原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
前言
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
消息队列是一种中间件 ,用于在不同的组件或系统之间传递消息(进程间通讯的一种)。 它提供了一种可靠的机制(AMQP)来存储和传递消息,并确保消息的顺序性和可靠性。消息队列需要存储消息。
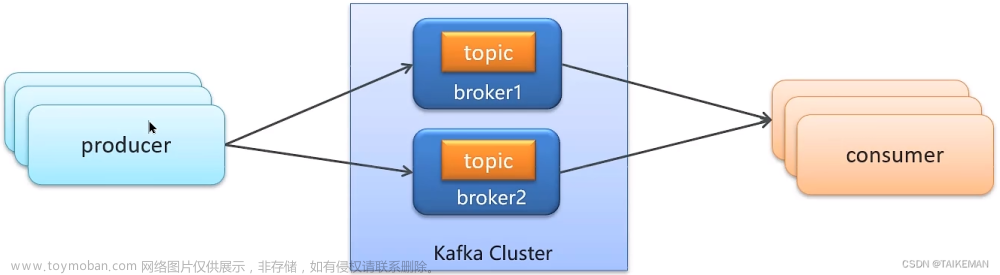
Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。Kafka是一个分布式消息队列:生产者、消费者的功能。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
一、Kafka安装
1.下载并安装Java
Kafka 是基于 Java 开发的,因此需要先安装 Java 环境。如果你已经安装了 Java 环境,可以跳过这一步。
在命令行中输入以下命令:
sudo apt-get update
# linux命令行下,安装jdk
sudo apt-get install openjdk-8-jdk
# 查看安装结果
java -version
2.下载和解压 Kafka
下载 Kafka 压缩包,并解压到 /opt 目录下。
cd ~
sudo wget https://archive.apache.org/dist/kafka/3.4.0/kafka_2.13-3.4.0.tgz
sudo tar -xzf kafka_2.13-3.4.0.tgz
cd /opt
sudo mv cd ~/kafka_2.13-3.4.0 kafka
3.配置 Kafka
接下来需要更改 Kafka 的配置文件。打开 config/server.properties 文件,并进行以下更改:
sudo vim /opt/kafka/config/server.properties
advertised.listeners=PLAINTEXT://<your-server-IP-address>:9092
listeners=PLAINTEXT://0.0.0.0:9092
确保将 <your-server-IP-address> 替换为实际的服务器 IP 地址。(ifconfig查看本机ip)
4.启动 Kafka
Kafka 启动有两种方式:单机模式和分布式模式。
- 单机模式
在单机模式下,Kafka 只有一个 broker。在命令行中输入以下命令:
cd /opt/kafka
sudo /opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties # 在一个窗口,或后台运行
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties # 另起一个窗口,或后台运行
- 分布式模式
在分布式模式中,Kafka 包含多个 broker。在命令行中输入以下命令:
首先,编辑 config/server.properties 文件,设置以下属性:
broker.id=0 # 设置当前 broker 的 id,不能重复
listeners=PLAINTEXT://your.server.ip.address:9092 # 设置监听地址和端口
log.dirs=/tmp/kafka-logs # 设置日志目录
复制 broker.id=0 的行,修改 broker.id 的值,设置多个 broker 的 id。
接下来,启动 ZooKeeper:
cd /opt/kafka
sudo /opt/kafka/bin/zookeeper-server-start.sh config/zookeeper.properties
最后,每个 broker 启动 Kafka:
cd /opt/kafka
sudo /opt/kafka/bin/kafka-server-start.sh config/server.properties
5.创建主题和生产者/消费者
可以使用 Kafka 自带的命令行工具创建主题、发送消息和消费消息。
- 创建主题
cd /opt/kafka
sudo /opt/kafka/bin/kafka-topics.sh --create --bootstrap-server your.server.ip.address:9092 --replication-factor 1 --partitions 1 --topic test-topic
- 查看
sudo /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
- 删除
sudo /opt/kafka/bin/kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic test-topic
6.发布和订阅消息
现在已经成功地部署了 Kafka,并创建了一个 topic。可以使用以下命令在 topic 中发布和订阅消息:
发布消息:# 另起一个窗口
sudo /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
订阅消息:# 另起一个窗口
sudo /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning
以上是在 Ubuntu 上部署 Kafka 的基本步骤,你可以根据实际情况进行修改。
二、Kafka+Django生产和消费
confluent-kafka 和kafka-python是python中处理kafka的三方包,这里以confluent-kafka为例。
pip install confluent-kafka
1.Django配置文件
在settings.py中加入配置
KAFKA_SETTINGS = {
'bootstrap.servers': 'localhost:9092', # localhost替换为kafka服务的ip
'group.id': 'mygroup',
'auto.offset.reset': 'earliest',
}
2.通过django命令实现消费
- kafka消费处理kafka_consumer.py文件
from confluent_kafka import Consumer, KafkaError
from django.conf import settings
def kafka_handler():
c = Consumer(settings.KAFKA_SETTINGS)
c.subscribe(['test-topic'])
while True:
msg = c.poll(1.0)
print(111,msg)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
print('End of partition reached')
else:
print('Error: {}'.format(msg.error()))
else:
print('Received message: {}'.format(msg.value()))
-
使用django的startapp新增kafka对app
cd ptoject # manage.py的同级目录 django-admin startapp kafka python manage.py startapp kafka -
在django配置文件settings中添加kafka至INSTALLED_APPS
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'kafka' ] -
自定义django命令
可以参看这个链接:https://www.osgeo.cn/django/howto/custom-management-commands.html在kafka下新建 management/commands二级文件夹

其中kafka_consumer是第一步创建的消费处理程序,my_消费是我们自定义的django命令程序。my_消费.py的内容如下:
# -*- coding:utf-8 _*-
"""
@author:Administrator
@file: my_消费.py
@time: 2023/7/16 0016 12:32
"""
from django.core.management.base import BaseCommand, CommandError
from kafka_consumer import kafka_handler
class Command(BaseCommand):
help = 'Closes the specified poll for voting'
def handle(self, *args, **options):
kafka_handler()
- 启动消费命令
切换至虚拟环境,目录切换至django项目目录,及mnange.py的同级目录。
python manage.py my_消费


3.通过Django生产

- 创建kafka_producer.py生产文件
# -*- coding:utf-8 _*-
"""
@author:Administrator
@file: kafka_producer.py
@time: 2023/7/16 0016 12:28
"""
from confluent_kafka import Producer
from django.conf import settings
def send_message(message):
p = Producer({'bootstrap.servers': settings.KAFKA_SETTINGS.get('bootstrap.servers')})
topic = 'test-topic'
p.produce(topic, message.encode('utf-8'))
p.flush()
if __name__ == '__main__':
send_message('测试')
- 通过django命令生产消息
这里还是用的自定义命令,自定义文件为my_消费.py
# -*- coding:utf-8 _*-
"""
@author:Administrator
@file: my_消费.py
@time: 2023/7/16 0016 12:32
"""
from django.core.management.base import BaseCommand, CommandError
from kafka_producer import send_message
class Command(BaseCommand):
help = 'Closes the specified poll for voting'
def handle(self, *args, **options):
send_message('111')

启动方式与消费一样,python manage.py my_生产文章来源:https://www.toymoban.com/news/detail-573315.html
- 通过django程序生产消息
kafka_producer文件中的send_message方法可以在程序中被调用,我们在处理用户请求时,可以通过异步的方式处理send_message。文章来源地址https://www.toymoban.com/news/detail-573315.html
到了这里,关于【Kafka】Ubuntu 部署kafka中间件,实现Django生产和消费的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!