文章来源地址https://www.toymoban.com/news/detail-575549.html
文章来源:https://www.toymoban.com/news/detail-575549.html
到了这里,关于【技能实训】DMS数据挖掘项目-Day11的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了【技能实训】DMS数据挖掘项目-Day11。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-575549.html
文章来源:https://www.toymoban.com/news/detail-575549.html
到了这里,关于【技能实训】DMS数据挖掘项目-Day11的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

数据来自Kaggle的Give Me Some Credit,有15万条的样本数据,网上的分析说明有很多,本人结合其他大佬的方法,对数据进行细致的分析,主要分析在EDA环节,之后尝试使用toad这个评分卡的库,以及使用quct结合卡方检验分箱的方法,使用AUC和KS,结合交叉验证对比分析哪个效果更好

本文数据集来自阿里天池:https://tianchi.aliyun.com/competition/entrance/231784/information 主要参考了Datawhale的整个操作流程:https://tianchi.aliyun.com/notebook/95460 小编也是第一次接触数据挖掘,所以先跟着Datawhale写的教程操作了一遍,不懂的地方加了一点点自己的理解,感谢Datawhale! 了解
项目链接合集(必看) 项目专栏合集https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc 必看 A.机器学习系列入门系列[一]:基于鸢尾花的逻辑回归分类预测: 逻辑回归(Logistic regression,简称LR)虽然其中带有\\\"回归\\\"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领

数据挖掘技术背景 大数据如何改变我们的生活 1.数据爆炸但知识贫乏 人们积累的数据越来越多。但是,目前这些数据还仅仅应用在数据的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势,导致了“数据爆炸但知识
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者: 秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们 点赞👍🏻、收藏

目录 一、导入数据 二、数据查看 可视化缺失值占比 绘制所有变量的柱形图,查看数据 查看各特征与目标变量price的相关性 三、数据处理 处理异常值 查看seller,offerType的取值 查看特征 notRepairedDamage 异常值截断 填充缺失值 删除取值无变化的特征 查看目标变量p
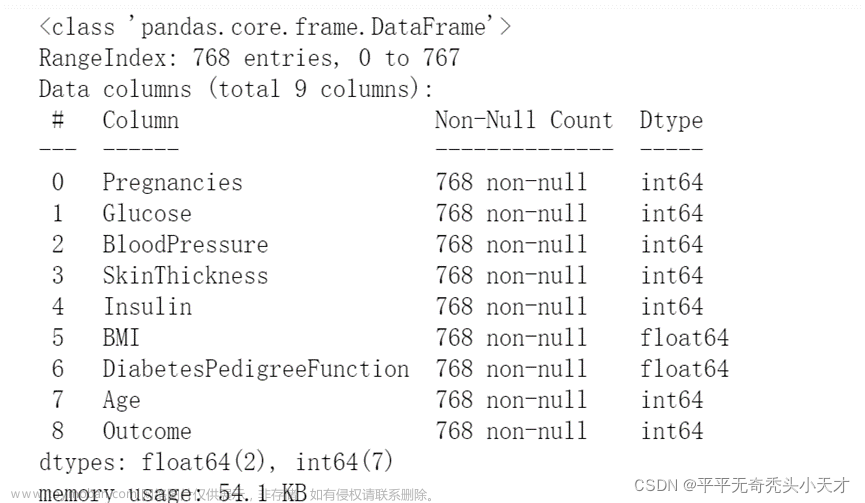
一、准备数据 1.查看数据 二、数据探索性分析 1.数据描述型分析 2.各特征值与结果的关系 a)研究各个特征值本身类别 b)研究怀孕次数特征值与结果的关系 c)其他特征值 3.研究各特征互相的关系 三、数据预处理 1.去掉唯一属性 2.处理缺失值 a)标记缺失值 b)删除缺失值行数 c

目录 1.Apriori算法 Apriori性质 伪代码 apriori算法 apriori-gen(Lk-1)【候选集产生】 has_infrequent_subset(c,Lx-1)【判断候选集元素】 例题 求频繁项集: 对于频繁项集L={B,C,E},可以得到哪些关联规则: 2.FP-growth算法 FP-tree构造算法【自顶向下建树】 insert_tree([plP],T) 利用FP-tree挖掘频繁项集
数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(Knowledge-Discovery in Databases,KDD)中的一个步骤。 数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中的信息的过程。 数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、

进一步理解关联规则算法(Apriori算法、FP-tree算法),利用weka实现数据集的挖掘处理,学会调整模型参数,读懂挖掘规则,解释规则的含义 (1)随机选取数据集为对象,完成以下内容:(用两种方法:Apriori算法、FP-tree算法) 文件导入与编辑; 参数设置说明; 结果截图;



