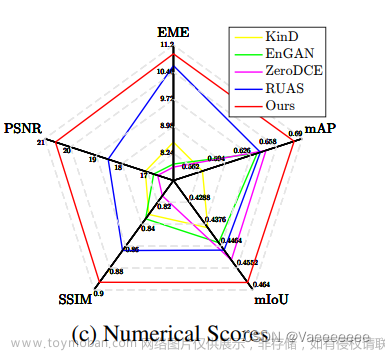
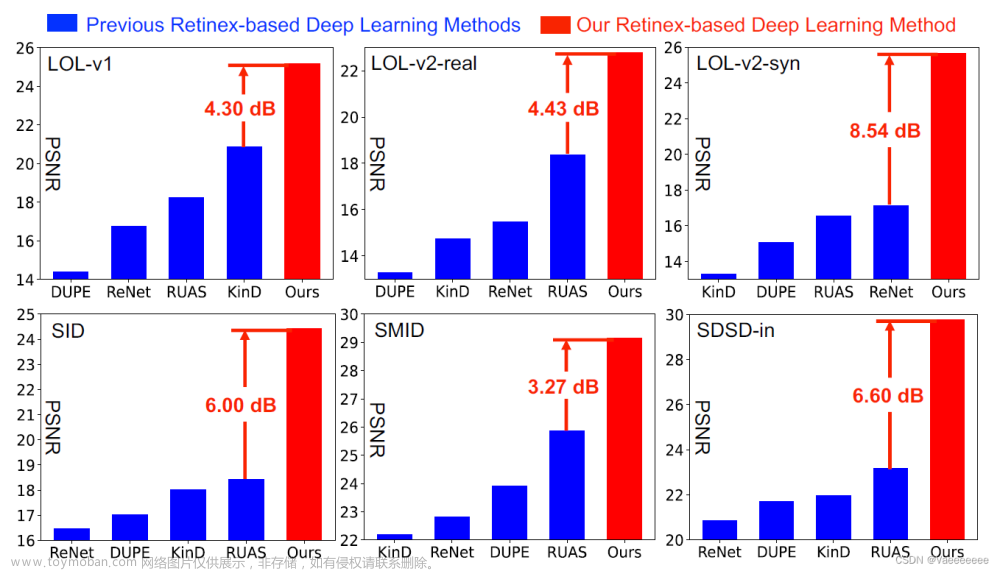
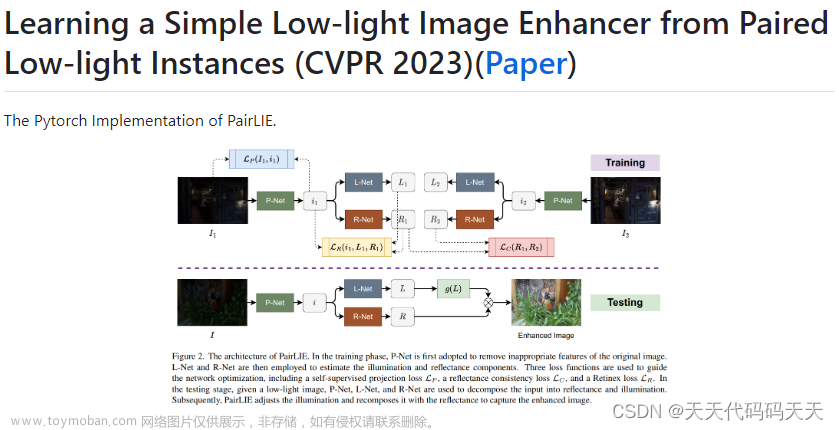
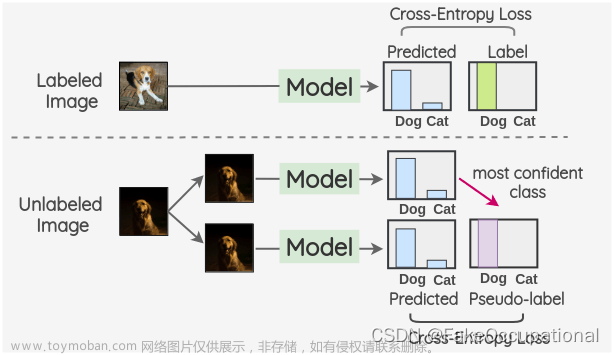
-
这是马龙博士2022年在TMM期刊发表的基于改进的retinex方法去做暗图增强(非深度学习)的一篇论文
-
文章用一张图展示了其动机,第一行是估计的亮度层,第二列是通常的retinex方法会对估计的亮度层进行RTV约束优化,从而产生平滑的亮度层,然后原图除以亮度层产生照度层作为增强结果,但通常这样会导致过曝,所以会把亮度层调大一点,比如第三列用了Gamma校正把亮度层调大,这样产生的结果不会过曝。但是文章指出无论是第三列的Gamma校正还是第四列的LIME,其调整亮度层的方法都会改变亮度层的形状导致产生伪影或者过模糊,从第二行可以看到,第三四列的蓝线相比绿线形状是发生了改变的。

-
但我个人觉得,retinex模型加RTV损失生成的亮度层估计又不是圣经,改变了又如何,并不是说retinex加RTV损失生成的亮度层就是最好的,如果发生了改变就一定变差。不过从可视化的效果来看,确实第五列的效果是要比第三四列的效果好的,不过也不一定就是第五列不改变亮度层形状导致的。
-
新的亮度层估计方法如下:


-
这里D其实就是一个类似 2 × 2 2\times2 2×2的max pooling操作,将每个像素值置为邻域的最大值(不包含-1,只向右看,有点类似求梯度的感觉,这一操作增强了边缘信息,如下图所示),然后加上c使得I的估计增大一个常量(相比gamma校正,这是一个平移而非对数,不过我觉得这个c等优化完再加上也是等价的,也就是说把c加在公式1的最右边)。而 φ \varphi φ是简化的RTV loss,原先的RTV Loss的权重是要对增强结果算的,现在对输入的暗图算就行。公式1的寻优用的是这篇论文(“Fast global image smoothing based on weighted least squares”)提出的1D Fast Global Smoother方法
-

上面只给出了如何根据 R t R^t Rt估计 I t + 1 I^{t+1} It+1,要实现迭代还需要根据 I t + 1 I^{t+1} It+1估计 R t + 1 R^{t+1} Rt+1,如下:
其实就是直接用 L L L除以 I I I,然后送进一个优化函数,如果不做去噪其实就仅仅是剪切到0-1之间
-
实际上,为了抑制噪声,胡使用给一个去噪网络 CBDNet来对照度层去噪,而且用预训练好的模型即可,无需重新训练。由于前面公式中 c c c增量的引入,估计出来的 R R R直接可以当作增强结果,无需用gamma校正来调节 I I I再计算 R R R
-
实验结果可以看到,指标和可视化效果都挺不错的,对过曝区域也能避免过增强:



-
消融实验可以看到迭代次数是5就已经收敛了,用CBDNet进行denoising的效果也很好:
 文章来源:https://www.toymoban.com/news/detail-567615.html
文章来源:https://www.toymoban.com/news/detail-567615.html
 文章来源地址https://www.toymoban.com/news/detail-567615.html
文章来源地址https://www.toymoban.com/news/detail-567615.html
- 运行速度也很快:

- 甚至还能去雾:


- limitation是blocking artifacts

- 这是篇各方面都很牛逼的论文,用非深度学习的方法把深度学习方法给比了下去,并且速度也不输。虽然还是依赖深度学习的CBDNet来去噪。但是文章提出用全局的增量而非gamma校正来进行亮度层的增加可以获得比原有基于gamma校正更好的结果让我有点惊讶,而由于全局增量导致的对比度增强不足问题,也通过一个照度层的max操作把边缘给突出出来。从实验结果看在很暗的图上的增强结果并没有想象中的出现对比度不足问题,后续可以再进一步实验看看,怀疑对比度这么容易就处理好了吗。
到了这里,关于Low-Light Image Enhancement via Self-Reinforced Retinex Projection Model 论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!