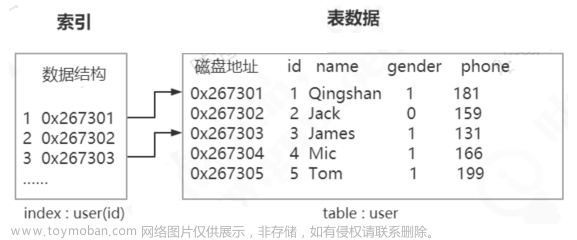
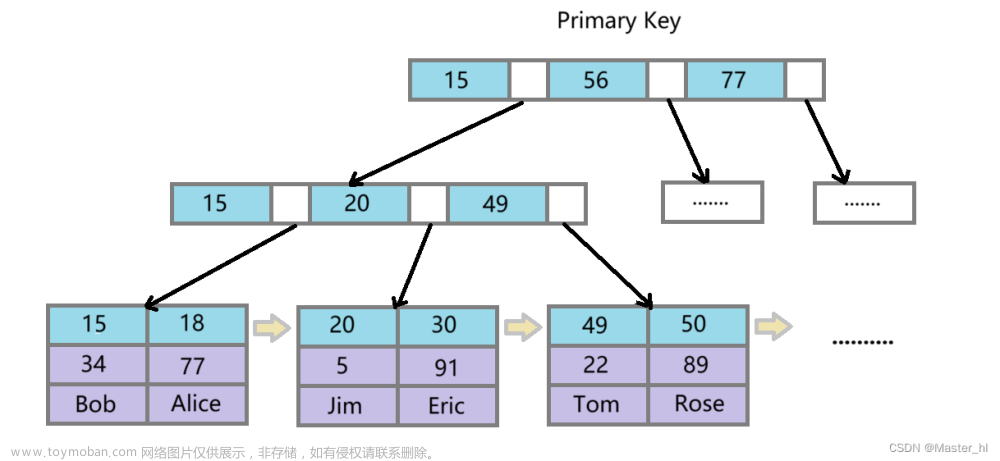
索引就像一本书的目录,通过索引可以快速找到我们想要找的内容。那么什么样的数据结构可以用来实现索引呢?我们可能会想到:二叉查找树,平衡搜索树,或者是B树等等一系列的数据结构,那么为什么MySQL最终选择了B+树作为索引的数据结构呢?
索引的“要求”
要想知道什么样的数据结构最适合索引,首先我们要知道索引需要什么?
首先,数据库的索引时保存在磁盘上的,因此我们在查询索引的时候,要先去磁盘上读取索引到内存,然后再通过索引找到要访问的数据,最后再去磁盘中读取数据,整个过程中会发生多次IO,那么我们自然希望发生磁盘IO的次数越小越好,这样可以提高数据查询的效率。
其次,MySQL是支持范围查找的,所以我们希望通过索引可以进行高效的范围查找。
二叉查找树
二叉查找树可以在logN的时间内找到目标值,那么二叉查找树适合用作索引吗?

答案是不适合
首先,二叉查找树存在极端情况,如果每次插入的结点都是最小或者最大的,那么二叉查找树就会退化成链表,查询的时间复杂度就从O(logN)降到了O(N)
其次,如果索引的数量很多,树的高度也会变得很高,磁盘需要的IO次数也会不断增加。
平衡二叉树
平衡二叉树相比于二叉查找树加上了一个条件:左右子树高度差不能超过1;虽然这个条件避免了原先二叉查找树中极端情况下会退化成链表的问题。
但是同样的,当树中的结点不断增加的时候,树的高度高度也会不断增加,同样会使得IO次数不断增加。
B树
实际上,二叉查找树和平衡二叉树不适合作为索引的数据结构,究其本质还是因为他们是二叉树,于是我们可以看一下m叉树的一些数据结构,比如B树。
B树不再限制一个节点就只能有2个子节点,而是允许M个子节点 (M>2),从而降低树的高度。B树的每一个节点最多可以包括M个子节点,M称为B树的阶,所以B树就是一个多叉树。
使用了多叉树的数据结构以后,就解决了传统二叉查找树中随着索引数量的增多,IO次数会变高的问题。在实际使用中,只要M大于100,即便是千万级的数据量,仍然可以保证在3-4次IO内就找到数据。相比与传统的二叉树,多叉树会更加矮胖,更适合作为索引的数据结构。

但是,MySQL仍然没有选择B树,为什么呢?
首先,B树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到真正需要的索引数据信息。
其次,MySQL是支持范围查询的,B树进行范围查询需要进行树的中序遍历,需要使用递归或者迭代搜索来进行遍历,效率不高。
B+树
最后,MySQL选择了B+树,B+树的结构大致如下所示:

B+树和B树很相似,差异如下:
-
叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引
-
所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
这样就解决了B树的两个缺陷。
B+树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的B树,B+树的非叶子节点可以存放更多的索引,因此B+树可以比B树更矮胖,查询底层节点的磁盘 I/O次数会更少。
B+树所有叶子结点使用双向链表连接,这使得其进行范围查找的时候,十分方便,相较于B树范围查询效率更高。
总结
为什么采用B+树作为索引的数据结构?
1.和传统的二叉查找树相比,B+树是一棵多叉树,树的高度更小,整个树更加矮胖,查询的效率更高;二叉树的话,数据量上去了树的高度就会很高。
(tips:实际使用中,m的值会超过100,此时即便是千万级的数据量,仍然可以保证在3-4次IO内就找到数据)文章来源:https://www.toymoban.com/news/detail-571862.html
2.和B树相比文章来源地址https://www.toymoban.com/news/detail-571862.html
- B+树的磁盘IO效率更高。B+树的数据只会存放在叶子结点(非叶子节点只存索引信息),而B树在每个节点上都要存放数据,所以在相同的空间内,B+树可以存放更多地索引信息,IO效率更高(单次IO获得的索引信息量更大)
- B+树范围查找效率更高,B树进行范围查找需要进行树中序遍历,而B+树的叶子结点使用了双向链表连接起来,范围查找效率更高。
到了这里,关于MySQL为什么采用B+树作为索引底层数据结构?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!