参考
- Neo4j - 环境设置_w3cschool
- 【知识图谱】Neo4j入门教程 - 知乎
- neo4j 教程_w3cschool
- 图数据库Neo4j实战(全网最详细教程)_neo4j使用教程_星川皆无恙的博客-CSDN博客
- 代码片段_知识图谱Neo4j Cypher查询语言详解
Windows安装
参考
- NEO4J指定JDK路径_elasticsearch_K歌、之王-华为云开发者联盟
- Window下Neo4j安装教程
- 图数据库Neo4j下载、安装_neo4j3.5下载_Golden-Star的博客-CSDN博客
- 篇一:Neo4j图形数据库的安装与环境配置(普通版与Desktop版)_neo4j desktop和neo4j区别_小赵de碎星采摘馆的博客-CSDN博客
1、桌面版安装
下载地址:Neo4j Desktop Download | Free Graph Database Download
输入个人信息后,会有一个激活码,保存下来,后面要用!
直接默认安装,安装位置可改,第一次打开时会让你输入刚刚获取到的激活码。
2、zip安装
下载地址:Neo4j Deployment Center - Graph Database & Analytics
(此处下载是community版)
下载完成后,将压缩包解压到一个文件夹中
环境配置
新建变量名写:NEO4J_HOME, 变量值为刚刚的文件夹路径;
Path后面添加上路径:%NEO4J_HOME%\bin。
启动
在bin路径下打开cmd,输入:neo4j.bat console
出现以下为成功

若启动时JDK版本报错,可以安装指定版本JDK,并需要改下bin目录下的neo4j.bat, 把set "JAVA_HOME=XXXX"加入进去

访问数据
自带的BI界面
在浏览器中输入:http://localhost:7474/
Username是 neo4j (这个用户名好像是不可以修改的)
Password默认是neo4j,zip版本第一次进入会提示你修改。
命令行工具 cypher-shell
参考
Cypher-shell - 简书
cypher命令之后一定要加分号;否则无法运行,只能换行!!!
在shell里面执行cypher会比BI效率高,缺点就是不能可视化,不过可以导出到本地。
linux:在 NEO4J_HOME/bin 目录下,执行:cypher-shell,按照提示输入用户名、密码后进入

windows双击运行 cypher-shell.bat,

可以看到当前的账户名为neo4j,数据库为neo4j,直接输入cypher语句,可以批量执行cypher语句。
执行cypher脚本
写一个cypher脚本:run.cypher,保存在当前目录NEO4J_HOME/bin下
在cypher-shell界面使用source命令运行脚本:
:source run.cql 执行结果:
未登录时可以执行下面语句
cat run.cypher | cypher-shell -a localhost:port -u username -p passwd
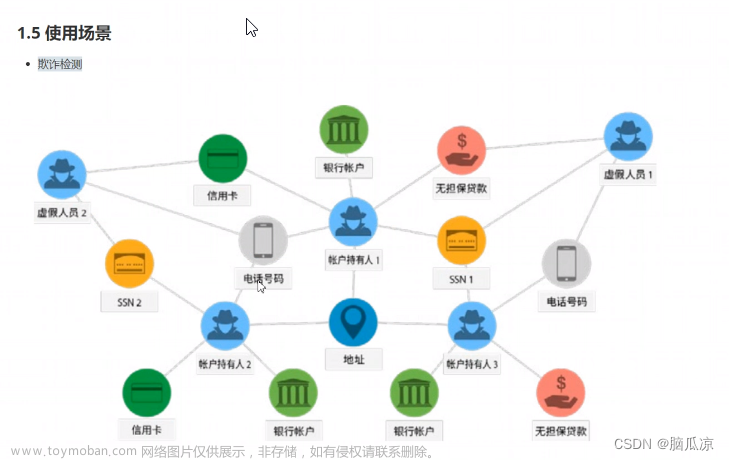
介绍
图是一组节点和连接这些节点的关系。图形数据存储在节点和关系在属性的形式。属性是键值对表示数据。Neo4j图数据库主要有以下组成元素:节点、属性、关系、标签
节点
节点(Node)是图数据库中的一个基本元素,用来表示一个实体记录。
1、节点是主要的数据元素,节点通过关系连接到其他节点。节点可以具有一个或多个属性(即,存储为键/值对的属性)。
2、节点有一个或多个标签,用于描述其在图表中的作用。
属性
属性(Property)是用于描述图节点和关系的键值对。
1、属性是命名值,其中名称(或键)是字符串属性可以被索引和约束
2、可以从多个属性创建复合索引
关系
关系(Relationship)同样是图数据库的基本元素。关系就是用来连接两个节点,,其始端和末端都必须是节点,关系不能指向空也不能从空发起。关系和节点一样可以包含多个属性,但关系只能有一个类型(Type) 。
1、关系连接两个节点关系是方向性的节点可以有多个甚至递归的关系。
2、关系可以有一个或多个属性(即存储为键/值对的属性)
3、基于方向性,Neo4j关系被分为两种主要类型:单向关系、双向关系
标签
标签(Label)将一个公共名称与一组节点或关系相关联, 节点或关系可以包含一个或多个标签。 我们可以为现有节点或关系创建新标签, 我们可以从现有节点或关系中删除标签。
1、标签用于将节点分组一个节点可以具有多个标签对标签进行索引。
2、以加速在图中查找节点本机标签索引针对速度进行了优化。
cyher
Neo4j的操作语言称为cyher,相当于关系数据库sql。
节点
Cypher 采用一对圆括号 () 来表示节点,如 (n:角色) 表示一个 角色 节点,n 是变量名,供命令执行时用 n 来访问这个节点,在命令执行完毕后就无法使用了。同时单独的 () 表示一个匿名节点,在匹配时表示匹配所有节点。
属性
(n:角色{name:'郭靖'}) ,{}中包含的name:'郭靖'就为一组属性键值对。
关系
--表示无方向的关系
--> 表示有方向的关系
-[r]-> 则给关系赋予一个变量名r,方便对这个关系进行操作
-[r:配偶]-> 匹配关系为 配偶 的类型
同时为了书写简单,可以为节点和关系语法赋予一个变量
//将所有 (角色)-[配偶]-() 的子图赋值给变量 p
p = (n:角色)-[r:配偶]-()
这样变量 p 就可以写到多个查询语句中,避免重复编写
关系路径长度匹配
在关系中,允许匹配特定路径长度的内容,如:
-
(n)-[*2]->(m)表示关系数量为 2 的 3 个节点的匹配, 等价于(a)-[]->()-[]->(b) -
(n)-[*2..4]->(m)匹配路径长度为 2 到 4 之间的路径 -
(n)-[*2..]->(m)匹配路径长度大于 2 的路径 -
(n)-[*..4]->(m)匹配路径长度小于 4 的路径 -
(n)-[*]->(m)匹配任意长度的路径
列表
Cypher 支持列表操作,通过 [] 来创建列表。
常用语法
参考
1、知识图谱(3) Neo4j Cypher - 知乎
2、cypher语法:Cypher Cheat Sheet - Neo4j Documentation Cheat Sheet
3、neo4j中with语句的使用 - guoce的个人空间 - OSCHINA - 中文开源技术交流社区

CREATE
我们应该使用此标签名称来访问节点详细信息。
MERGE 命令是 CREATE 命令和 MATCH 命令的组合。 MERGE 在图中搜索给定模式,如果存在,则返回结果,如果不存在,则创建并返回结果。
1、创建一个没有属性的节点
CREATE (节点名称:节点标签名称)
2、创建一个有属性的节点
CREATE (节点名称:节点标签名称{ 属性名称1:属性值,属性名称2:属性值,属性名称3:属性值 })
3、创建两个节点和关系属性
CREATE(节点名称1:节点标签名称1{属性})-[关系名称:关系标签名称{属性}]->(节点名称2:节点标签名称2{属性})MATCH
MATCH 命令用于从数据库中获取节点,关系的信息,类似于 SQL 中的 SELECT。RETURN 则是在 MATCH 搜索完成后返回数据,因此 MATCH 必须与 RETURN 同时使用。
ptional match 类似于 match,不同之处在于 optional match 在匹配不到内容时返回 null 方便查询继续进行,而 match 直接返回查询无结果
1、获取有关节点
match (变量名:节点的标签名称) return n
MATCH (变量名:节点的标签名称 {属性名称1:属性值,属性名称2:属性值}) RETURN 变量名
2、使用两个现有节点:节点标签名称1和节点标签名称2创建与属性的关系
MATCH (变量名1:节点标签名称1),(变量名2:节点标签名称2)
CREATE (变量名1)-[关系名称:关系标签名称{属性}]->(变量名2)
RETURN 关系名称RETURN
RETURN 变量名,变量名.属性名称1WHERE
WHERE 可以结合函数 exists() ,字符串匹配 starts with,ends with,contains,逻辑匹配 in,not,and,or 和正则表达式匹配进行更加精细的匹配,正则表达式的语法为 =~ 'regexp'。
where 变量名.属性名称=属性值DELETE
从数据库永久删除节点及其关联的属性。
DELETE 变量名列表REMOVE
删除节点或关系的标签或属性
DELETE 变量名.属性名称
DELETE 变量名.标签名称
例如:
match (n:角色) where n.name='金轮法王' remove n.from return n
match (n:角色)-[r]-() where n.name='金轮法王' delete n,r
清空数据库:match (n) optional match (n)-[r]-() delete n,r
SET
用于给现有节点或关系添加新属性,因此,SET 需要配合 MATCH 使用。
SET 变量名.属性名= 属性值
例如:match (n:角色) where n.name='杨过' set n.nickname='西狂' return n
唯一索引
参考:
1、Spring Data Neo4j 4中的唯一索引 | 那些遇到过的问题
2、Neo4j - 创建唯一约束 - 蝴蝶教程
CREATE CONSTRAINT ON (n:User) ASSERT n.user_id IS UNIQUE;常用函数
参考
Neo4j 常用函数介绍 - 文章详情
谓词函数(返回true或者false)
Exists():用于检查是否存在或满足特定的条件。
all():表示所有的元素都满足条件
any():表示至少一个元素满足条件
none():表示没有一个元素满足条件
single():表示只有一个元素满足条件
标量函数(变量函数返回标量值)
1、获得节点和关系的ID和属性
id():返回节点或关系的ID
properties():返回节点或关系的属性(Map)
2、关系
endNode(relationship):返回关系的结束节点
startNode(relationship):返回关系的开始节点
type(relationship):返回关系的类型
3、列表相关
coalesce():返回列表中个非NULL的元素
head():返回列表中的个元素
last():返回列表中的有一个元素
size():返回列表中元素的数量
4、size()和length()函数
size(string):表示字符串中字符的数量,可以把字符串当作是字符的列表。
size(list):返回列表中元素的数量。
size(pattern_expression):也是统计列表中元素的数量,但是不是直接传入列表,而是提供模式表达式(pattern_expression),用于在匹配查询(Match query)中提供一组新的结果,这些结果是路径列表,size()函数用于统计路径列表中元素(即路径)的数量。
length(path):返回路径的长度,即路径中关系的数量
聚合函数(聚合函数用于对查询的结果进行统计)
avg():计算均值
count(exp):用于计算非null值(value)的数量,使用 count(distinct exp)进行无重复非null值的计数,使用count(*):计算值或记录的总数量,包括null值
max()、min():求大值和小值,在计算极值时,null被排除在外,min(null)或max(null)返回null
sum():求和,在求和时,null被排除在外,sum(null)的结果是0
collect():把返回的多个值或记录组装成一个列表,collect(null)返回一个空的列表
列表函数
1、抽取元素构成列表
extract(variable IN list | expression):根据抽取的值组装成一个列表,返回一个列表
2、过滤列表元素
filter(variable IN list WHERE predicate):把过滤后的元素组成一个子表,返回该列表
3、获得列表
keys(node):从节点的属性中抽取属性键
labels(node):节点标签的列表
nodes(path):从路径中获取所有节点的列表
relationships(path):从路径中获得所有的关系
4、序列的生成和倒置
range():用于生成一个有序的序列
reverse():把原始列表的元素进行倒置
5、迭代计算列表
reduce(accumulator = initial, e IN list | expression):应用在列表上,对列表中的每个元素e进行迭代计算,在元素e上运行表达式(expression),把当前的结果存储在累加器中,进行迭代计算,并返回终计算的标量结果
常用语句
根据用户ID删除用户拓扑关系
MATCH data=(endNode:User{user_id:"111111"})<-[line:DOWNSTREAM_OF*1..]-(startNode) delete data根据用户ID修改用户属性文章来源:https://www.toymoban.com/news/detail-576357.html
MATCH (a:User {user_id:'83b0a94642dd2b19fa408183538ad6a9'}) SET a.user_id='1111111111';根据用户ID删除用户节点和关系文章来源地址https://www.toymoban.com/news/detail-576357.html
MATCH data=(endNode:User{user_id:"1bb5be145e13d8d4b3ce4f470446e16d"})-[line]-(startNode) delete endNode,line到了这里,关于图数据库:neo4j学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!