图像分类传统算法和深度学习算法简单介绍
图像分类是计算机视觉领域的一项基本任务,旨在根据输入图像将其预测到一个或多个类别中。本文档将详细介绍一些常用的图像分类算法,包括传统方法和深度学习方法。
传统图像分类方法
在深度学习技术兴起之前,计算机视觉领域的研究者们使用传统的机器学习方法来进行图像分类。这些方法通常包括特征提取和分类器设计两个阶段。我们将介绍三种常用的传统图像分类方法:k-近邻算法、支持向量机和随机森林。
k-近邻算法 (k-NN)
k-近邻算法是一种简单且直观的分类方法。它的基本思想是:给定一个新的待分类数据点,找到训练数据集中与其最近的k个邻居,然后根据这些邻居的类别进行投票,最终得到新数据点的类别。k-NN算法的核心在于计算数据点之间的距离。常用的距离度量包括欧氏距离、曼哈顿距离等。
支持向量机 (SVM)
支持向量机是一种二分类方法,通过寻找一个超平面将数据集中的两类数据分开。该超平面被称为最大间隔超平面,因为它试图最大化距离最近的两类数据点之间的间隔。对于非线性可分问题,SVM可以通过核函数将数据映射到更高维的空间中,使得数据线性可分。SVM具有良好的泛化能力,但在大规模数据集上的计算成本较高。
随机森林 (RF)
随机森林是一种集成学习方法,通过构建多个决策树来共同进行分类。每个决策树在训练时使用一个随机抽样的子集,并在每个节点处使用随机选择的特征。随机森林的分类结果是所有决策树投票结果的众数。随机森林可以有效解决过拟合问题,具有较好的鲁棒性和泛化能力。
深度学习图像分类方法
随着深度学习技术的发展,卷积神经网络(CNN)已成为图像分类任务的首选方法。CNN具有自动提取特征和分类的能力,可以在大规模数据集上取得优异的性能。接下来,我们将介绍一些具有代表性的CNN架构。
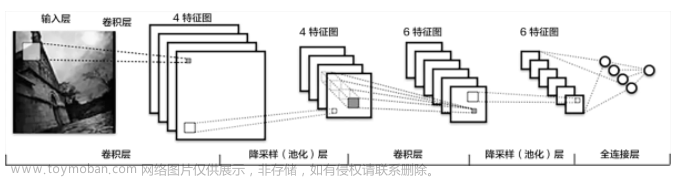
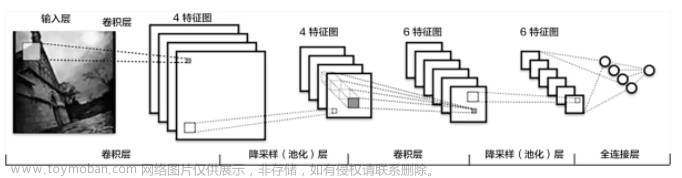
卷积神经网络 (CNN)
卷积神经网络是一种特殊的神经网络结构,主要包括卷积层、激活层、池化层和全连接层。卷积层负责提取图像的局部特征,激活层引入非线性,池化层降低特征维度,全连接层实现最终的分类任务。
LeNet-5
LeNet-5是由Yann LeCun于1998年提出的早期CNN架构。它包括两个卷积层、两个池化层和三个全连接层。LeNet-5的成功应用于手写数字识别任务为后续的CNN发展奠定了基础。
AlexNet
2012年,Alex Krizhevsky等人提出了AlexNet,这是第一个在大规模图像数据集上取得显著性能提升的CNN结构。AlexNet包括5个卷积层、3个池化层和3个全连接层。与LeNet相比,AlexNet具有更深的网络结构和更大的参数规模。此外,它还引入了ReLU激活函数、Dropout技术和数据增强等技巧。
VGG
2014年,牛津大学的Visual Geometry Group提出了VGG网络。VGG的主要特点是使用连续的3x3卷积核替代较大的卷积核,从而减少参数数量并提高计算效率。VGG具有多个版本,其中VGG-16和VGG-19最为知名。
Inception (GoogLeNet)
同样在2014年,Google团队提出了Inception网络(也称为GoogLeNet)。Inception的主要创新是引入了Inception模块,这是一种并行堆叠不同尺度卷积核的结构。Inception网络较大幅度减少了参数数量,同时保持了较高的性能。
ResNet
2015年,微软研究院的Kaiming He等人提出了残差网络(ResNet)。ResNet的关键创新是引入了跳跃连接(skip connection),使网络层之间可以直接传递信息。这种结构有效解决了深度网络中的梯度消失问题,使得网络可以达到非常大的深度。ResNet在ImageNet竞赛中取得了突破性的成绩,深度达到了152层。
DenseNet
2017年,Gao Huang等人提出了密集连接网络(DenseNet)。DenseNet的核心思想是将每个层的输出连接到后续的所有层,形成一个密集连接的结构。这种连接方式可以增强特征传播,提高网络的参数利用率,并降低训练成本。
EfficientNet
2019年,Google团队提出了EfficientNet,这是一种基于神经网络搜索技术(NAS)优化的CNN结构。EfficientNet的主要贡献是引入了一种均衡的网络扩展策略,通过调整网络的深度、宽度和分辨率来提高性能。EfficientNet在多个图像分类任务上实现了最先进的性能,同时具有较低的参数量和计算成本。
迁移学习
迁移学习是一种利用预训练模型在新任务上进行模型训练的方法。在图像分类任务中,通常使用在大规模数据集上预训练的模型,如ImageNet。在训练时,可以将预训练模型的特征提取部分固定,只训练新加入的分类器部分,也可以微调整个模型的参数。迁移学习可以减少新任务上的训练时间和数据量,同时提高模型的泛化能力。
数据增强
数据增强是一种通过对原始图像进行一系列随机变换来增加数据量的技术。在图像分类任务中,常用的数据增强方式包括随机裁剪、随机翻转、颜色抖动、旋转等。数据增强可以有效地提高模型的鲁棒性和泛化能力,同时减少模型对于数据集中特定样本的过拟合。文章来源:https://www.toymoban.com/news/detail-572209.html
总结
本文介绍了常用的图像分类算法,包括传统方法和深度学习方法。传统方法包括k-近邻算法、支持向量机和随机森林;深度学习方法则主要以卷积神经网络为代表,包括LeNet-5、AlexNet、VGG、Inception、ResNet、DenseNet和EfficientNet等。此外,我们还介绍了迁移学习和数据增强这两种能够提高模型性能的技术。总体来说,随着深度学习技术的发展,越来越多的图像分类任务可以使用深度学习方法来解决。但是,对于小规模数据集和资源受限的情况,传统方法仍然具有一定的优势。文章来源地址https://www.toymoban.com/news/detail-572209.html
到了这里,关于图像分类传统算法和深度学习算法简单介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!