
论文:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
在线体验:https://huggingface.co/Salesforce/blip2-opt-2.7b
出处:Salesforce Research | 和 BLIP 是同一团队
时间:2023.01
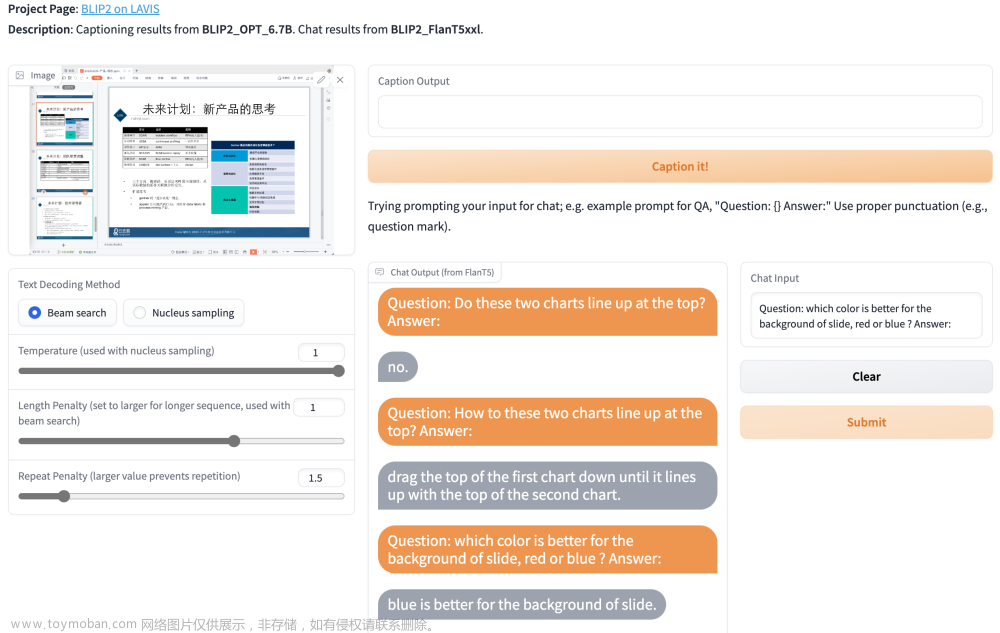
线上体验示例:将图拖拽至此即可生成对图像的描述

贡献:
- 提出了 BLIP-2: Bootstrapping Language-Image Pre-training,能够借助训练好的视觉模型和语言模型来实现高效的 vision-language pre-training
- 提出了轻量级的 Q-Former,使用两阶段训练 Q-Former 的方式,在冻结 image model 和 LLM 进行预训练的同时在它们之间建立一个桥梁。第一阶段是 representation learning,让 Q-Former 学习和文本更相关的视觉特征,第二阶段是 generative learning,实现使用 LLM 来解释 Q-Former 输出的视觉特征
- BLIP-2 可以实现零样本的 image-to-text 生成
一、背景
Vision-Language Pre-training(VPL)在最近几年取得了很大的进展,也为很多下游任务带了了更多的提升。
但现有的 SOTA VPL 模型的 pre-training 依赖于超大模型和超大数据集,非常耗时
Vision-Language 的相关研究主要集中于 vision 和 language 的交叉点上,所以人们很自然的期望该模型能够从现有的单模态视觉或单模态语言模型上获得一些提升
本文中,作者提出了一种通用且高效的 VLP 方法,能够从现成的预训练好的视觉和语言模型中得到提升
为了降低计算量且避免再重新训练时单模态模型遗忘之前学习到的东西,所以在预训练的时候会冻结预训练好的单模态模型
一个很关键的地方就在于促进不同模态之间的校准,但由于大语言模型 LLM 在训练的时候并没有见过图像,简单的冻结参数可能无法达到预期的效果,现有的方法是通过使用 image-to-text 生成 loss 来解决的,但本文证明这种方法难以很好的弥补其中的 gap
为了在冻结单模态模型的同时实现高效的 vision-language 对齐,作者提出了 Querying Transformer(Q-Former),并且使用 two-stage pre-training 的方式来训练 Q-Former
如图 1 所示,Q-Former 非常轻量,且能够使用一系列可学习的 query vectors 来从冻结的 image encoder 中提取和文本更相关的视觉特征
Q-Former 可以看做是 frozen image encoder 和 frozen LLM 之间的信息传输模块

二、方法
2.1 模型结构
为了实现在冻结单模态模型参数的情况下进行模型的多模态训练,作者提出了 Q-Former 来弥补两种不同的模态之间的 gap
Q-Former 能够从 image encoder 中提取出固定数量的输出特征(与输入图像的分辨率无关)
如何两阶段训练 Q-Former:
-
第一阶段: vision-language representation learning stage with a frozen image encoder
能够强制让 Q-Former 学习更和文本相关的视觉表达信息
-
第二阶段: vision-to-language generative learning stage with a frozen LLM
通过将 Q-Former 的输出和 frozen LLM 连接起来实现 vision-to-language 生成式学习,所要实现的目标是能用 LLM 来解释 Q-Former 的输出视觉表达特征

如图 2 所示,Q-Former 由两个 transformer 子模型组成,且两个子模型共享 self-attention layers:
- image transformer:和 frozen image encoder 进行交互,来抽取视觉特征
- text transformer:同时有 text encoder 和 text decoder 的作用
Q-Former 如何工作:
- 首先建立一组可学习的 query embedding 作为 image transformer 的输入
- queries 之间会通过 self-attention 来进行交互,也能通过 cross-attention 和 frozen image feature 进行交互
- queries 可以通过 self-attention layer 和 text 进行交互
- 基于不同的预训练任务, 作者会使用不同的 self-attention mask 来控制 query-text 之间的交互
- Q-Former 使用 BERT_base 进行初始化,cross-attention layers 的参数是随机初始化的
- Q-Former 共包含 188M 参数
- 在实验中,作者使用了 32 queries,每个 query 有 768 维,使用 Z 来定义输出 query representation, Z ( 32 × 768 ) Z(32 \times 768) Z(32×768) 的尺寸远远小于 frozen image feature 的尺寸(ViT-L/14 是 256x1024)
- 该结构能够和目标函数一起促进 query 来提取更和 text 相关的视觉信息
2.2 从 frozen image encoder 中自主学习 Vision-Language Representation
在 representation 学习阶段的训练方法:
- 作者将 Q-Former 和 frozen image encoder 结合起来
- 并且使用 image-text pairs 来进行预训练
为了训练 Q-Former 来实现 queries 能够抽取出包含对应文本信息的 visual representation,参考 BLIP,作者同时优化了三个目标函数,每个 objective 在 queries 和 text 之间使用不同的 attention mask strategy,用于控制其交互,如图 2 所示
1、Image-Text Contrastive Learning (ITC):学习将 image 特征和 text 特征进行对齐,使他们的交互信息最大化
-
实现方式:使用对比学习,学习 image-text 的相似度,positive pairs 的相似性大于 negative pairs 的相似性
-
t t t :text transformer 的 [CLS] token 的输出 representation,包含多个输出编码(一个 query 对应一个编码)
-
Z Z Z:image transformer 的 输出 query representation
-
计算每个 query output 和 t 的 相似度,选择相似度最高的作为 image-text similarity,为了避免信息泄露,作者还使用了单模态 self-attention mask,queries 和 text 不能看到对方
-
由于 image encoder 是被冻结的,所以相比于端到端训练,冻结的方式能够在每个 GPU 上放更多的样本,所以本方法使用的 in-batch negatives 而非 momentum queue(BLIP)
2、Image-grounded Text Generation (ITG):训练 Q-Former 来生成 text,输入的图像作为条件
- 由于 Q-Former 不允许 frozen image encoder 和 text image encoder 的直接交互
- 但生成 text 的基础信息是来源于 query 抽取到的图像信息
- 所以,query 需要能够抽取关于 text 内容的所有的图像信息
- 作者使用多模态 causal self-attention mask 来控制 query-text 的交互,类似于 UniLM,query 可以和其他 query 以及出现在它前面的 text token 进行交换,同时也是要 [DEC] token 替换了 [CLS] token 作为第一个 text toden 来标记 decoding 任务
3、Image-Text Matching (ITM):用于学习 image-text 之间更细粒度的对齐
- 该任务时一个二值分类任务,用于预测一个 image-text pairs 是 positive(matched)还是 negative(unmatched)
- 作者使用 bi-directional self-attention mask,该 mask 的形式允许所有 query 和 text 进行交互
- 输出 query embedding Z Z Z 能够捕捉多模态信息
- 将每个输出 query embedding 输入二分类的线性分类器,来获得一个 logit,并且将 logit 平均后作为输出的 matching score
- 此外,作者也使用了负难例挖掘,来提取出难的 negative pairs
2.3 使用 Frozen LLM 来自主学习 Vision-to-Language 生成

在生成任务的预训练阶段,作者将 Q-Former(已经基于 frozen image encoder 预训练过的)和 frozen LLM 进行结合,来获得 LLM 的语言生成能力
如图 3 所示:
- 首先,使用全连接层来对 output query embedding Z Z Z 进行线性映射,将其映射为何 LLM 的text embedding 相同的维度
- 映射后的 query embedding 放到 text embedding 的前面
- 将其作为 soft visual prompts 的功能,使用 Q-Former 提取出的视觉信息来过滤 LLM
2.4 Model pre-training
1、预训练数据
使用和 BLIP 相同的 129M 预训练数据,包括 COCO、Visual Genome、CC3M、 CC12M、SBU、 LAION400M 中的 115M 数据
并且使用了 CapFilt 方法来对 web images 合成的描述
使用 BLIP_large 模型生成了 10 个描述,并且根据由 CLIP 产生的 image-text 相似度来对这 10 个描述进行排序,给每个 image 保留前两个描述,然后随机选择一个来进行预训练
2、预训练 image encoder 和 LLM
作者使用两个 SOTA 预训练 vision transformer:
- ViT-L/14 from CLIP
- ViT-G/14 from EVA-CLIP
- 移除了 ViT 的最后一层,使用倒数第二层的特征作为输出特征,这会获得更好的效果
对 frozen language model,使用无监督训练的 OPT 来训练 decoder-based LLM ,使用 FlanT5 来训练 encoder-decoder-based LLM
3、设置
224x224 图像大小
三、效果
1、带指令零样本 image-to-text 生成
BLIP-2 能够高效的使用 LLM 理解图像的同时,且保留 text prompt 的能力,就能够使用指令来指导 image-to-text 的生成
如图 4 所示,展示了一些例子

零样本 VQA:


Vision-Language 特征表达的学习效率:

2、为图像产生文本描述,Image Captioning:

3、visual question answering

4、图文检索


四、局限性
BLIP-2 的 image-to-text 生成任务可能不是很能令人满意,原因可能来自于 LLM 的认知不准确、或没有关于新图像的更新,此外,由于冻结了模型,BLIP-2 可能继承到 LLM 的风险。

 文章来源:https://www.toymoban.com/news/detail-575057.html
文章来源:https://www.toymoban.com/news/detail-575057.html
 文章来源地址https://www.toymoban.com/news/detail-575057.html
文章来源地址https://www.toymoban.com/news/detail-575057.html
到了这里,关于【多模态】6、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[BLIP]-多模态Language-Image预训练模型](https://imgs.yssmx.com/Uploads/2024/02/451104-1.png)








