一.集群实例创建
以三个 Hadoop 实例创建集群,可以用虚拟机,或者Docker容器来实现。本教程直接使用虚拟机演示
集群架构可参考下图:客户端、命名节点和数据节点

查看 Hadoop 配置文件目录:ll $HADOOP_HOME/etc/hadoop

Hadoop 基本概念与含义
| 名称 | 含义 |
|---|---|
| HDFS | Hadoop Distributed File System,Hadoop 分布式文件系统的简称 |
| NameNode | 指挥其它节点存储的节点,用于映射文件在集群存储的位置 |
| Secondary NameNode | 副命名节点,用于备份命名节点数据,并协助命名节点进行管理工作;命名节点崩溃后可以用来恢复其数据,可以有多个 |
| DataNode | 用来储存数据块的节点,HDFS基础存储单位,受命名节点协调管理 |
| core-site.xml | Hadoop 核心配置 |
| hdfs-site.xml | HDFS 配置项 |
| mapred-site.xml | MapReduce 配置项,映射和规约,对大型任务分治处理 |
| yarn-site.xml | YARN 配置项 |
| workers | 记录所有的数据节点的主机名或 IP 地址 |
二.配置
1.创建三个虚拟机(Anolis)
| 虚拟机名称 | 地址 | Host Name |
|---|---|---|
| hadoop_1 | 192.168.1.6 | nn |
| hadoop_2 | 192.168.1.7 | nd1 |
| hadoop_3 | 192.168.1.8 | nd2 |

1.修改 HostName
## 修改 192.168.1.6 服务器
hostnamectl set-hostname nn
echo "192.168.1.7 nd1" >> /etc/hosts
echo "192.168.1.8 nd2" >> /etc/hosts
## 修改 192.168.1.7 服务器
hostnamectl set-hostname nd1
echo "192.168.1.6 nn" >> /etc/hosts
echo "192.168.1.8 nd2" >> /etc/hosts
## 修改 192.168.1.8 服务器
hostnamectl set-hostname nd2
echo "192.168.1.6 nn" >> /etc/hosts
echo "192.168.1.7 nd1" >> /etc/hosts
以 192.168.1.6 为例

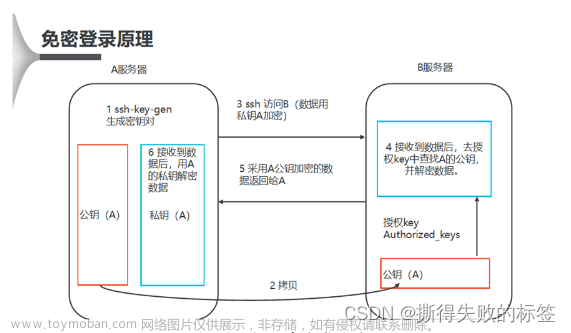
2.配置免密登录,配置前
ssh root@nd1

## 修改 192.168.1.6 服务器
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
ssh-copy-id -i ~/.ssh/id_rsa root@nd1
ssh-copy-id -i ~/.ssh/id_rsa root@nd2
## 修改 192.168.1.7 服务器
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
ssh-copy-id -i ~/.ssh/id_rsa root@nn
ssh-copy-id -i ~/.ssh/id_rsa root@nd2
## 修改 192.168.1.8 服务器
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
ssh-copy-id -i ~/.ssh/id_rsa root@nn
ssh-copy-id -i ~/.ssh/id_rsa root@nd1
## 分别配置本地登录
ssh-copy-id -i ~/.ssh/id_rsa root@localhost
以 192.168.1.6为例,免密访问 nd1

2.配置命名节点
1.在 nd1 / nd2 部署 hadoop
## 解压文件
mkdir -p /usr/local/java
mkdir -p /usr/local/hadoop
tar zxvf jdk-11.0.19_linux-x64_bin.tar.gz -C /usr/local/java/
tar zxvf hadoop-3.3.6.tar.gz -C /usr/local/hadoop/
## 设置环境变量
echo 'export JAVA_HOME=/usr/local/java/jdk-11.0.19' >> /etc/profile
echo 'export CLASSPATH=$JAVA_HOME/lib:$CLASSPATH' >> /etc/profile
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
echo 'export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.6' >> /etc/profile
echo 'export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin' >> /etc/profile
source /etc/profile
2.配置
## 1.进入
cd $HADOOP_HOME/etc/hadoop
## 2.修改配置 core-site.xml
vim core-site.xml
## 增加如下信息
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///home/hadoop/tmp</value>
</property>
## 3.修改配置 hdfs-site.xml
vim hdfs-site.xml
## 增加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:///home/hadoop/hdfs/data</value>
</property>
## 4.修改配置 yarn-site.xml
vim yarn-site.xml
## 增加如下信息
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nn</value>
</property>
## 5.修改配置 mapred-site.xml
vim mapred-site.xml
## 增加如下信息
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
## 6.修改配置 workers
vim workers
## 增加如下信息
nn
nd1
nd2
## 7.将以上两个文件从 nn 复制到 nd1/nd2
scp core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml hadoop-env.sh workers root@nd1:$HADOOP_HOME/etc/hadoop
scp core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml hadoop-env.sh workers root@nd2:$HADOOP_HOME/etc/hadoop
core-site.xml

hdfs-site.xml

yarn-site.xml

mapred-site.xml

workers

## 格式化命名节点:$HADOOP_HOME/etc/hadoop
hdfs namenode -format
## 启动服务
start-dfs.sh
格式化结果

启动结果

## 启动 Yarn
start-yarn.sh

3.查看集群信息
集群信息:http://192.168.1.6:9870/dfshealth.html#tab-datanode

在 Windows 访问 http://nd1:9864 要关虚拟机防火墙,并添加 Host 解析,此处直接通过 IP 地址打开

Yarn 信息:http://192.168.1.6:8088/cluster

三.测试
1.Shell 命令
## 上传文件
hadoop fs -put /home/test.txt /log/
## 查看文件
hadoop fs -cat /log/test.txt

2.Java & MapReduce
Apache Hadoop 官网
单词统计代码
package org.example.controller;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @author Administrator
* @Description
* @create 2023-07-17 23:22
*/
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
测试类,测试地址:http://127.0.0.1:8080/test/wordCount
package org.example.controller;
import jakarta.annotation.PostConstruct;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
/**
* @author Administrator
* @Description
* @create 2023-07-13 23:19
*/
@RestController
@RequestMapping("/test")
public class TestController {
@PostConstruct
public void init(){
System.setProperty("HADOOP_USER_NAME","root");
}
@GetMapping("/wordCount")
public void wordCount() throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.6:9000");
// 打开文件并读取输出
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/testData"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
boolean result = job.waitForCompletion(true);
// System.exit(result ? 0 : 1);
// 打开文件并读取输出
FileSystem fs = FileSystem.get(conf);
Path path = new Path("/output/part-r-00000");
FSDataInputStream ins = fs.open(path);
StringBuilder builder = new StringBuilder();
int ch = ins.read();
while (ch != -1) {
builder.append((char)ch);
ch = ins.read();
}
System.out.println(builder.toString());
}
}
测试结果
 文章来源:https://www.toymoban.com/news/detail-571580.html
文章来源:https://www.toymoban.com/news/detail-571580.html
 文章来源地址https://www.toymoban.com/news/detail-571580.html
文章来源地址https://www.toymoban.com/news/detail-571580.html
到了这里,关于Hadoop 之 分布式集群配置与使用(三)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!