- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主
- 📕系列专栏:Java设计模式、Spring源码系列、Netty源码系列、Kafka源码系列、JUC源码系列、duubo源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀

一、引言
兄弟们,上次的故障结果出来了
还好销售团队给力,没有让客户几千万的单子丢掉,成功挽回了本次损失
不过内部处罚还是相对严重,年终奖悬了

这也告诫我们 要对生产保持敬畏之情!
恰巧最近领导看我在写 Dubbo 源码系列,看到我们的项目中用了 SPI 扩展
于是给我一个将功补过的机会,让我好好的分析分析 Dubbo 的 SPI 的扩展机制,进行组内技术分享
作为一个常年分享 源码系列 文章的选手,当然不会拒绝!
乾坤未定,你我皆是黑马,冲!
二、SPI是什么
SPI 全称 Service Provider Interface ,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。

Java SPI 实际上是 基于接口的编程+策略模式+配置文件 组合实现的动态加载机制。
Java SPI 就是提供这样的一个机制:为某个接口寻找服务实现的机制。
将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
所以 SPI 的核心思想就是解耦。
三、使用介绍
我们定义一个接口:City
@SPI
public interface City {
String getCityName();
}
实现其两个类:
- BeijingCity
public class BeijingCity implements City{
@Override
public String getCityName() {
return "北京";
}
}
- TianjinCity
public class TianjinCity implements City{
@Override
public String getCityName() {
return "天津";
}
}
重点来了:我们要在 resources 文件夹下面建立一个路径:META-INF/dubbo
然后我们建立一个 txt 名为:com.dubbo.provider.SPI.Dubbo.City,如下:
我们在这个文件中写上各实现类的路径:
beijing=com.dubbo.provider.SPI.Dubbo.BeijingCity
tianjin=com.dubbo.provider.SPI.Dubbo.TianjinCity
有的朋友可能会问,这里为什么和 Java SPI 的实现不同?
这也正是 Dubbo 实现精准实例化的原因,我们后面也会聊到
测试方法:
public class DubboSPITest {
public static void main(String[] args) {
ExtensionLoader<City> loader = ExtensionLoader.getExtensionLoader(City.class);
City tianjin = loader.getExtension("beijing");
System.out.println(tianjin.getCityName());
}
}
测试结果:
北京
从这里我们可以看出,Dubbo 可以通过 loader.getExtension("beijing") 精确的生成我们需要的实例
精确生成是如何实现的呢?我们继续往下看
四、原理介绍
在源码介绍之前,我们先说几个原理细节,防止大家后面的源码看迷糊
1、SPI注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* default extension name
*/
String value() default "";
/**
* scope of SPI, default value is application scope.
*/
ExtensionScope scope() default ExtensionScope.APPLICATION;
}
在 SPI 注解中,存在两个参数:value、scope
value
- 作用:如果某个
SPI扩展没有指定实现类名称,则会使用@SPI注解中指定的默认值
scope:指定 SPI 扩展实现类的作用域( Constants.SINGLETON)
-
Constants.FRAMEWORK(框架作用域):实现类在Dubbo框架中只会创建一个实例,并且在整个应用程序中共享。 -
Constants.APPLICATION(应用程序作用域):实现类在应用程序上下文中只会创建一个实例,并且在整个应用程序中共享。 -
Constants.MODULE(模块作用域):实现类在模块上下文中只会创建一个实例,并且在整个模块中共享。 -
Constants.SELF(自定义作用域):实现类的作用范围由用户自行定义,可以是任何范围。
当然,这里 Dubbo 默认的是 Constants.APPLICATION,我们也只需要关注这个即可。
五、源码剖析
1、Loader的创建
我们 Dubbo 的 SPI 从 ExtensionLoader.getExtensionLoader(City.class) 开始,看一看其实现方案
public <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
// 1、校验
checkDestroyed();
// 2、是否有本地Loader缓存
ExtensionLoader<T> loader = (ExtensionLoader<T>) extensionLoadersMap.get(type);
// 3、是否有本地Scope缓存
ExtensionScope scope = extensionScopeMap.get(type);
// 4、如果当前的Scope为空
// 4.1 获取当前接口类的SPI注解
// 4.2 获取当前注解的scope
// 4.3 放入scope缓存
if (scope == null) {
SPI annotation = type.getAnnotation(SPI.class);
scope = annotation.scope();
extensionScopeMap.put(type, scope);
}
// 5、如果加载器为空且当前是SELF,直接创建loader
if (loader == null && scope == ExtensionScope.SELF) {
loader = createExtensionLoader0(type);
}
// 6、如果当前加载器为空,去父类找加载器
if (loader == null) {
if (this.parent != null) {
loader = this.parent.getExtensionLoader(type);
}
}
// 7、如果父类也没有实例化,那么实例化并放入缓存
if (loader == null) {
loader = createExtensionLoader(type);
}
// 8、返回加载器
return loader;
}
从上面的源码我们可以看到,获取 ExtensionLoader 采用了 缓存 + 父类继承 的模式
这种继承机制设计得比较巧妙,可以避免重复加载类,提高系统性能。
2、获取实例
Dubbo 通过 loader.getExtension("tianjin") 获取对应的实例
public T getExtension(String name) {
T extension = getExtension(name, true);
return extension;
}
public T getExtension(String name, boolean wrap) {
// 1、校验
checkDestroyed();
// 2、参数为true,表明采用默认的实现类
// 2.1 我们上面SPI中的value参数,若指定tianjin,则采用tianjin的实现类
if ("true".equals(name)) {
return getDefaultExtension();
}
String cacheKey = name;
if (!wrap) {
cacheKey += "_origin";
}
// 3、查看当前缓存中是否含有该实例
// 3.1 如果当前的cacheKey没有Holder的话,创建一个
final Holder<Object> holder = getOrCreateHolder(cacheKey);
// 4、如果实例为空,采用DCL机制创建实例
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}
private Holder<Object> getOrCreateHolder(String name) {
// 1、获取当前name的Holder
Holder<Object> holder = cachedInstances.get(name);
// 2、没有则创建并扔进缓存
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
holder = cachedInstances.get(name);
}
// 3、返回
return holder;
}
Holder 类是一个简单的容器类,用于保存某个对象的引用
在 Dubbo 的 ExtensionLoader 类中,Holder 类被用于实现对 SPI 扩展实现类的缓存
Holder 结构如下:
public class Holder<T> {
private volatile T value;
public void set(T value) {
this.value = value;
}
public T get() {
return value;
}
}
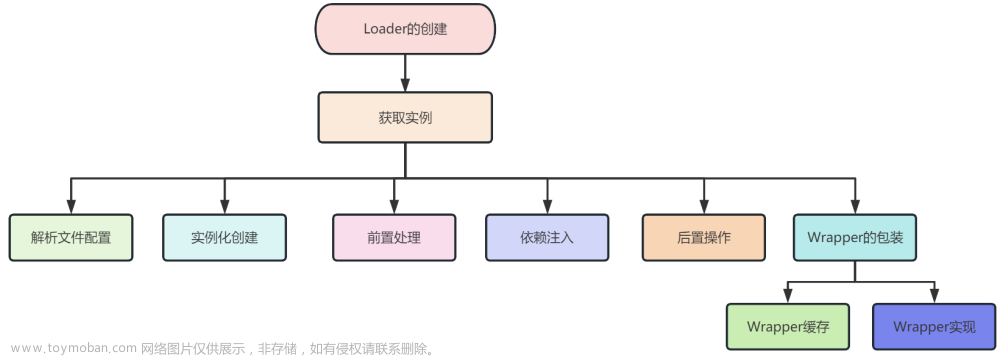
我们创建实例一共有以下几部分:
- 解析文件配置得到对应的类
- 通过实例化创建相关的类
- 初始化之前前置操作
- 依赖注入
- 初始化之后后置操作
-
Wrapper的包装 - 是否具有生命周期管理的能力
我们挨个的讲解
2.1 解析文件配置
Class<?> clazz = getExtensionClasses().get(name);
private Map<String, Class<?>> getExtensionClasses() {
// 1、从缓存中获取类的信息
Map<String, Class<?>> classes = cachedClasses.get();
// 2、DCL创建(经典的单例设计模式)
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
// 3、加载类信息并放至缓存中
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException {
// 1、校验
checkDestroyed();
// 2、是否有默认的类
// 2.1 我们之前聊过的SPI注解的value机制
cacheDefaultExtensionName();
// 3、这里有三个文件解析器
// 3.1 DubboInternalLoadingStrategy:解析META-INF/dubbo/internal/
// 3.2 DubboLoadingStrategy:解析META-INF/dubbo/
// 3.3 ServicesLoadingStrategy:解析META-INF/services/
// 3.4 解析文件并放至缓存
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy, type.getName());
if (this.type == ExtensionInjector.class) {
loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());
}
}
// tianjin:"class com.msb.dubbo.provider.SPI.Dubbo.TianjinCity"
// beijing:"class com.msb.dubbo.provider.SPI.Dubbo.BeijingCity"
return extensionClasses;
}
2.2 实例化创建
// 1、从缓存中获取
T instance = (T) extensionInstances.get(clazz);
if (instance == null) {
// 2、缓存为空则创建并放至缓存
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
instance = (T) extensionInstances.get(clazz);
}
// 1、获取当前类的所有的构造方法
// 2、判断是否有符合的构造方法,若没有则报错
// 3、有符合的构造犯法,返回即可
private Object createExtensionInstance(Class<?> type) throws ReflectiveOperationException {
return instantiationStrategy.instantiate(type);
}
2.3 前置处理
类似 Spirng 的前置处理器,之前也说过,感兴趣的可以看一下,整体思路区别不大
instance = postProcessBeforeInitialization(instance, name);
private T postProcessBeforeInitialization(T instance, String name) throws Exception {
if (extensionPostProcessors != null) {
for (ExtensionPostProcessor processor : extensionPostProcessors) {
instance = (T) processor.postProcessBeforeInitialization(instance, name);
}
}
return instance;
}
2.4 依赖注入
- 首先,如果依赖注入器为 null,则直接返回传入的实例。
- 然后,遍历传入实例的所有方法,找到所有的 setter 方法。
- 对于每个
setter方法,如果标注了@DisableInject注解,则跳过该方法,不进行注入。 - 如果
setter方法的参数类型是基本类型,则跳过该方法,不进行注入。 - 如果
setter方法的参数类型不是基本类型,则尝试从依赖注入器中获取该类型对应的实例,并调用该setter方法进行注入。 - 如果获取实例失败,则记录错误日志。
- 最后,返回注入后的实例。
injectExtension(instance);
private T injectExtension(T instance) {
for (Method method : instance.getClass().getMethods()) {
// 1、如果不是setter方法,直接跳过
if (!isSetter(method)) {
continue;
}
// 2、包含了DisableInject注解,直接跳过
if (method.isAnnotationPresent(DisableInject.class)) {
continue;
}
if (method.getDeclaringClass() == ScopeModelAware.class) {
continue;
}
// 3、如果是基本数据类型,跳过
if (instance instanceof ScopeModelAware || instance instanceof ExtensionAccessorAware) {
if (ignoredInjectMethodsDesc.contains(ReflectUtils.getDesc(method))) {
continue;
}
}
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// 4、依赖注入器中获取该类型对应的实例,并调用该 setter 方法进行注入
// 4.1 这里直接拿取的ListableBeanFactory->DefaultListableBeanFactory
String property = getSetterProperty(method);
Object object = injector.getInstance(pt, property);
// 5、将当前的对象注入到实例里面
if (object != null) {
method.invoke(instance, object);
}
}
return instance;
}
2.5 后置操作
- 类似
Spirng的后置处理器,之前也说过,感兴趣的可以看一下,整体思路区别不大
instance = postProcessAfterInitialization(instance, name);
private T postProcessAfterInitialization(T instance, String name) throws Exception {
if (instance instanceof ExtensionAccessorAware) {
((ExtensionAccessorAware) instance).setExtensionAccessor(extensionDirector);
}
if (extensionPostProcessors != null) {
for (ExtensionPostProcessor processor : extensionPostProcessors) {
instance = (T) processor.postProcessAfterInitialization(instance, name);
}
}
return instance;
}
2.6 Wrapper 的包装
2.6.1 Wrapper缓存
在讲该部分之前,我们先来看 cachedWrapperClasses 这个缓存的来历:
在我们上面解析文件配置时,会进行 loadClass,这里不仅会解析正常的类,也会解析 Wrapper 类,方便后面的包装
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,boolean overridden) {
if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
}
}
从这里我们可以看到,最关键的当属判断当前的 Class 是不是属于 WrapperClass
protected boolean isWrapperClass(Class<?> clazz) {
// 1、获取构造方法
Constructor<?>[] constructors = clazz.getConstructors();
// 2、从构造方法中取出参数为 1 且类型等于当前接口的
for (Constructor<?> constructor : constructors) {
if (constructor.getParameterTypes().length == 1 && constructor.getParameterTypes()[0] == type) {
return true;
}
}
return false;
}
而具体的实现如下:
public class CityWrapper implements City{
private City city;
// 怎样判断扩展点还是aop切面呢?
// 通过是否有这样的一个构造方法来判断
public CityWrapper(City city) {
this.city = city;
}
@Override
public String getCityName() {
return "文明城市" + city.getCityName();
}
}
了解这个之后,我们再来看看 Dubbo 如何处理这些类似 AOP 的包装
2.6.2 Wrapper实现
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
// 1、判断是否有Wrapper缓存
// 1.1 将缓存放入当前
// 1.2 排序 + 翻转
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
// 2、当前的wrapper缓存不为空
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
// 循环包装
for (Class<?> wrapperClass : wrapperClassesList) {
// 3、获取Wrapper注解,是否需要包装(正常都是包装的)
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
// 4、判断下是否包装条件
boolean match = (wrapper == null) ||
((ArrayUtils.isEmpty(wrapper.matches()) || ArrayUtils.contains(wrapper.matches(), name)) &&
!ArrayUtils.contains(wrapper.mismatches(), name));
// 5、符合包装
// 5.1 将当前类封装至wrapper中
// 5.2 做一些后置处理
if (match) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
}
}
通过这种方式,我们可以创建不同的 wrapper,实现 AOP 的作用
读过 从源码全面解析 dubbo 服务端服务调用的来龙去脉 和 从源码全面解析 dubbo 消费端服务调用的来龙去脉 的文章,这时候应该理解最后的那些 过滤器 怎么实现的了
比如,我们现在有两个 wrapper 类,分别是 CityWrapper 和 CityWrapper2,实现类是 TianjinCity
那么,我们最终 TianjinCity 返回的实例如下:
- CityWrapper
- CityWrapper2
- TianjinCity
- CityWrapper2

不得不说,这个包装还是有点秀秀的
2.7 生命周期管理
- 实现
Lifecycle的接口
initExtension(instance);
六、流程图
高清图片私聊博主获取
七、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构 和 中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,喜欢后端架构和中间件源码。
我们下期再见。
我从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。文章来源:https://www.toymoban.com/news/detail-574041.html
往期文章推荐:文章来源地址https://www.toymoban.com/news/detail-574041.html
- 美团二面:聊聊ConcurrentHashMap的存储流程
- 从源码全面解析Java 线程池的来龙去脉
- 从源码全面解析LinkedBlockingQueue的来龙去脉
- 从源码全面解析 ArrayBlockingQueue 的来龙去脉
- 从源码全面解析ReentrantLock的来龙去脉
- 阅读完synchronized和ReentrantLock的源码后,我竟发现其完全相似
- 从源码全面解析 ThreadLocal 关键字的来龙去脉
- 从源码全面解析 synchronized 关键字的来龙去脉
- 阿里面试官让我讲讲volatile,我直接从HotSpot开始讲起,一套组合拳拿下面试
到了这里,关于趁同事上厕所的时间,看完了 Dubbo SPI 的源码,瞬间觉得 JDK SPI 不香了的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!