Es内置的分词器有 standard、pattern、whitespace、stop等等;也可以下载ik插件,使用ik_smart 和 ik_max_word。网上也有很多相关文章,这里就不介绍了。
我总结了一下 SpringBoot 自定义 正则分词器 的方法,其他的类似。
1. 首先创建一个 setting.json 文件,放到 resources 目录下,用于自定义分词器。
配置文件名随意,我这里命名为settings.json,作用是将 url 中的 . 替换成 -
{
"analysis": {
"analyzer": {
"url_analyzer": {
"tokenizer": "standard",
"char_filter": [
"url_char_filter"
]
}
},
"char_filter": {
"url_char_filter": {
"type": "pattern_replace",
"pattern": "\\.",
"replacement": "-"
}
}
}
}
2. 在实体类上加 @Setting 注解,填写settings.json的路径(由于我直接放到了resource目录下,所以路径直接填settings.json)

3. 在对应的字段上,添加注解 @Field 就OK了(也可以手动配置mapping文件,我这里用注解的方式)

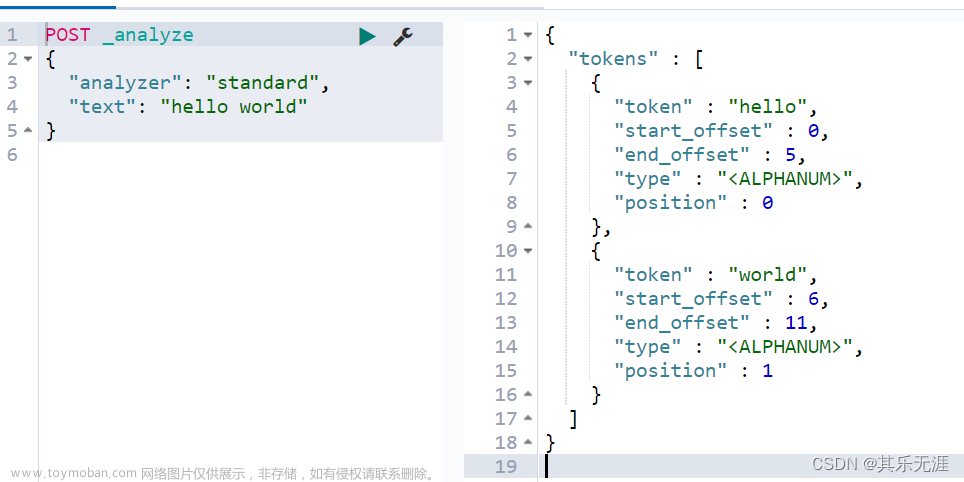
4. 看一下效果
使用standard分词器,url没有被分词 文章来源:https://www.toymoban.com/news/detail-574714.html
文章来源:https://www.toymoban.com/news/detail-574714.html
使用自定义的正则分词器,可以看到url已经被分词 文章来源地址https://www.toymoban.com/news/detail-574714.html
文章来源地址https://www.toymoban.com/news/detail-574714.html
到了这里,关于SpringBoot整合ElasticSearch自定义分词器Analyzer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!