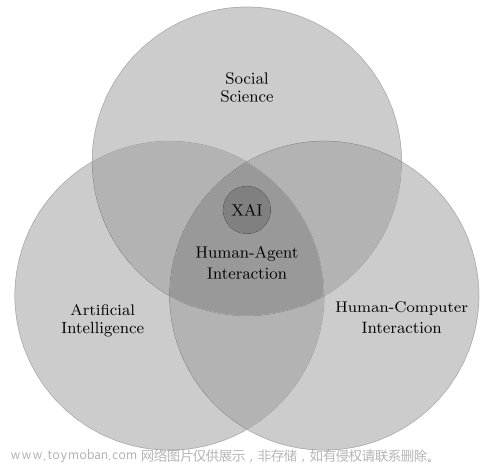
可解释性定义
可解释性没有数学上的定义。
1、可解释性是指人们能够理解决策原因的程度。
2、可解释性是指人们能够一致地预测模型结果的程度。
可解释性包含的性质
如果要确保机器学习模型能够解释决策,除了从定义出发,还可以更容易地检查以下性质:
1、公平性(Fairness)。确保预测是公正的,不会隐式或显式地歧视受保护的群体。
2、隐私性(Privacy)。确保保护数据中的敏感信息。
3、可靠性(Reliability)或鲁棒性(Robustness)。确保输入的微小变化不会导致预测发生剧烈变化。
4、因果性(Causality)。检查是否只找到因果关系。
5、可信任性(Trust)。与黑匣子相比,人们跟容易信任用于解释其决策的系统。
可解释性方法分类
自解释 or 事后可解释
自解释:书中给出的定义是,通过限制机器学习模型的复杂性(称为内在的,也可称为本质上的),说明模型的可解释性。自解释性是指由于结构简单而被认为是可解释的机器学习模型。
事后解释:在训练后分析模型的方法,说明模型的可解释性。事后可解释性是指:模型训练之后运用解释方法,与模型无关的。
解释方法的输出
可以根据解释方法的输出大致区分各种解释方法。
特征概要统计量(Feature Summary Statistic)
许多解释方法为每个特征提供概要统计量。有些方法为每个特征返回一个数字,例如:特征重要性;或者更复杂的输出,例如:成对特征交互强度,即每个特征对表示一个数字。
特征概要可视化(Feature Summary Visualization)
大多数特征概要统计信息也可以可视化。部分依赖图是显示特征和平均预测结果的曲线。
模型内部(Model Internal)
一种方法是自解释模型的解释方法,例如:线性模型中的权重或决策树学习得到的树结构。另一种方法是输出模型内部结构,例如:在卷积神经网络中将学习到的特征检测器可视化。根据定义,输出模型内部的可解释性方法是特定于模型的。
数据点(Data Point)
这种方法返回已经存在或者新创建的数据点以使模型具有可解释性。一种方法称为反事实解释(Counterfactual Explanation),为了解释对数据实例的预测,该方法通过用一些方式改变某些特征以改变预测结果(例如:预测类别的翻转),找到相似的数据点。另一种方法是识别预测类的原型,输出新数据点的解释方法要求可以解释数据点本身。
代理模型
解释黑盒模型的一种解决方案是用可解释模型(全局地或局部地)对其进行近似。而这些可解释模型本身可以通过查看模型内部参数或特征概要统计量来解释。
特定于模型(Model-specific) or 模型无关(Model-agnostic)
特定于模型的解释方法仅限于特定的模型类,例如:应用于神经网络的解释工具也是特定于模型的。相对应的,与模型无关的工具可以用于任何机器学习模型,并在模型经过训练后应用(即事后的)。这些与模型无关的方法通常通过分析特征输入和输出对来实现。根据定义,这些方法是不能访问模型的内部信息的。
局部(Local) or 全局(Global)
局部可解释:解释方法是解释单个实例预测。
全局可解释:解释方法是解释整个模型行为。文章来源:https://www.toymoban.com/news/detail-569692.html
参考文献
Christoph Molnar(著), 朱明超(译). 可解释机器学习:黑盒模型可解释性理解指南. 北京: 电子工业出版社, 2021.文章来源地址https://www.toymoban.com/news/detail-569692.html
到了这里,关于可解释机器学习笔记(一)——可解释性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!