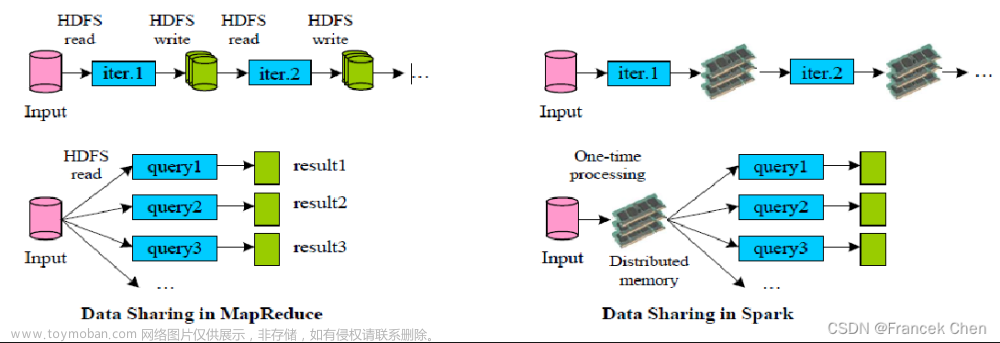
spark shuffle 中 map 和 reduce 是一个相对的概念,map是产生一批数据,reduce是接收一批数据,前一个任务是map,后一个任务是reduce。
hashShuffle:hash分组,一个task里面按hash值的不同,分到不同的组里,在内存中也是独立的

sortShuffle比hashShuffle好的地方在于,sortShuffle是每个task(并行度)产生一个文件,而hashShffle是按hash分区来的,一个task会产生多个文件,增加了网络IO。 文章来源:https://www.toymoban.com/news/detail-575781.html
文章来源:https://www.toymoban.com/news/detail-575781.html
sort是聚合操作时需要做的排序操作,如果不用聚合,bypass会跳过排序操作,节约了性能。文章来源地址https://www.toymoban.com/news/detail-575781.html
到了这里,关于Spark高级特性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!