🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
基于隐空间的扩散模型 (Latent Diffusion Model),是解决文本到图片生成问题上的颠覆者。Stable Diffusion 是最著名的一例,广泛应用在商业和工业。Stable Diffusion 的想法简单且有效: 从噪声向量开始,多次去噪,以使之在隐空间里逼近图片的表示。
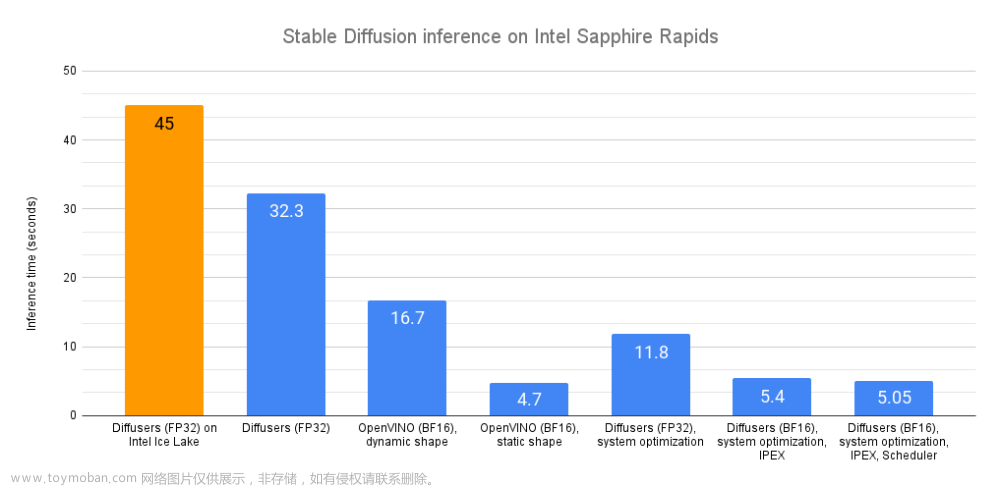
但是,这样的方法不可避免地增加了推理时长,使客户端的体验大打折扣。众所周知,一个好的 GPU 总能有帮助,确实如此,但其损耗大大增加了。就推理而言,在 2023 年上半年 (H1’23),一个好 CPU 实例 (r6i.2xlarge,8 vCPUs ,64 GB 内存) 价格是 0.504 $/h,同时,类似地,一个好 GPU 实例 (g4dn.2xlarge,NVIDIA T4,16 GB 内存) 价格是 0.75 $/h ,是前者的近 1.5 倍。
这就使图像生成的服务变得昂贵,无论持有者还是用户。该问题在面向用户端部署就更突出了: 可能没有 GPU 能用!这让 Stable Diffusion 的部署变成了棘手的问题。
在过去五年中,OpenVINO 集成了许多高性能推理的特性。其一开始为计算机视觉模型设计,现今仍在许多模型的推理性能上取得最佳表现,包括 Stable Diffusion。然而,对资源有限型的应用,优化 Stable Diffusion 远不止运行时的。这也是 OpenVINO NNCF(Neural Network Compression Framework) 发挥作用的地方。
在本博客中,我们将理清优化 Stable Diffusion 模型的问题,并提出对资源有限的硬件 (比如 CPU) 减负的流程。尤其是和 PyTorch 相比,我们速度提高了 5.1 倍,内存减少了 4 倍。
Stable Diffusion 的优化
在 Stable Diffusion 的 管线 中,UNet 的运行是最计算昂贵的。因此,对模型的推理速度,针对 UNet 的优化能带来足够的效益。
然而事实表明,传统的模型优化方法如 8-bit 的后训练量化,对此不奏效。主要原因有两点: 其一,面向像素预测的模型,比如语义分割、超分辨率等,是模型优化上最复杂的,因为任务复杂,参数和结构的改变会导致无数种变数; 其二,模型的参数不是很冗余,因为其压缩了其数以千万计的 数据集 中的信息。这也是研究者不得不用更复杂的量化方法来保证模型优化后的精度。举例而言,高通 (Qualcomm) 用分层知识蒸馏 (layer-wise Knowledge Distillation) 方法 (AdaRound) 来 量化 Stable Diffusion。这意味着,无论如何,模型量化后的微调是必要的。既然如此,为何不用 量化感知的训练 (Quantization-Aware Trainning, QAT),其对原模型的微调和参数量化是同时进行的?因此,我们在本工作中,用 token 合并 (Token Merging) 方法结合 NNCF, OpenVINO 和 Diffusers 实践了该想法。
优化流程
我们通常从训练后的模型开始优化。在此,我们从宝可梦数据集 (Pokemons dataset,包含图片和对应的文本描述) 上微调的 模型。
我们对 Stable Diffusion 用 Diffusers 中的 图片 - 文本微调之例,结合 NNCF 中的 QAT (参见训练的 脚本)。我们同时改变了损失函数,以同时实现从源模型到部署模型的知识蒸馏。该方法与通常的知识蒸馏不同,后者是把源模型蒸馏到小些的模型。我们的方法主要将知识整理作为附加的方法,帮助提高最后优化的模型的精度。我们也用指数移动平均方法 (Exponential Moving Average, EMA) 让我们训练过程更稳定。我们仅对模型做 4096 次迭代。
基于一些技巧,比如梯度检查 (gradient checkpointing) 和 保持 EMA 模型 在内存 (RAM) 而不是虚拟内存 (VRAM) 中。整个优化过程能用一张 GPU 在一天内完成。
量化感知的训练之外呢 ?
量化模型本身就能带来模型消耗、加载、内存、推理速度上的显著提高。但量化模型蛮大的优势在能和其他模型优化方法一起,达到加速的增益效果。
最近,Facebook Research 针对视觉 Transformer 模型,提出了一个 Token Merging 方法。该方法的本质是用现有的方法 (取平均、取最大值等) 把冗余的 token 和重要的 token 融合。这在 self-attention 块之前完成,后者是 Transformer 模型最消耗算力的部分。因此,减小 token 的跨度能减少 self-attention 块消耗的时间。该方法也已被 Stable Diffusion 模型 采用,并在面向 GPU 的高分辨率优化上有可观的表现。
我们改进了 Token Merging 方法,以便用 OpenVINO,并在注意力 UNet 模型上采用 8-bit 量化。这包含了上述含知识蒸馏等的所有技术。对量化而言,其需要微调,以保证数值精度。我们也从 宝可梦数据集 上训练的 模型 开始优化和微调。下图体现了总体的优化工作流程。

结果的模型在有限资源的硬件上是高度有效的,如客户机或边缘 CPU。如上文所述,把 Token Merging 方法和量化方法叠加能带来额外的推理增益。




用不同模型优化方法的图片生成的结果 展示。输入提示词为 “cartoon bird”,随机种子为 42。模型用 OpenVINO 2022.3,来自 Hugging Face Space,用“CPU 升级”的实例: 第三代 Intel® Xeon® Scalable Processors,和 Intel® 深度学习加速技术。
结果
我们用优化模型不完整的流程以得到两种模型: 基于 8-bit 量化的和基于 Token Merging 量化的,并和 PyTorch 作为基准比较。我们也把基准先转化成 vanilla OpenVINO (FP32) 的模型,以用以分析性比较。
上面的结果图展示了图像生成和部分模型的特性。如你所见,仅转化成 OpenVINO 就带来大的推理速度提高 ( 1.9 倍)。用基于 8-bit 的量化加速和 PyTorch 相比带来了 3.9 倍的推理速度。量化的另外一个重要提高在于内存消耗减少,0.25 倍之于 PyTorch,同时也提高了加载速度。在量化之上应用 Token Merging (ToME) (融合比为 0.4) 带来了 5.1 倍 的提速,同时把模型内存消耗保持在原水平上。我们不提供输出结果上的质量改变,但如你所见,结果还是有质量的。
下面我们展示将最终优化结果部署在 Intel CPU 上代码。
from optimum.intel.openvino import OVStableDiffusionPipeline
# Load and compile the pipeline for performance.
name = "OpenVINO/stable-diffusion-pokemons-tome-quantized-aggressive"
pipe = OVStableDiffusionPipeline.from_pretrained(name, compile=False)
pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
pipe.compile()
# Generate an image.
prompt = "a drawing of a green pokemon with red eyes"
output = pipe(prompt, num_inference_steps=50, output_type="pil").images[0]
output.save("image.png")在 Hugging Face Optimum Intel 库中你可以找到训练和量化 代码。比较优化过的和原模型的 notebook 代码在 这里。你可以在 Hugging Face Hub 上找到 OpenVINO 下的 许多模型。另外,我们在 Hugging Face Spaces 上建了一个 demo,以运行带第三代 Intel Xeon Scalable 的 r6id.2xlarge 实例。
一般的 Stable Diffusion 模型呢?
正如我们在宝可梦图像生成任务中展现的一样,仅用小量的训练资源,对 Stable Diffusion 管线实现高层次的优化是可能的。同时,众所周知,训练一般的 Stable Diffusion 模型是一个 昂贵的任务。但是,有充足的资金和硬件资源,用上述方法优化一般的模型生成高分辨率的模型是可能的。我们唯一的警告是关于 Token Merging 方法,其会减弱模型容忍性。这里衡量标准是,训练数据越复杂,优化模型时的融合比就该越小。
如果你乐于读本博客,那你可能对另外一篇 博客 感兴趣,它讨论了在第四代 Intel Xeon CPU 上其他互补的 Stable Diffusion 模型优化方法。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/train-optimize-sd-intel
作者: Alexander, Yury Gorbachev, Helena, Sayak Paul, Ella Charlaix
译者: Vermillion文章来源:https://www.toymoban.com/news/detail-571100.html
审校/排版: zhongdongy (阿东)文章来源地址https://www.toymoban.com/news/detail-571100.html
到了这里,关于基于 NNCF 和 Optimum 面向 Intel CPU 对 Stable Diffusion 优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!