起因
我们在写脚本的时候,经常是单线程跑完了全部,毕竟自顶向下按照我们约定的方法运行下去是最规范的。但是很多时候,比如说合法地爬取一些网页信息,图片和资料啊,或者说一些合法的网络请求,读写文件之类的。如果还是单线程地one by one,那么将会影响我们的效率。这时候多线程就应运而生了,我们如果能够用多线程异步地做一些工作,就不会被一件事情阻塞等待着了。
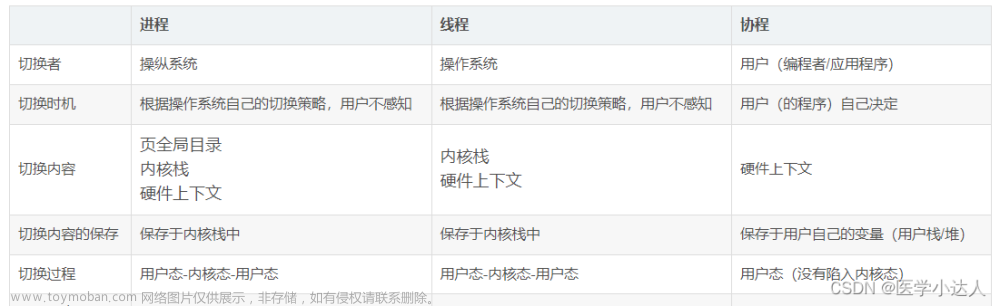
什么是多线程
在了解什么是多线程之前,我们需要先了解线程。线程,是程序执行时的最小单位,是CPU调度和分配的基本单位。
多线程是指在单个程序中同时执行多个任务的过程,每个任务被称为一个线程。在一个多线程程序中,每个线程都可以独立地运行,直到它们被中断或手动停止。
多线程的好处是,它能够充分利用多核处理器的优势,提高程序的执行效率。同时,多线程也能够使程序更加灵活,可以根据不同的任务需求来分配不同的线程,从而更好地满足用户的需求。
Python多线程
示例和实现
在 Python 中,使用多线程可以通过 threading 模块来实现。threading 模块提供了一系列的线程操作函数,包括创建线程、启动线程、停止线程等等。使用这些函数,我们可以轻松地编写一个多线程程序。
例如,定义一个 printtime 函数,该函数打印当前线程的名称和时间,并睡眠 2 秒。然后创建两个线程分别执行 printtime 函数,代码如下:
import threading
import time
def print_time(thread_name, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print("%s:%s" % (thread_name, time.ctime(time.time())))
try:
thread1 = threading.Thread(name="t1", target=print_time, args=("Thread-1", 2))
thread1.start()
thread2 = threading.Thread(name="t2", target=print_time, args=("Thread-2", 2))
thread2.start()
except OSError as e:
print("Error: unable to start thread")
上面代码中,我们定义了一个 print_time 函数,该函数打印当前线程的名称和时间,并睡眠 2 秒。然后我们创建了两个线程,分别执行 print_time 函数。在执行过程中,两个线程会交替打印线程名称和时间,并在每次打印后睡眠 2 秒。这样就实现了多线程的并发执行。
存在问题
Python中虽然提供了多线程,但是并不能提升效率。因为 Python 的全局解释器锁(GIL)限制了多个线程同时执行。GIL 是一个互斥锁,它确保任何时候只有一个线程在解释器中运行。这意味着,尽管有多个线程,但只有其中一个线程在执行,而其他线程必须等待该线程释放 GIL 后才能执行。
因此,在 Python 中使用多线程并不能真正实现并行计算,因为它们不能同时执行。相反,Python 中的多线程主要用于实现并发 I/O 操作,例如在多个线程中同时读取和写入数据。在这种情况下,多个线程可以同时执行,因为它们不会相互干扰。
如果需要提高 Python 程序的效率,可以考虑使用多进程而不是多线程。Python 的多进程可以使用多个进程同时执行,从而实现并行计算。但是,多进程也会带来一些额外的开销,例如进程间通信的开销,因此需要根据具体情况权衡使用多进程还是多线程。
协程
如果只是为了实现并发问题,可以尝试一下使用Python的协程。
Python 中的协程是一种比线程更轻量级的并发编程方式。协程可以暂停和恢复执行,而不需要切换到其他线程,因此比线程更加高效。协程的执行是在一个线程中进行的,因此不需要多线程的锁机制,也不需要考虑线程间的同步问题。
在 Python 中,协程可以通过asyncio模块来实现并发控制:
import asyncio
async def coroutine():
print("Coroutine is starting")
await asyncio.sleep(1)
print("Coroutine is ending")
async def main():
await asyncio.gather(*[coroutine() for _ in range(5)])
print("Main is ending")
asyncio.run(main())
在上面的代码中,coroutine() 函数是一个协程,它打印出 "Coroutine is starting",然后暂停执行 1 秒,最后打印出 "Coroutine is ending"。main() 函数是一个异步函数,它使用 asyncio.gather() 函数来启动多个 coroutine() 协程,并等待它们全部完成。
asyncio.gather() 函数是一个异步函数,它等待指定数量的协程完成。在上面的代码中,我们使用了 coroutine() 协程 5 次,并通过 asyncio.gather() 函数来等待它们完成。
最后,main() 函数打印出 "Main is ending",表示程序执行完毕。
然而,Python 协程也存在一些缺点。首先,协程无法利用多核资源,因为它的本质是个单线程,它不能同时将单个 CPU 的多个核用上。协程需要和进程配合才能运行在多 CPU 上。其次,进行阻塞(Blocking)操作(如 IO 时)会阻塞掉整个程序。
多进程
因为协程只是共享线程,如果要使用多核CPU,那就需要多进程来实现。
多进程是指在计算机中同时运行多个进程(Process),每个进程都有自己独立的内存空间和系统资源。多进程可以利用多核 CPU 的性能,从而提高程序的执行效率。
在 Python 中,可以使用 multiprocessing 模块来实现多进程。multiprocessing 模块提供了一个跨平台的多进程支持,可以使用 Process 类来创建新进程,并通过 join() 方法来等待进程完成。如下面代码所示:
import multiprocessing
def worker(name):
print(f"{name} is running")
if __name__ == '__main__':
p1 = multiprocessing.Process(target=worker, args=('1',))
p2 = multiprocessing.Process(target=worker, args=('2',))
p1.start()
p1.join()
p2.start()
p2.join()
在上面的代码中,我们定义了一个 worker() 函数,它接受一个名字参数,并打印出该名字。在 main 模块中,我们创建了两个进程,分别传递了名字 "1" 和 "2" 给 worker() 函数。然后,我们使用 start() 方法来启动进程,并使用 join() 方法来等待进程完成。通过运行程序后,我们可以看到程序同时运行了两个进程,并分别打印出了 "Process 1" 和 "Process 2"。这展示了如何在 Python 中使用多进程来提高程序的执行效率。
Python的多进程可以利用多核 CPU 的性能,提高程序的运行效率。也可以并行处理多个任务,提高程序的处理能力。还可以利用进程间的隔离性,避免一个任务失败导致整个程序崩溃。但是对于多进程来说,创建和维护进程需要消耗系统资源,导致程序的运行效率降低。进程间的通信和同步需要开发者手动处理,增加编程的复杂度。进程间的状态和变量无法共享,导致程序的编写更加复杂。
分布式
有时候对于计算复杂的程序,我们使用多核并行依旧无法达到我们所需要的效果,多台机器共同计算就成了我们的备选项。分布式就是一种很好地方式。
分布式系统是由多个计算机或节点组成的系统,这些节点可以通过网络连接互相通信和协作完成任务。在分布式系统中,节点可以分布在不同的地理位置,也可以是同一台计算机上的不同进程或线程。分布式系统的目的是通过协作来完成一个或多个共同的任务,以实现高性能、可靠性、可扩展性和容错性等特点。
分布式计算是指将一个计算任务分解为多个子任务,由多个节点同时执行,以提高计算速度和处理能力。Python 中的分布式编程是指利用多台计算机或多个进程来协同完成任务的过程。在 Python 中,可以使用multiprocessing模块来实现多进程分布式编程,该模块提供了一个跨平台的多进程支持,可以使用Process类来创建新进程,并通过join()方法来等待进程完成。
map reduce
分布式中比较出名的是MapReduce,它是一种编程范式,是基于 Hadoop 的大数据分布式计算方法。MapReduce 分为 map 和 reduce 两个步骤。map 阶段将数据分成多个块,每个块都由一个 Mapper 处理,Mapper 将每个块转换为一个中间结果。reduce 阶段将所有 Mapper 的中间结果汇总起来,由一个 Reducer 进行处理,Reducer 将中间结果转换为最终结果。
MapReduce 的优点是它具有良好的可扩展性和容错性。由于 MapReduce 将数据分成多个块,因此可以很容易地在多台计算机上并行处理。如果其中一台计算机出现故障,任务可以将故障计算机的数据转移到其他计算机上,从而保证系统的可用性。
MapReduce 的缺点是它不适合处理交互式数据。由于 MapReduce 是一种批处理计算模型,因此它不适合处理实时数据或交互式查询。因此,如果当前的计算任务之间无需交互,只需要配置好集群,每次将需要计算的数据和程序发布到子系统中进行计算,再将结果收回,便能够很好地实现分布式计算。
Python 中的 MapReduce 可以使用内置的map()和reduce()函数来实现。MapReduce 是一种将数据分成多个块,每个块都由一个 Mapper 处理,然后将所有 Mapper 的输出汇总到一个 Reducer 中进行处理的编程范式。
下面使用一个简单的 Python 代码示例,调用了python自带的map和reduce,用于演示如何使用 MapReduce 对一个列表进行操作:
from functools import reduce
def map_function(input_data):
return input_data * 2def reduce_function(fir, sec):
return fir + sec
mapper = map_function
reducer = reduce_function
numbers = [1, 2, 3, 4, 5]
output = list(map(map_function, numbers))
print(output)
output = result = reduce(reduce_function, output)
print(output)
在这个示例中,我们定义了一个map_function函数,它接受一个输入数据,并返回输入数据的两倍。我们还定义了一个reduce_function函数,它接受一个中间数据列表,并返回所有元素的和。
这个示例演示了如何在 Python 中使用 MapReduce 编程范式,但它只是一个简单的示例。在实际应用中,MapReduce 通常用于处理大型数据集,并在分布式系统上运行。
Ray框架
由于map reduce的编程范式过于粗粒度,而很多情况下需要更细粒度地进行分布式计算,比如在数据处理或者机器学习计算的过程中,往往速度会被性能最差的那个子节点给拖累了。而如果自己手动进行分布式配置,使用Multiprocessiong的方式手动处理,这样又有很多细节问题需要处理。这是还还是用一个完整的框架吧。
Ray 是一个用于分布式 Python 应用程序的开源框架,它提供了一种简单、灵活且高效的方式来构建和部署大规模数据处理和机器学习应用程序。Ray 由 Facebook AI Research 开发,旨在为开发者提供一种简单、统一的方式来处理大规模数据和模型,并支持多种编程语言和算法。
Ray 的主要特点包括:
1. 分布式计算:Ray 提供了一种跨多个节点执行计算的任务调度机制,可以自动处理数据并行和模型并行,支持多种数据分片和模型并行方式。
2. 灵活性:Ray 可以与各种数据存储和计算库集成,如 PyTorch、TensorFlow、pandas、NumPy 等,同时也支持自定义算法和数据处理管道。
3. 高效性:Ray 使用了一些高效的数据结构和算法,如哈希表、二叉搜索树等,来加速数据处理和模型训练。
4. 可扩展性:Ray 可以轻松地扩展到数千个节点,并且可以在各种环境中运行,包括云、数据中心和边缘设备等
Ray 的应用场景包括:
1. 大规模数据处理和分析:Ray 可以用于处理大规模数据集,如文本、图像、视频等,支持各种数据处理和分析任务,如数据预处理、特征提取、数据清洗等。
2. 机器学习和深度学习:Ray 可以用于训练和部署大规模机器学习模型,支持各种深度学习框架,如 PyTorch、TensorFlow 等,可以加速模型训练和推理。
3. 强化学习和游戏:Ray 可以用于构建和部署强化学习模型,支持各种游戏和机器人控制任务,如 Atari 游戏、机器人导航等。
使用
这边我们一贯的,还是使用pip或者conda进行下载
pip install rayconda install -c conda-forge ray 示例
import ray
import pandas as pd
# 创建一个 Ray cluster
ray.init(num_actors=10)
# 定义一个远程演员函数
@ray.remote
def process_data(data):
print(f"Data received: {data}")
data_df = pd.DataFrame(data)
summary = data_df.describe()
return summary
# 从 CSV 文件中读取数据
data = pd.read_csv("data.csv")
# 发送数据到远程演员函数进行处理
result = process_data.remote(data)
# 获取并打印结果
print(result)
# 关闭 Ray cluster
ray.shutdown()
我们首先导入 ray 和 pandas 库,这些库用于创建 Ray 框架应用程序和处理数据。
然后创建一个 Ray cluster:我们使用 ray.init 函数创建一个 Ray cluster,指定其中的actor数量。actor是 Ray 框架中的一种任务调度方式,用于在集群中分配任务并执行。
之后定义一个远程actor函数,这边可以使用 @ray.remote 装饰器定义一个名为 process_data 的远程演员函数。该函数接收一个数据字符串作为参数,对数据进行处理并返回一个数据摘要。这里我们使用 pandas 库将数据转换为 DataFrame 对象,然后计算数据摘要。
在代码中,我们从 CSV 文件中读取数据:我们使用 pandas 的 read_csv 函数从名为 "data.csv" 的文件中读取数据。
发送数据到远程演员函数进行处理:我们使用 process_data.remote(data) 函数将数据发送到远程Actor函数进行处理。此处的数据是上一步中从 CSV 文件中读取的数据。
获取并打印结果:我们使用 result 变量获取远程Actor函数处理后的结果,然后使用 print 函数将其打印到控制台。
关闭 Ray cluster:在完成示例后,我们使用 ray.shutdown 函数关闭 Ray cluster。
在使用Ray框架时,具体有以下操作:
ray.init()
ray.init() 是 Ray 框架中的一个函数,用于初始化 Ray 实例。它可以在分布式环境中创建一个 Ray 克隆,也可以在单机环境中创建一个 Ray 实例。
可以使用 ray.init() 函数创建一个 Ray 克隆。下面是一个示例:
ray.init(num_actors=10) 上述代码将创建一个名为 "ray-cluster" 的 Ray 克隆,其中包含 10 个工作节点。可以指定克隆的名称和工作节点的数量。在创建 Ray 克隆之后,您可以使用 ray.get() 函数获取克隆的 ID,如下所示:
cluster_id = ray.init(num_actors=10).remote()
print("Cluster ID:", cluster_id) 上述代码将返回一个 Ray 克隆的 ID,可以使用该 ID 获取克隆的详细信息。总结起来,ray.init() 函数是 Ray 框架中的一个重要函数,用于初始化 Ray 实例。它可以在分布式环境中创建一个 Ray 克隆,也可以在单机环境中创建一个 Ray 实例。
ray.put()
ray.put() 是 Ray 框架中的一个函数,用于将数据发送到 Ray 克隆中的某个Actor节点。可以使用 ray.put() 函数将数据发送到远程Actor函数,以便在分布式环境中进行数据处理。
创建 Ray 克隆之后,可以使用 ray.put() 函数将数据发送到远程Actort节点
# 定义一个远程Actor函数
@ray.remote
def process_data(data):
print(f"Data received: {data}")
data_df = pd.DataFrame(data)
summary = data_df.describe()
return summary
# 从 CSV 文件中读取数据
data = pd.read_csv("data.csv")
# 发送数据到远程Actor函数进行处理
result = process_data.remote(data)
# 获取并打印结果
print(result) 上述代码中,我们首先定义一个名为 process_data 的远程Actor函数,该函数接收一个数据字符串作为参数,对数据进行处理并返回一个数据摘要。然后我们使用 ray.put() 函数将数据发送到远程Actor节点,并获取并打印处理结果。
ray.get()
ray.get() 是 Ray 框架中的一个函数,用于从 Ray 克隆中获取数据。可以使用 ray.get() 函数获取远程Actor函数的处理结果,以便在分布式环境中进行数据处理。
# 定义一个远程Actor函数
@ray.remote
def process_data(data):
print(f"Data received: {data}")
data_df = pd.DataFrame(data)
summary = data_df.describe()
return summary
# 从 CSV 文件中读取数据
data = pd.read_csv("data.csv")
# 发送数据到远程Actor函数进行处理
result = process_data.remote(data)
# 使用 ray.get() 函数获取处理结果
result = result.get()
# 获取并打印结果
print(result) @ray.remote
通过使用 @ray.remote,您可以轻松地在分布式环境中调用 Python 函数,而不必担心网络通信、序列化和反序列化等问题。
@ray.remote 的原理主要涉及到以下几个方面:
1. 远程对象(Remote Object):@ray.remote 使用远程对象来表示远程函数。远程对象是一个包装器,它将远程函数的调用转发到远程节点上的实际函数。在 ray.py 中,远程对象是通过 Actors(演员)来实现的。Actors 是一种轻量级的分布式对象,用于在远程节点之间传递消息。
2. 远程调用(Remote Call):要调用一个远程函数,首先需要创建一个远程对象。然后,使用该远程对象的 remote 方法来调用远程函数。remote 方法会通过网络通信框架(如 Pyarrow)将请求发送到远程节点,并在那里执行实际的函数调用。执行完成后,结果将被发送回客户端。
3. 远程函数定义:要使用 @ray.remote,需要定义一个远程函数。远程函数与普通 Python 函数的区别在于,它们需要接受一个额外的参数 ray.remote.RemoteFunction,用于将该函数标记为远程函数。在函数内部,您可以使用 ray.get_actor 方法获取当前的演员实例,从而访问远程对象。
4. 远程函数调用:调用远程函数时,@ray.remote 会自动将函数包装成一个远程对象。然后,它会使用该远程对象的 remote 方法来调用远程函数。remote 方法会根据函数的签名和参数,生成一个请求消息。该消息将被发送到远程节点,并在那里执行实际的函数调用。执行完成后,结果将被发送回客户端。
5. 错误处理:如果远程调用发生错误,@ray.remote 会捕获异常并返回一个错误对象。错误对象包含了错误的类型和消息。这些错误可以在客户端进行处理,以便采取适当的措施,如重试、日志记录等。文章来源:https://www.toymoban.com/news/detail-567670.html
Ray虽然为大数据计算和机器学习带来了很多便利,但是不免也存在着不少缺点。Ray 框架目前仍然处于发展阶段,因此可能存在一些稳定性问题,而且目前只支持少量的编程语言和深度学习框架,因此可能存在一些兼容性问题。文章来源地址https://www.toymoban.com/news/detail-567670.html
到了这里,关于[Python系列] 线程、协程、进程和分布式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!