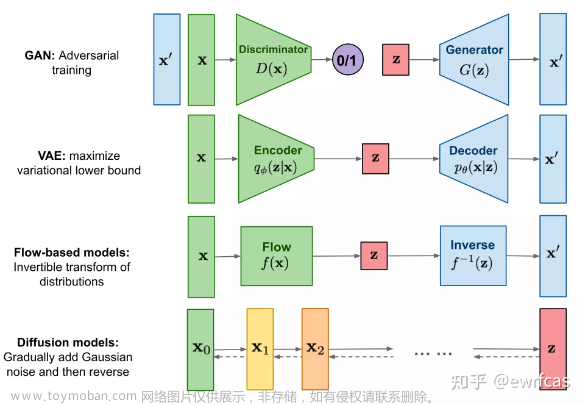
而对于其他的生成模型,还有VAE、GAN等等这些,它的历史发展逻辑如何??
2.2 control net在LLM上的应用实践
在下图中是LLM的decoder的block部分加入了control net模型。
在controlnet中使用了四个不同channel下的conv,将featuremap做了匹配对齐。
每个block可能由3个相同的size的block组成(X3)

3.实验效果
各种不同条件的数据集训练几个control net,例如,Canny边缘、Hough线、用户涂鸦、人类关键点、分割图、形状法线、深度等等。
在条件控制语中,考虑了no prompt,即空字符串的形式,
还有一种是default prompt,使用的是“a professional, detailed, high-quality image”
另外还有automatic prompts。
和user prompts 几种形式。文章来源:https://www.toymoban.com/news/detail-564362.html
4.总结与反思
controlnet的参数控制和另一种模型蒸馏好像有点关系,也是在模型中嫁梯子,达到最终的目标。
架梯子好像有点意思啊,可以多想想。文章来源地址https://www.toymoban.com/news/detail-564362.html
到了这里,关于条件控制生成——diffusion模型——Adding Conditional Control to Text-to-Image Diffusion Models的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!