示例应用介绍
代码:https://github.com/Hugh-yw/kubernetes-example
源码目录结构如下:
$ ls
backend deploy frontend
backend 目录为后端源码,frontend 目录为前端源码,deploy 目录是应用的 K8s Manifest,前后端都已经包含构建镜像所需的 Dockerfile。
示例应用由三个服务组成:
1. 前端;
2. 后端;
3. 数据库。
其中,前端采用 React 编写,它也是应用对外提供服务的入口;后端由 Python 编写;数据库采用流行的 Postgres。
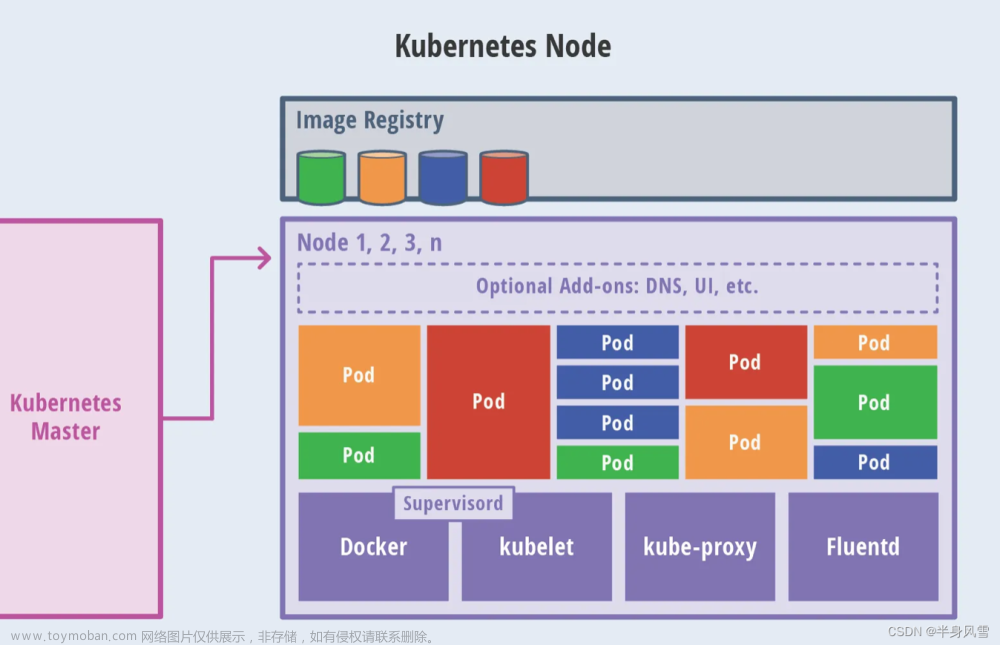
应用整体架构如下图所示:
前端实现了三个功能,分别是存储输入的内容,列出输入内容记录以及删除所有的记录。这三个功能分别对应了后端的三个接口,也就是 /add, /fetch 和 /delete,最后数据会被存储在 Postgres 数据库中。
应用的 K8s 部署架构图如下:
Ingress (Traefik)是应用的入口,Ingress 会根据请求路径将流量分流至前后端的 Service 中,然后 Service 将请求转发给前后端 Pod 进行业务逻辑处理,后端的工作负载 Deployment 配置了 HPA 自动横向扩容。同时,Postgres 也是以 Deployment 的方式部署到集群内的。最后,所有资源都部署在 K8s 的 example 命名空间(Namespace)下。
部署应用到k8s
1.创建ns
$ kubectl create namespace example
2.部署db
$ kubectl create -f https://github.com/Hugh-yw/kubernetes-example/blob/main/deploy/database.yaml -n example
3.部署前后端
$ kubectl create -f https://github.com/Hugh-yw/kubernetes-example/blob/main/deploy/frontend.yaml -n example
$ kubectl create -f https://github.com/Hugh-yw/kubernetes-example/blob/main/deploy/backend.yaml -n example
4.创建ingressroute和hpa
cat front-ingroute.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: frontend-service
spec:
entryPoints:
- web
routes:
- match: Host(`frontend.demo.com`)
kind: Rule
services:
- name: frontend-service
port: 3000
- match: Host(`frontend.demo.com`) && PathPrefix(`/api`)
kind: Rule
services:
- name: backend-service
port: 5000
$ kubectl create -f https://github.com/Hugh-yw/kubernetes-example/blob/main/deploy/hpa.yaml -n example
5.通过域名“frontend.demo.com”访问前端页面,测试新增、删除数据。
如何使用命名空间隔离团队及应用环境?
NameSpace简介
命名空间是集群的一种“软隔离”机制,它通过这种隔离机制,为我们管理和组织集群资源提供了便利。集群和命名空间的关系如图所示:
不同的命名空间具备一定的隔离性,业务应用的工作负载以及其他的 K8s 对象可以部署在特定的命名空间中, 在不同命名空间中,相同类型的资源可以重名。利用这种特性,我们可以把集群虚拟的命名空间和现实中的不同团队、不同应用在逻辑上联系起来。

创建和删除
在一个 K8s 集群中,命名空间可以划分为两种类型:系统级命名空间和用户自定义命名空间。
系统级的命名空间是 K8s 集群默认创建的命名空间,主要用来隔离系统级的对象和业务对象,系统级的命名空间下面四种。
- default:默认命名空间,也就是在不指定命名空间时的默认命名空间。
- kube-system:K8s 系统级组件的命名空间,所有 K8s 的关键组件(例如 kube-proxy、coredns、metric-server 等)都在这个命名空间下。
- kube-public:开放的命名空间,所有用户(包括未经认证)的用户都可以读取,这个命名空间是一个约定,但不是必须。
- kube-node-lease:和集群扩展相关的命名空间。
在这几个命名空间中,除了 default 命名空间,你都不应该将业务应用部署在其他系统默认创建的命名空间下,也不要尝试去删除它们,这可能会导致集群异常。
创建:
kubectl create ns xxx
kubectl create -f test-ns.yaml
删除:
kubectl delete ns xxx
删除命名空间将会删除该命名空间下的所有资源,所以在实际项目中请谨慎操作。另外,由于删除动作是异步的,因此删除中的命名空间状态会由正常的 Active 转变为 Terminating,也就是“终止中的状态”。
什么时候使用命名空间?
当有以下场景需求时,我建议你考虑使用命名空间。
- 环境管理:你可以使用命名空间来隔离开发环境、预发布环境和生产环境。例如用 dev、staging、prod 命名空间来区分这三个环境。命名空间的隔离特性可以让开发环境的的操作不会影响到其他环境的工作。实际上,对于这种情况,我更建议使用不同的集群进行硬隔离,命名空间的隔离方式只是一种选择。
- 隔离: 当你有多个团队,或者多个产品线运行在同一个集群时,你可以使用命名空间来隔离这些团队或者产品线,让他们相互之间不受影响。你甚至可以为每一个开发分配一个命名空间,让他们独立进行开发工作。
- 资源控制: 你可以在命名空间级别配置 CPU、内存等资源配额。通过这个方法,你可以为某个团队或者某条业务线设置总的资源配额,而不需要关注他们具体在每一个工作负载上怎么分配这些资源。此外,命名空间的资源配额还能够合理确保每一个项目所需要的资源配额,避免出现资源恶性竞争导致业务不稳定的情况。
- 权限控制:K8s 的 RBAC 可以帮助我们对某个用户仅授权一个或者多个命名空间,确保只有特定的用户能访问特定命名空间下的资源。
- 提高集群性能: 命名空间有利于提高集群性能。在进行资源搜索时,命名空间有利于 K8s API 缩小查找范围,对减小搜索延迟和提升性能具有一定的帮助。
如何跨命名空间通信?
在使用命名空间隔离资源之后,就会涉及到如何通信的问题。我们之前说命名空间是一种“软隔离”机制,既然是软隔离,那么不同命名空间完全是可以相互通信的。
当 K8s 创建 Service 时,会创建相应的 DNS 解析记录,格式为:<service-name>.<namespace-name>.svc.cluster.local。当业务容器需要和 当前命名空间 下其他服务通信时,则可以省略<namespace-name>.svc.cluster.local,也就是缩写为<service-name>就可以了。
同理,要跨不同的命名空间通信,我们可以指定完整的 Service URL 来实现。例如,要访问 dev 命名空间下的 backend-service,完整的 URL 为:backend-service.dev.svc.cluster.lcoal
如何为业务选择最适合的工作负载类型?
ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、CronJob
如何解决服务发现问题?
service
- ClusterIP
- NodePort
- Loadbalancer
- ExternalName(ClusterIP、NodePort 和 Loadbalancer 类型都是通过 Pod 选择器将 Service 和 Pod 关联起来,然后将请求转发到对应的 Pod 中的。而 ExternalName 类型非常特殊,它不通过 Pod 选择器关联 Pod ,而是将 Service 和另外一个域名关联起来。)
ExternalName 类型的Service Manifest示例:
apiVersion: v1
kind: Service
metadata:
name: backend-service
namespace: default
spec:
type: ExternalName
externalName: backend-service.example.svc.cluster.local
当应用到集群之后,在 default 命名空间下访问 http://backend-serivce:5000 时,
请求将会被转发到 example 命名空间下的 backend-service。会发现虽然目标 Service 和请求发起方不在同一个命名空间下,
但可以通过这种方法屏蔽它们在不同命名空间的调用差异,使得两个服务看起来像是在同一个命名空间下。
此外,当需要通过 Service 名称的方式请求外部服务时,例如请求在集群外的数据库服务,也可以使用这种方法。
如何迁移应用配置?
Kubernetes 应用配置的三种方案:
- Env 环境变量
- ConfigMap
- Secret
其中,Env 可以向 Pod 注入环境变量,使得业务应用在容器内可以直接读取它们。ConfigMap 经常用于为 Pod 注入配置文件,例如 ini、conf、.env 配置文件等。Secret 一般用来向 Pod 注入机密信息,例如第三方应用的 Token 等。
如何将集群的业务服务暴露外网访问?
在 Kubernetes 环境下,对外暴露服务则需要通过 Service 来实现。由于 Service 的 IP 默认是一个集群内的 IP,无法从外部访问,所以需要为 Service 赋予外网 IP 地址。其中,NodePort 类型可以通过 Kubernetes 节点外网 IP + 端口号的方式提供外网访问能力,不过并不推荐在生产环境使用这种方式。
LoadBalancer 类型则需要依赖云厂商的负载均衡器,一般由云厂商实现。在对 Service 配置为 LoadBalancer 类型后,云厂商将会异步创建负载均衡器实例,这种方式将暴露服务和 Kubernetes 节点进行了解耦,是一种常用的服务暴露方式。
不过在生产环境下,也不推荐以 LoadBalancer 的方式暴露所有需要在外网访问的业务服务,因为这不利于统一管理访问流量,并且还要为多个负载均衡器实例支付高昂的费用。为了解决这个问题,强大的社区引入了 Ingress 来暴露服务。
值得注意的是,要使用 Ingress 除了声明 Ingress 对象以外,还需要为集群安装 Ingress-Controller,例如最常见的 Ingress-Nginx、Traefik等。在生产环境下,Ingress-Nginx 正是通过 LoadBalancer 类型的 Service 来自身暴露在公网环境的。
通过 Ingress 暴露服务的方式是我们在生产环境下最常用的方法,同时也是服务暴露的最佳实践。
如何保障业务资源需求和自动弹性扩容?
通过 kubernetes 资源配额来保障业务的资源需求。为工作负载配置资源的请求(Request) 和限制(Limit),可以避免工作负载调度在了资源不足的节点,避免资源相互抢占的问题。值得注意的是,CPU 资源是可压缩资源,而内存则是不可压缩资源。这意味着,如果工作负载接近 CPU 的限制值,它只会出现等待的情况,而当内存出现超限的情况,Pod 将会被杀死并重启。
为工作负载设置资源配额的同时,也会影响工作负载的服务质量(QOS),工作负载的服务质量主要有三种:BestEffort、Burstable 和 Guaranteed。当节点资源不足时,kubernetes 会按照这个顺序依次对 Pod 进行驱逐。
在生产环境下,推荐为每一个工作负载都配置资源配额,尤其是对一些重要的中间件和核心服务,应当为它们配置足够的资源配额,并将 Request 和 Limit 配置为相等的值,保障它的服务质量。而对于有明显资源高低峰的业务(例如 Java 应用),它的特点是在启动时消耗的资源较高,但运行时消耗的资源会趋近平稳,所以可以将 Request 配置为启动后的资源消耗,Limit 配置为启动时所需的资源消耗,在确保业务所需资源的同时,这样做还能提高系统整体的资源利用率。
为业务配置水平扩容(HPA)策略。HPA 可以基于 CPU 和内存指标对 Pod 进行横向扩缩容,同时也是保障业务可用性的重要手段。当然,HPA 除了使用内置的 CPU 和内存以外,还可以配置自定义指标,结合一些开源项目甚至能通过外部事件来触发扩缩容.
如何自动检查业务真实的健康状态?
背景:
如果业务应用没有做好垃圾回收或者产生死锁,那么再运行一段时间后,它的内存和 CPU 消耗会迅速飙升。显然,这时候 Pod 已经处于不健康状态了,怎么让 kubernetes 识别并将它重启呢?
这时就需要使用到 kubernetes 的健康检查特性。
kubernetes 的三种健康检查探针。其中,Readiness 就绪探针可以让 kubernetes 感知到业务的真实可用状态,kubernetes 将根据业务的状态判断 Pod 是否处于 Ready 就绪状态,以此来控制什么时候将 Pod 加入到 EndPoints 列表中接收外部流量。
Liveness 存活探针则更加彻底,当它感知到 Pod 不健康时,会重启 Pod。在大多数情况下,Liveness 可以实现对业务无感的服务重启,在第一时间发现故障的同时自动恢复业务,极大提升了业务系统的可用性。
StartupProbe 探针主要用来解决服务启动慢的问题,对于一些大型的应用例如 Java 服务,我建议你为它们配置 StartupProbe,以确保在服务启动完成后再对它进行常规的就绪和存活健康检查。文章来源:https://www.toymoban.com/news/detail-573100.html
在实际的业务场景中,强烈建议为业务工作负载配置这三种探针,这样可以最大程度地保障业务的高可用和稳定性。文章来源地址https://www.toymoban.com/news/detail-573100.html
到了这里,关于【GitOps系列】K8s极简实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!