👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO TOP红人
Java知识图谱点击链接:体系化学习Java(Java面试专题)
💕💕 感兴趣的同学可以收藏关注下 ,不然下次找不到哟💕💕
✊✊ 感觉对你有帮助的朋友,可以给博主一个三连,非常感谢 🙏🙏🙏

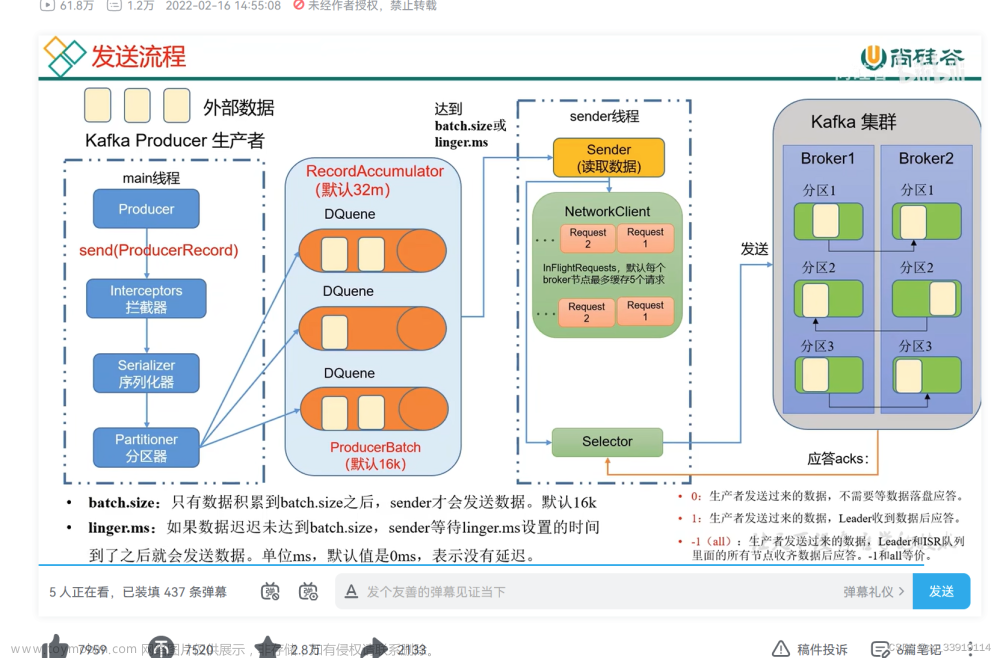
1、什么是 Kafka 生产者

Kafka 生产者是指使用 Apache Kafka 的应用程序,用于向 Kafka 集群发送消息。生产者将消息发布到 Kafka 主题(topic),然后消费者可以从该主题订阅并接收这些消息。Kafka 生产者是实现消息发布的一方,可以是任何编程语言中的应用程序。
2、Java 如何使用 Kafka 生产者
- 首先,在Java项目中添加Kafka客户端依赖项。您可以在构建工具(如Maven或Gradle)中添加以下依赖项:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.2</version>
</dependency>
- 创建Kafka生产者配置。您需要指定Kafka集群的地址和端口等配置信息。以下是一个示例配置:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092"); // Kafka集群地址和端口
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 键的序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 值的序列化器
Producer<String, String> producer;
try {
producer = new KafkaProducer<>(props);
String topic = "your-topic-name";
String key = "your-message-key";
String value = "your-message-value";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record);
} catch (Exception ex) {
} finally {
try {
producer.close();
} catch (Exception ex) {
}
}
但是在 SpringBoot 的项目中我们会使用 KafkaTemplate 去实现生产消息的发送。
3、SpringBoot 如何使用 Kafka 生产者
都需添加以下依赖项:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.2</version>
</dependency>
3.1、方式一:代码
@Configuration
public class KafkaProducerConfig {
/**
* kafka 地址
*/
@Value("${kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
使用如下:
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String key, String value) {
kafkaTemplate.send(topic, key, value);
}
}
3.2、方式二:配置文件
可以 application.properties: 加上:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.value-serializer=org.apache.kafka.common.serialization.StringSerializer
或者 yml 里面加上
spring:
kafka:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
直接使用
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String key, String value) {
kafkaTemplate.send(topic, key, value);
}
}
以上也只是一个简单的实例,后面我们根据 【项目实战】手把手教你搭建前后端分离项目 SpringBoot + Vue + Element UI + Mysql, 在这个教程的基础上,我们写如何实战。
4、Kafka Properties 的详细讲解
以下是所有参数的详细解释:
-
bootstrap.servers:生产者用于与Kafka集群建立初始连接的主机和端口列表。 -
acks:生产者要求leader在认为请求完成之前接收的确认数。可能的值有:
-
0:生产者不等待任何确认。 -
1:生产者等待leader确认请求。 -
all:生产者等待所有同步副本确认请求。
-
retries:在放弃之前,生产者将重试发送失败的消息的次数。设置大于0的值以启用重试。 -
batch.size:生产者尝试发送到Kafka代理的批次的大小(以字节为单位)。较大的批次大小可以提高吞吐量,但会增加消息传递的延迟。 -
linger.ms:生产者在将批次发送到Kafka代理之前等待更多消息累积的时间(以毫秒为单位)。这有助于批处理,减少发送到代理的请求数量。 -
buffer.memory:生产者用于缓冲等待发送到Kafka代理的消息的总内存量。 -
key.serializer:用于将键对象序列化为字节的类。常见的选项是StringSerializer或ByteArraySerializer。 -
value.serializer:用于将值对象序列化为字节的类。常见的选项是StringSerializer或ByteArraySerializer。 -
compression.type:用于消息的压缩类型。支持的值有none、gzip、snappy或lz4。压缩可以减少网络带宽和存储要求。 -
max.in.flight.requests.per.connection:在阻塞之前,生产者可以有的未确认请求的最大数量。将此值设置为较高的值可以增加吞吐量,但也会增加用于缓冲的内存。 -
request.timeout.ms:生产者在考虑请求失败之前,从Kafka代理等待响应的最长时间(以毫秒为单位)。 -
max.block.ms:当缓冲区已满或元数据不可用时,生产者在send()方法中阻塞的最长时间(以毫秒为单位)。
以上这些是Kafka生产者配置中常用的一些属性,使用方法如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092"); // Kafka集群地址和端口
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 键的序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 值的序列化器
5、Spring-Kafka Yml 配置参数
spring:
kafka:
bootstrap-servers: <bootstrap-servers>
producer:
key-serializer: <key-serializer>
value-serializer: <value-serializer>
retries: <retries>
batch-size: <batch-size>
linger-ms: <linger-ms>
buffer-memory: <buffer-memory>
compression-type: <compression-type>
consumer:
group-id: <group-id>
key-deserializer: <key-deserializer>
value-deserializer: <value-deserializer>
auto-offset-reset: <auto-offset-reset>
enable-auto-commit: <enable-auto-commit>
max-poll-records: <max-poll-records>
以下是每个参数的解释:
- bootstrap-servers :Kafka broker地址的逗号分隔列表。
- producer.key-serializer :用于将键对象序列化为字节的类。
- producer.value-serializer :用于将值对象序列化为字节的类。
- producer.retries :在放弃之前,生产者将重试发送失败的消息的次数。
- producer.batch-size :生产者将尝试发送到Kafka broker的批次的大小(以字节为单位)。
- producer.linger-ms :生产者在将批次发送到Kafka broker之前等待更多消息累积的时间(以毫秒为单位)。
- producer.buffer-memory :生产者用于缓冲等待发送到Kafka broker的消息的总内存量。
- producer.compression-type :消息的压缩类型。
- consumer.group-id :消费者组ID。
- consumer.key-deserializer :用于将键对象从字节反序列化的类。
- consumer.value-deserializer :用于将值对象从字节反序列化的类。
- consumer.auto-offset-reset :当Kafka中没有初始偏移量或当前偏移量不再存在时,使用的策略。
- consumer.enable-auto-commit :消费者的偏移量是否应自动提交。
- consumer.max-poll-records :消费者在一次轮询中最多获取的记录数。
6、Kafka 生产者异步回调方式生产消息
6.1、什么是异步回调
什么是异步回调要搞清楚,异步回调指的是我发送完成了,我就不管了,我不需要等你的返回。具体的定义如下:
异步回调是一种编程模式,用于处理异步操作的结果。在异步回调中,当一个操作被触发时,程序不会立即阻塞等待结果,而是继续执行其他任务。当操作完成后,系统会调用预先定义的回调函数来处理操作的结果。
异步回调常用于处理需要等待时间较长的操作,例如网络请求、数据库查询等。通过使用异步回调,可以提高系统的响应性能和并发处理能力,避免阻塞和等待的情况。
在异步回调中,通常将回调函数作为参数传递给异步操作的方法。当操作完成后,系统会调用回调函数,并将操作的结果作为参数传递给回调函数,以便进行后续处理。
异步回调在编写异步代码时非常有用,可以帮助开发人员处理异步操作的结果,而无需显式地等待操作完成。这种方式可以提高系统的性能和可伸缩性,同时保持代码的简洁性和可读性。文章来源:https://www.toymoban.com/news/detail-570015.html
6.2、匿名内部类的方式做异步回调
public class KafkaProducerExample{
private static final String TOPIC_NAME = "test-topic";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", BOOTSTRAP_SERVERS);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
String message = "Hello, Kafka! This is message " + i;
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 匿名内部类的方式做异步回调
}
});
}
producer.close();
}
}
6.3、 KafkaTemplate 的异步回调
package com.pany.camp.kafka;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import javax.annotation.Resource;
/**
*
* @description: 生产者
* @copyright: @Copyright (c) 2022
* @company: Aiocloud
* @author: pany
* @version: 1.0.0
* @createTime: 2023-06-26 18:10
*/
@Component
public class KafkaProducer {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, message);
future.addCallback(new ListenableFutureCallback<>() {
@Override
public void onSuccess(Object o) {
}
@Override
public void onFailure(Throwable ex) {
// Handle failure callback
System.err.println("Failed to send message: " + ex.getMessage());
}
});
}
}
💕💕 本文由激流原创,原创不易,希望大家关注、点赞、收藏,给博主一点鼓励,感谢!!!
🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃🎃 文章来源地址https://www.toymoban.com/news/detail-570015.html
文章来源地址https://www.toymoban.com/news/detail-570015.html
到了这里,关于【项目实战】Java 开发 Kafka 生产者的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!