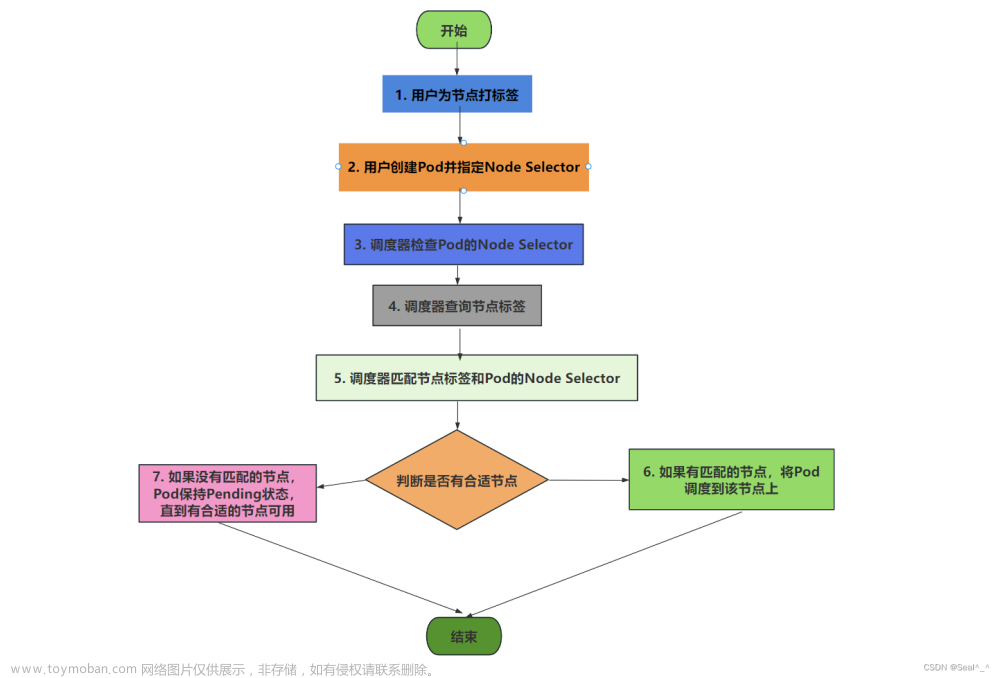
当您在Kubernetes中使用 kubectl delete pod 命令删除Pod,并在Pod的定义中指定了nodeSelector时,可能会出现“0/4 nodes are available”的错误。这是因为Kubernetes调度程序在找不到符合nodeSelector条件的节点时,会将Pod设置为挂起状态,直到可用节点出现为止。
要解决这个问题,您可以采取以下方案:
1. 检查nodeSelector条件是否正确
请确保您在Pod定义中设置的nodeSelector条件与集群中节点的标签匹配。您可以使用 kubectl get nodes --show-labels 命令查看节点的标签,并在Pod定义中使用正确的标签值。
2. 检查集群中是否有符合条件的节点
如果您的集群中没有符合nodeSelector条件的节点,则Pod将无法在集群中找到一个可用的节点,从而导致出现“0/4 nodes are available”的错误。您可以使用 kubectl get nodes --selector=<label> 命令查看是否有符合条件的节点。
3. 等待节点变为可用状态
如果您删除了一个Pod,并且在该节点上存在其他Pod,则需要等待其他Pod调度器将该节点上的其他Pod重新调度到其他节点上。当节点上没有其他Pod时,Kubernetes将使用该节点来调度新的Pod。
4. 调整节点资源分配
如果节点上的资源使用量已经接近或达到了其资源限制,Kubernetes将不会将新的Pod调度到该节点上。您可以通过调整节点的资源限制来解决这个问题。或者您可以通过添加新的节点来缓解节点资源限制的问题。文章来源:https://www.toymoban.com/news/detail-565969.html
综上所述,以上几种方案都可以帮助您解决“0/4 nodes are available”的问题。您可以根据实际情况选择其中一种或多种方案进行尝试。文章来源地址https://www.toymoban.com/news/detail-565969.html
到了这里,关于k8s重启Pod报错0/4 nodes are available的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!