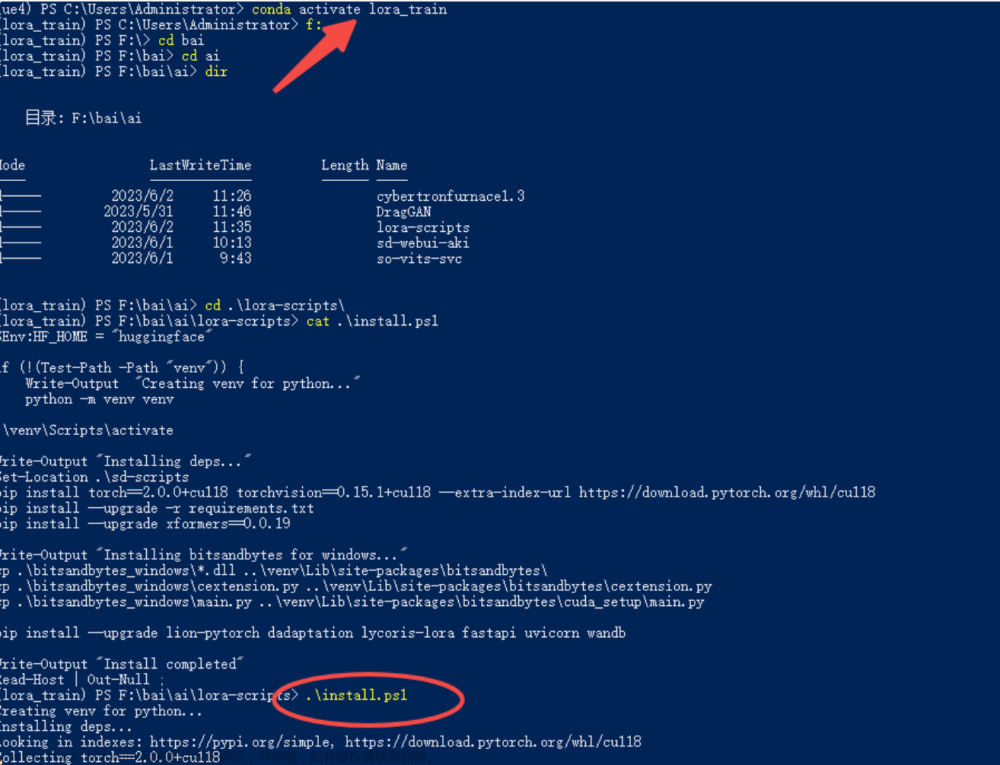
1、使用diffusers-0.14.0, stabel-diffusion 模型 v-1.5版本
下载diffusers-0.14.0 并解压,新建文件test.py, 写入以下:
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
执行以上过程,自动下载新建stable-diffusion-v1-5文件夹并下载多个模型在次目录下,
并根据prompt 生成一张image。
2、自己数据集的制作。
使用X-decoder 项目的demo_captioning.py模型,https://github.com/microsoft/X-Decoder
每一张图片生成一个对应的txt文件,txt文件中保存了该图片的prompt. demo_captioning.py 需要小改一下保存prompt就行。
将所有图片和txt都存放到同一个文件夹下。
因为模型训练使用的是huggingFace 的datasets 格式,所有再生成一个csv文件,或者json文件都行。代码如下:
import csv
import glob
header = ['file_name','text']
img_list = glob.glob('./172_186/prompt_imgs/*.jpg')
with open('metadata.csv', 'w', encoding='utf-8') as file_obj:
# 1:创建writer对象
writer = csv.writer(file_obj)
# 2:写表头
writer.writerow(header)
# 3:遍历列表,将每一行的数据写入csv
for p in img_list:
txt = p.replace('jpg','txt')
content = [p.split('/')[-1],txt]
writer.writerow(content)
测试一下生成csv文件格式对不对:
data_files = {}
data_files["train"] = os.path.join('./pokman/prompts', "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files)
print(dataset['train'])
column_names = dataset["train"].column_names
print(column_names)
输出结果:
Dataset imagefolder downloaded and prepared to /home/lyn/.cache/huggingface/datasets/imagefolder/default-a6d71509cd596a17/0.0.0/37fbb85cc714a338bea574ac6c7d0b5be5aff46c1862c1989b20e0771199e93f. Subsequent calls will reuse this data.
Dataset({
features: ['image', 'text'],
num_rows: 2151
})
['image', 'text']
最后把这个csv文件一起放入Image和txt的文件夹中即可。
3、模型训练。
脚本diffusers-0.14.0/examples/text_to_image/train_text_to_image_lora.py
命令:
先设置以下环境变量,执行
export MODEL_NAME="/diffusers-0.14.0/stable-diffusion-v1-5" 模型所在目录
export OUTPUT_DIR="/diffusers-0.14.0/logs" 模型文件保存目录
export IMAGE_FOLDER='/172_186/prompt_imgs' 训练数据所在目录
然后终端执行:
accelerate launch --mixed_precision="fp16" examples/text_to_image/train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--report_to=wandb \
--checkpointing_steps=500 \
--seed=1337 \文章来源:https://www.toymoban.com/news/detail-575865.html
--train_data_dir=${IMAGE_FOLDER} \文章来源地址https://www.toymoban.com/news/detail-575865.html
到了这里,关于Stable diffusion LoRA 训练过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!