1、业务场景
一个大的binlog数据库,还原出来了很多SQL语句
binlog生成SQL语句方式
SQL语句需要顺序执行,因为不顺序执行,比如先新增了一条数据,才有可能修改这条数据,假如先执行修改操作,后执行新增操作,那这个数据就错了
2、技术方案选型
- 如果表的binlog文件很小,直接执行就可以了;
- 如果表的binlog太大,那直接执行效率非常低,而且如果某个是否读写出了问题都不知道要从哪里重新执行(如执行时机器出现问题,执行SQL不仅需要读入binlog文件,还要执行SQL语句,频繁的执行SQL可能导致数据库CPU等飙升,可能存在一些执行错误的问题);
- 借助消息队列,可以重复消费来实现,并且通过代码抓取异常来判断是否消费成功,是否重复消费,并且也可以做削峰填谷,批量消费,控制流量,防止MySQL宕机或拒绝连接等;
3、消息队列选型
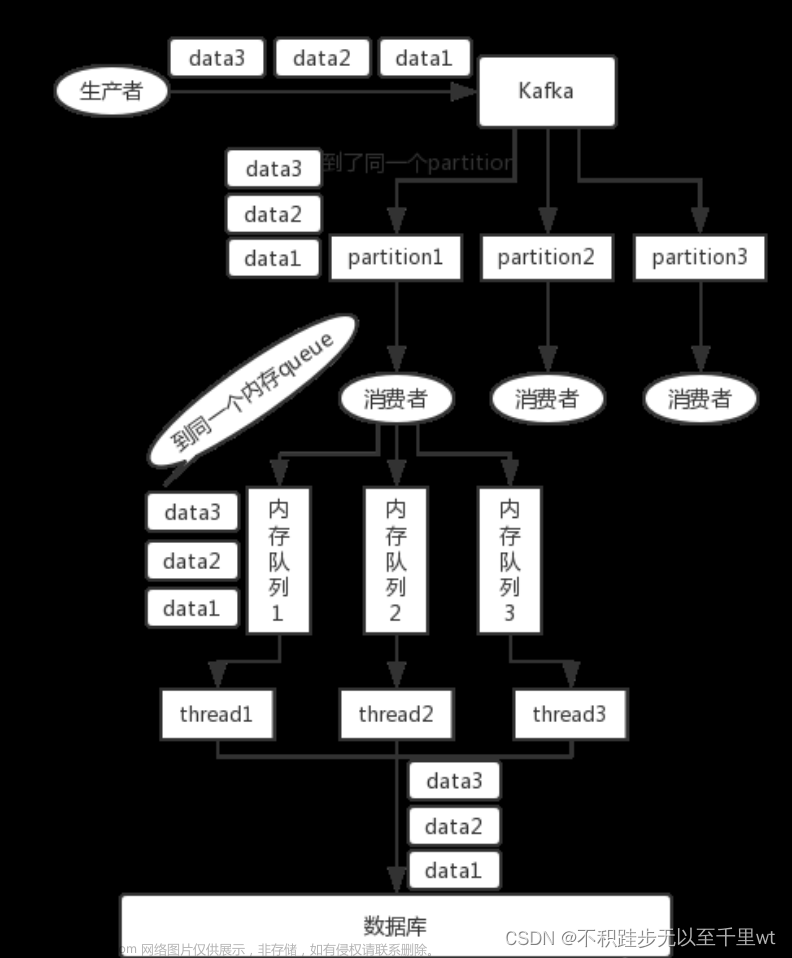
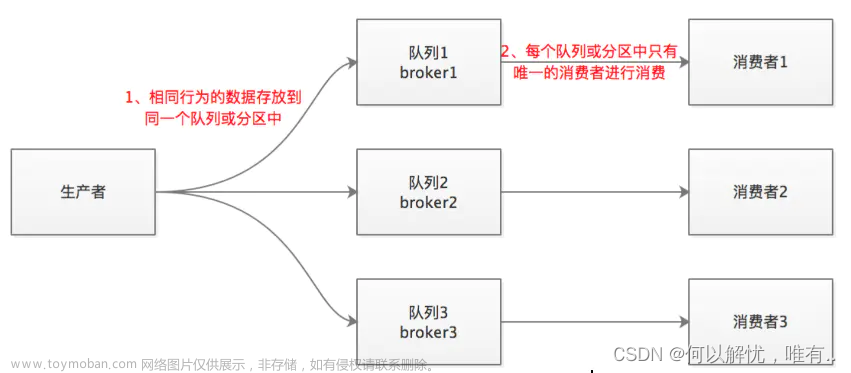
选择kafka,因为kafka写入同一个partition(目录)的数据是顺序的,写入的offset是递增的,我们只需要保证同一个partition消费是顺序的就可以了
Kafka原理
4、设计思路
前提条件:存在物理外键的表,先不用建物理外键,等SQL执行完成,最后补充物理外键,否则可能执行SQL因为数据外键问题失败
发送端文章来源:https://www.toymoban.com/news/detail-568947.html
- 把同一张表,通过表名求hash,发送到指定的分区,这样,同一个表名的执行SQL在队列的partition中肯定是有序的;
消费端文章来源地址https://www.toymoban.com/news/detail-568947.html
- 使用单线程,完全没有问题,但性能太低;
- 直接使用多线程数组,根据表名取Hashing.consistentHash(表名.hashCode()),这样就能保证同一张表的SQL顺序执行,不能直接使用线程池,线程池可能会多个线程同时拉取一个Partition的同一张表数据,虽然取出SQL是顺序的,但SQL的执行效率,分配到CPU的执行时间不是顺序的,这样就会造成执行SQL乱序;
- 批量拉取,使用手动提交,使用CountDownLatch保证所有的线程执行完成才能提交偏移量;
- 线程池执行SQL,如果某个SQL消费异常,抓取异常(如果是重试能解决的异常就通过重试解决,比如数据库连接过多等),记录失败SQL,停止消费,提交偏移量,存在执行失败的SQL,抛出异常,停止继续消费,分析SQL执行失败原因,订正消费代码,手动执行完成失败SQL,之后重新执行,继续开始消费;
@Bean
public ExecutorService[] executorServices() {
ExecutorService[] pools = new ExecutorService[threadCorePoolSize];
for (int i = 0; i < pools.length; i++) {
pools[i] = new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new PriorityBlockingQueue<>(1),
new ThreadFactoryBuilder().setNameFormat("pool-sql-" + i + "-consume-thread-%d").build(),
(r, executor) -> {
try {
executor.getQueue().put(r);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
return pools;
}
@Resource(name = "executorServices")
private ExecutorService[] executorServices;
@KafkaListener(id = "executeBinLogSql", topics = "binlog.execute.sql", containerFactory = "batchKafkaListenerContainerFactory", groupId = CONSUMER_GROUP_ID)
public void subscribe(List<ConsumerRecord<String, byte[]>> consumerRecords, Acknowledgment ack) throws Exception {
long beginTime = Clock.systemDefaultZone().millis();
CountDownLatch countDownLatch = new CountDownLatch(consumerRecords.size());
List<String> failedSqlList = Lists.newArrayListWithExpectedSize(consumerRecords.size());
consumerRecords.forEach(consumerRecord -> {
if (consumerRecord == null) {
return;
}
String tableName = StringUtils.defaultIfEmpty(consumerRecord.key(), "");
if (StringUtils.isEmpty(tableName)) {
return;
}
int hash = Hashing.consistentHash(tableName.hashCode(), executorServices.length);
executorServices[hash].execute(() -> {
String sql = null;
try {
sql = JsonSerializer.deserialize(consumerRecord.value(), KAFKA_RECORD_TYPE_REFERENCE);
} catch (Exception e) {
LOGGER.warn("序列化异常,value:{}", consumerRecord.value());
}
if (StringUtils.isEmpty(sql)) {
return;
}
try {
sqlProcessor.process(sql);
} catch (Exception e) {
LOGGER.error("执行SQL失败 sql: {}", sql, e);
failedSqlList.add(sql);
} finally {
countDownLatch.countDown();
}
});
});
try {
countDownLatch.await(30, TimeUnit.MINUTES);
ack.acknowledge();
if (!CollectionUtils.isEmpty(failedSqlList)) {
throw new Exception("存在执行失败的SQL");
}
} catch (Exception e) {
LOGGER.error("终止线程 failedSqlList: {}", failedSqlList, e);
System.exit(-1);
}
long endTime = Clock.systemDefaultZone().millis();
LOGGER.debug("执行【" + consumerRecords.size() + "】条数据所用时间为:" + (endTime - beginTime));
}
到了这里,关于怎么做到Kafka顺序读写的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!