离散数据
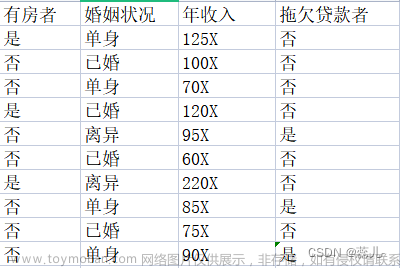
离散数据是指其数值只能用自然数或整数单位计算的数据。例如:企业个数、职工人数、设备台数等,只能按计量单位数计数。这种数据的数值一般用计数方法取得。在统计学中,数据按变量值是否连续可分为连续数据与离散数据两种。
连续数据
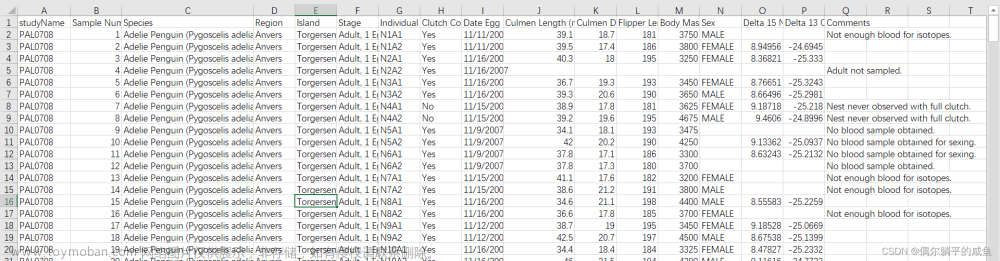
在一定区间内可以任意取值的数据叫连续数据,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。例如,生产零件的规格尺寸和人体测量的身高和体重和胸围等为连续数据,其数值只能用测量或计量的方法获得。
离散变量与连续变量
符号x如果能够表示对象集合S中的任意元素,就是变量。如果变量的域(即对象的集合S)是离散的,该变量就是离散变量;如果它的域是连续的,它就是连续变量。
单项式分组
对离散变量,如果变量值的变动幅度小,就可以一个变量值对应一组,称单项式分组。例如,如果学生的成绩以五分制计算,则全体学生的成绩可以分为六组,即5、4、3、2、1、0。文章来源:https://www.toymoban.com/news/detail-572396.html
组距式分组
离散变量如果变量值的变动幅度很大,变量值的个数很多,则把整个变量值依次划分为几个区间,各个变量值则按其大小确定所归并的区间,区间的距离称为组距,这样的分组称为组距式分组。文章来源地址https://www.toymoban.com/news/detail-572396.html
到了这里,关于离散数据与连续数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!