Zookeeper的高度可靠性
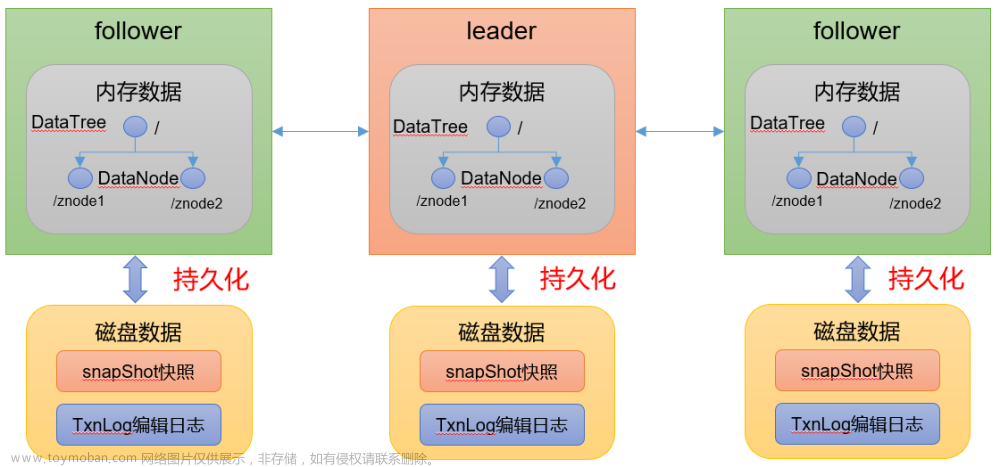
是一个分布式的系统,多个节点 并且节点中记录的数据是完全一致(一致性) , 当某个zk的节点宕机之后不会影响工作。因为Zookeeper的主节点不存在单点故障!Zookeeper的主节点是可以动态选举出来的!文章来源:https://www.toymoban.com/news/detail-566187.html
Zookeeper的选举机制(奇数台)
zookeeper的进程在不同的工作模式下,有不同的通信端口(比如选举时,通过端口3888通信;作为leader或者follower接收客户端请求时通过端口2181;leader和follower之间通信用2888)
zk集群安装的时候 会人为的为每台机器分配一个唯一的id
Leader选举过程(以3个节点的集群为例):文章来源地址https://www.toymoban.com/news/detail-566187.html
- 集群初次启动时的选举流程
- 第一台机器(id=1)启动,发现没有leader,进入投票模式,投自己,并收到自己投这一票,得1票,不能当选leader(当leader的条件是,集群机器数量过半的票数)
- 第2台机器(id=2)启动,发现没有leader,进入投票模式,投自己(因为自己的id>1 收到的另一台机器的票的id)
- 第1台机器收到2的票,发现集群中有一个比自己id大的机器上线了,重新投票,投id=2
- 第2台收到的得票数为2票,过半数,自己当选,切换模式:Leader模式
- 第1台就发现有Leader存在了,自己切换模式:Follower
- 第3台启动,发现有Leader,自动进入Follower状态
如果每个节点是同时启动的zk 同时选举自己 ,同时广播 , 同时获取别人的广播,3号机器会当选
- 集群在运行过程中的选举流程
- 在某个时间点上,id=2机器挂了(leader),别的机器发现没有leader了,全体进入投票模式
- 先投自己,票中会携带(自己的id,自己的数据的版本号)
- 大家都投数据版本最新的节点做leader,如果有多个节点数据版本一样,则从中选id最大的那个作为投票目标!
从上述投票机制可以看出:
Zookeeper集群的节点数最好配置为奇数!
Zookeeper集群的节点规模一般在3~5台就够!
到了这里,关于Zookeeper的选举机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!