一.为什么要有分区分配策略
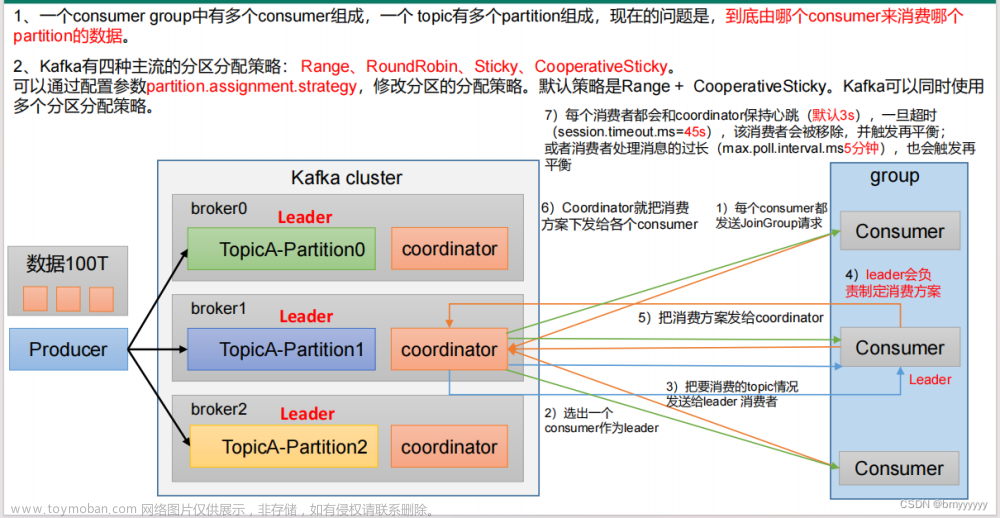
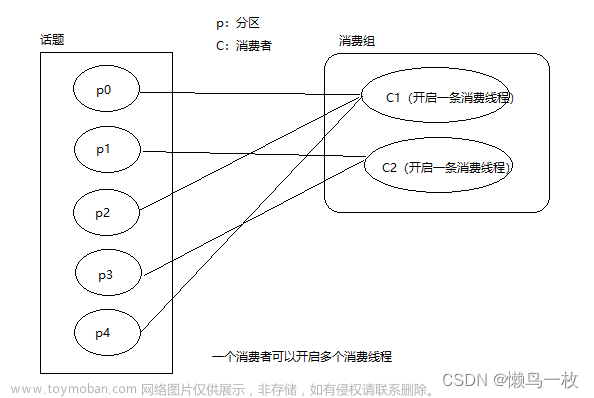
一个consumer group有多个consumer,一个topic有多个partition,所以就会设计到分区分配的问题,需要确定哪些分区由哪些消费者消费。
二.什么时候会执行分区分配策略
当消费者组中的消费者发生变化,减少或者增加的时候,就会执行分区分配策略,需要重新洗牌。
三.分区分配策略有哪些方案
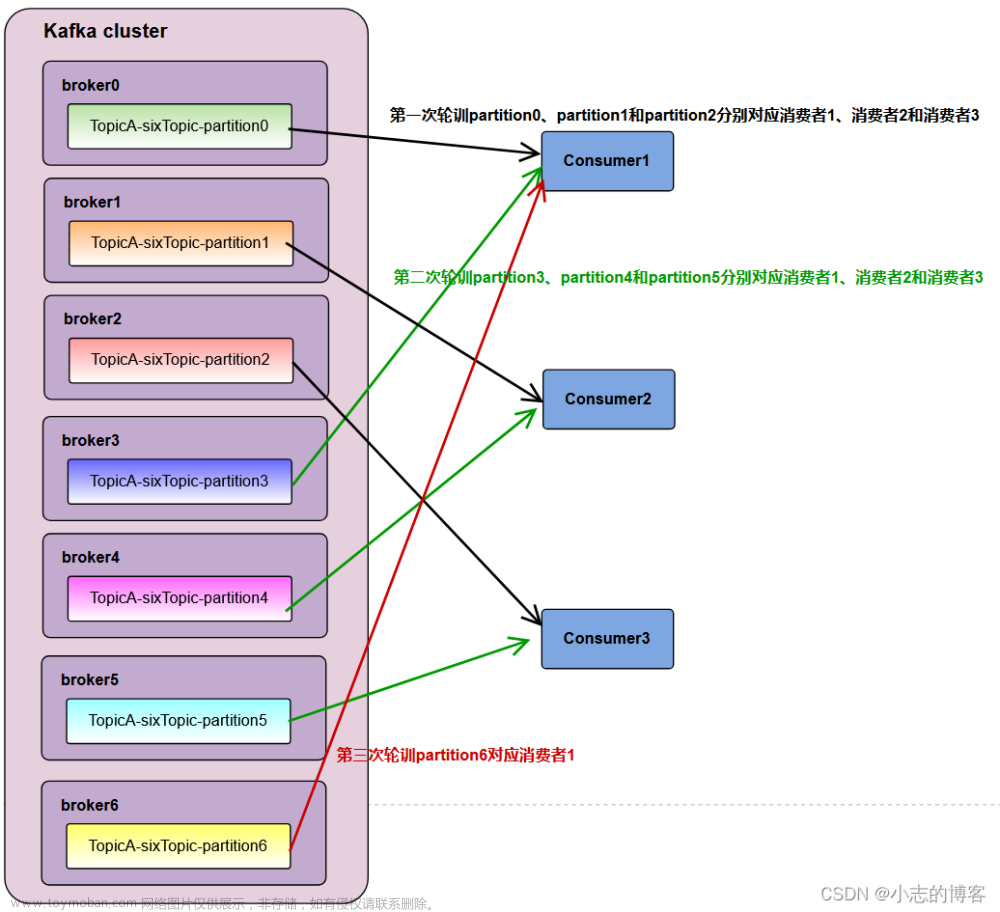
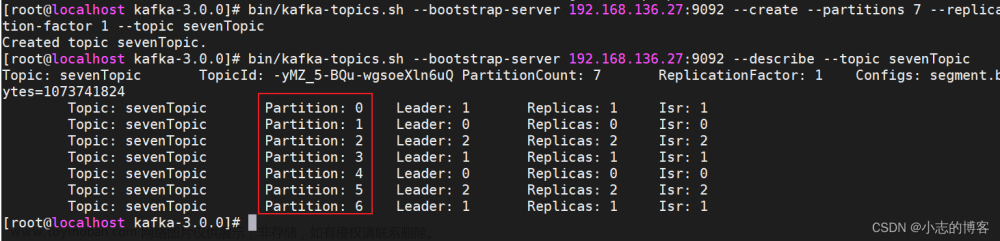
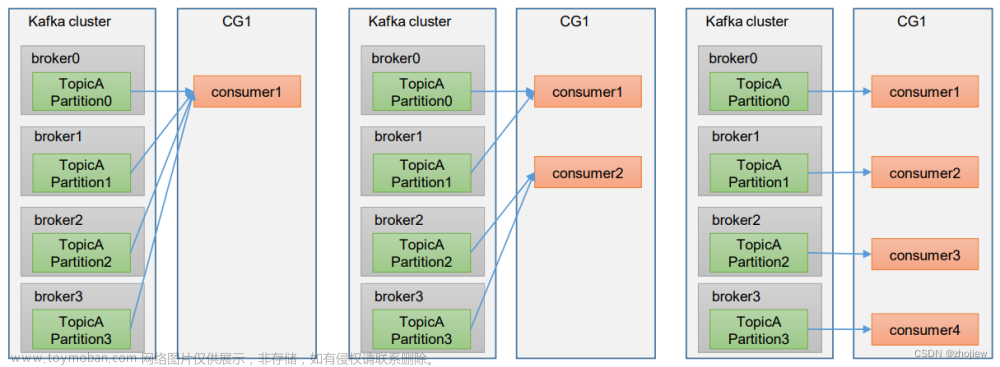
分区分配策略主要有两种,第一种是Range范围分区,按照主题划分的,是系统默认的方案。Range范围分区是针对每个topic而言。首先是把partition和consumer都拉出来分别进行排序,然后用partition的数量除以consumer的数量,以次来决定哪个范围的分区由哪个消费者消费,如果除不尽有出来的,那么前面的消费者都会多消费一个分区。如果topic很多的话,前面的消费者就会多很多分区,会造成消费者消费不对等,这就是Range分区的弊端。文章来源:https://www.toymoban.com/news/detail-567081.html
第二种是RoundRobin轮询分区。是按照消费者组划分的。首先是把所有主题的partition和consumer都列出来,算他们的hash值进行排序,最后通过轮询的算法将partition发给每个消费者。但是这个会有问题,比如一个消费者组中有A和B两个消费者,A想要消费topicA这个主题,B想要消费topicB这个主题,每个主题都有三个分区,通过轮询的方法把分区hash打散了,就会出现A消费了topicB,B消费了topicA的情况,会有问题。所以RoundRobin只适合每个消费者订阅的主题一致文章来源地址https://www.toymoban.com/news/detail-567081.html
到了这里,关于kafka消费者组的分区分配策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!