1、背景
随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。

2、微服务架构下的问题
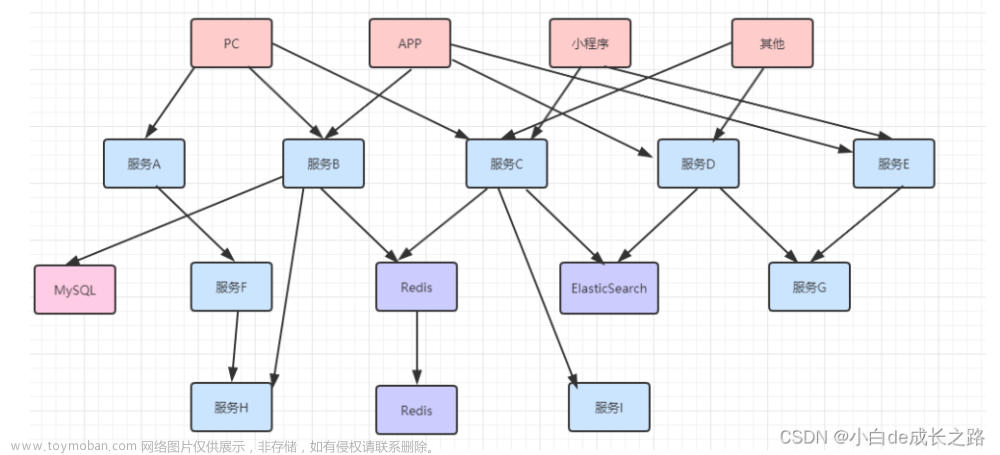
在大型系统的微服务化构建中,一个系统会被拆分成许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种架构中,一次请求往往需要涉及到多个服务。

上图为一个简单的下单系统,里面有n个微服务。现在用户在UI界面下单一个商品,但弹出错误提示"系统内部错误":

此时,开发运维人员要排查异常具体是由哪个微服务引起的就得去逐个看相关的服务日志,效率低下。
3、链路追踪
分布式链路追踪(Distributed Tracing) 就是将一次分布式请求还原成调用链路,进行日志记录、性能监控,并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等,以便帮助开发人员快速定位和解决分布式系统中的性能问题和故障。
链路跟踪主要功能:
-
故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
-
链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
-
链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
☀ 更多参考这篇:http://bigbully.github.io/Dapper-translation/
4、核心概念
概念1:trace
trace是要追踪的一个链路,即一个请求经过所有服务的路径,可以用下面树状的图形表示:

traceid串联起来,就形成了一条完成的链路。
概念2:span
从上面的trace链路可以看到,请求过来调用了服务A,服务A又调用了服务B和服务C,但先调用了B还是C并未标明,因此有了span这个概念。span表达了服务的调用顺序和调用关系。

- 同一层级parent id相同,span id不同,span id从小到大表示请求的顺序,因此服务A是先调用了服务B,再调服务C
- 上下层级代表调用关系,如图中服务C的span id为2,而服务D的parent id为2,这就表示服务C和服务D形成了父子关系,且是服务C调用服务D
到此,通过事先在日志中埋点,找出相同traceId的日志,再加上parent id和span id就可以将一条完整的请求调用链串联起来。
概念3:Annotations
Annotations 用于用户自定义事件,用来辅助定位问题。包含四个注解信息:
- cs:Client Start,表示客户端发起请求
- sr:ServerReceived,表示服务端收到请求
- ss:Server Send,表示服务端完成处理,并将结果发送给客户端
- cr:ClientReceived,表示客户端获取到服务端返回信息

上图中描述了一次请求和响应的过程,四个点也就是对应四个Annotation事件。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的T2 - T1:

概念4:采样
由于每一个请求都会生成一个链路,如果对每一个请求都进行数据采集和存储,性能损耗太大,因此使用采样的方式。比如每秒有1000个请求访问系统,设置了采样率为1/1000,那么只会上报一个请求到存储端。

概念5:埋点
埋点是指将链路追踪的代码插入到应用程序中,以便在应用程序执行期间收集所需的数据。这些数据通常包括系统调用和服务的名称,执行时间,响应时间和错误信息。通过分析这些数据,开发人员可以确定系统中哪些服务或系统调用是性能瓶颈,并确定它们对系统整体性能的影响。
概念6:存储
链路中的span数据经过收集和上报后会集中存储在一个地方,如BigTable数据仓库、ElasticSearch、 HBase、In-memory DB

5、技术选型对比
基于链路追踪的基本原理,各大厂商给出了各自的落地方案,如:
- Twitter的Zipkin
- Uber的Jaeger
- 韩国公司开发的pinpoint
- Apache开源的skywalking
- 阿里的鹰眼
- 美团的Mtrace
- 滴滴Trace
- 新浪的Watchman
- 京东的Hydra
- 大众点评的cat
关于技术选型,各项指标对比:

地址如下:
zipkin -> https://zipkin.io/
Jaeger -> https://www.jaegertracing.io/
Pinpoint -> https://github.com/pinpoint-apm/pinpoint
SkyWalking -> http://skywalking.apache.org/
6、zipkin
Zipkin 是 Twitter 的一个开源项目,基于 Google Dapper 实现,致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。

zipkin架构中,主要四部分:文章来源:https://www.toymoban.com/news/detail-572811.html
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中
- RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等
- Web UI:UI 组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而有直观地查询和分析跟踪信息
参考文章及图片来源:https://zhuanlan.zhihu.com/p/284181372文章来源地址https://www.toymoban.com/news/detail-572811.html
到了这里,关于分布式链路追踪的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!