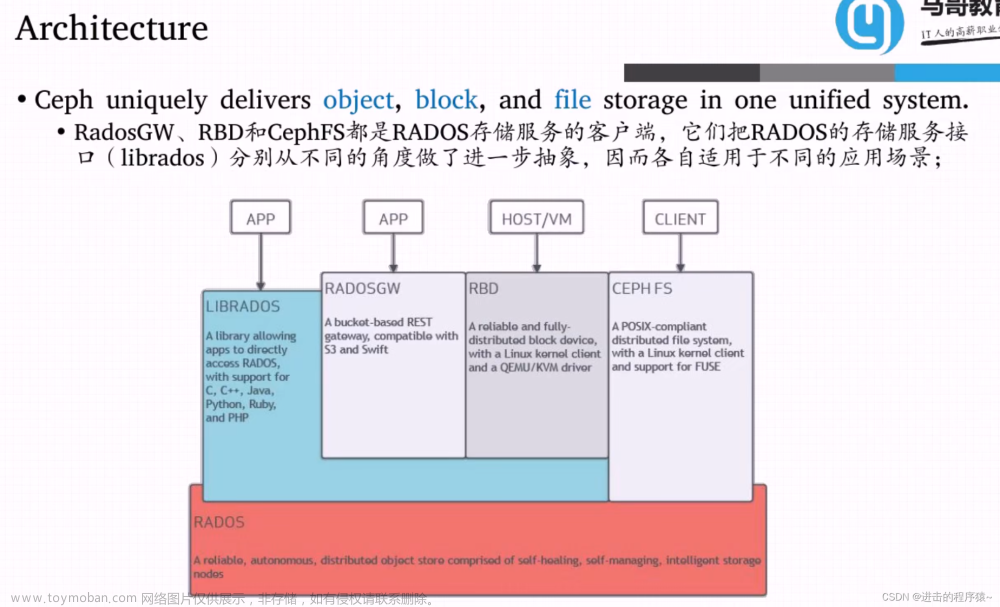
Ceph接口使用
CephFS文件系统
服务端
添加mds服务
---admin---
###在管理节点创建 mds 服务
cd /etc/ceph
ceph-deploy mds create node01 node02 node03
###查看各个节点的 mds 服务
ssh root@node01 systemctl status ceph-mds@node01
ssh root@node02 systemctl status ceph-mds@node02
ssh root@node03 systemctl status ceph-mds@node03
创建存储池
###创建存储池,启用 ceph 文件系统
###ceph 文件系统至少需要两个 rados 池
###一个用于存储数据,一个用于存储元数据。此时数据池就类似于文件系统的共享目录。
ceph osd pool create cephfs_data 128 #创建数据Pool
ceph osd pool create cephfs_metadata 128 #创建元数据Pool
ceph osd lspools ###能查看到资源池的ID号

###创建 cephfs,命令格式:
ceph fs new <FS_NAME> <CEPHFS_METADATA_NAME> <CEPHFS_DATA_NAME>
ceph fs new mycephfs cephfs_metadata cephfs_data
#启用ceph,元数据Pool在前,数据Pool在后
###查看cephfs
ceph fs ls
###查看mds状态,一个up,其余两个待命,目前的工作的是node01上的mds服务
ceph -s
mds: mycephfs:1 {0=node01=up:active} 2 up:standby
或
ceph mds stat
mycephfs:1 {0=node01=up:active} 2 up:standby

授权用户权限
---admin---
###创建用户
###语法格式:ceph fs authorize <fs_name> client.<client_id> <path-in-cephfs> rw
###账户为 client.zhangsan,用户 name 为 zhangsan,zhangsan 对ceph文件系统的 / 根目录(注意不是操作系统的根目录)有读写权限
ceph fs authorize mycephfs client.zhangsan / rw | tee /etc/ceph/zhangsan.keyring
###账户为 client.lisi,用户 name 为 lisi,lisi 对文件系统的 / 根目录只有读权限,对文件系统的根目录的子目录 /test 有读写权限
ceph fs authorize mycephfs client.lisi / r /test rw | tee /etc/ceph/lisi.keyring

客户端
前期准备
| 主机名 | public网络 | cluster网络 | 角色 |
|---|---|---|---|
| admin | 192.168.242.69 | admin(管理节点) | |
| node01 | 192.168.242.66 | 192.168.242.100.11 | mon、mgr、osd |
| node02 | 192.168.242.67 | 192.168.242.100.12 | mon、mgr、osd |
| node03 | 192.168.242.68 | 192.168.242.100.13 | mon、osd |
| client | 192.168.242.70 | client |
####防火墙设置
####关闭 selinux 与防火墙
####客户端要在 public 网络内
systemctl disable --now firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
###配置时间同步(一定要做)
systemctl enable --now chronyd
timedatectl set-ntp true #开启 NTP
timedatectl set-timezone Asia/Shanghai #设置时区
chronyc -a makestep #强制同步下系统时钟
timedatectl status #查看时间同步状态
chronyc sources -v #查看 ntp 源服务器信息
timedatectl set-local-rtc 0 #将当前的UTC时间写入硬件时钟
###安装常用软件和依赖包
yum -y install epel-release
yum -y install yum-plugin-priorities yum-utils ntpdate python-setuptools python-pip gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel zip unzip ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssh openssl-devel nss_ldap openldap openldap-devel openldap-clients openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced python wget lsof iptraf strace lrzsz kernel-devel kernel-headers pam-devel tcl tk cmake ncurses-devel bison setuptool popt-devel net-snmp screen perl-devel pcre-devel net-snmp screen tcpdump rsync sysstat man iptables sudo libconfig git bind-utils tmux elinks numactl iftop bwm-ng net-tools expect snappy leveldb gdisk python-argparse gperftools-libs conntrack ipset jq libseccomp socat chrony sshpass
###在客户端安装 ceph 软件包
cd /opt
wget https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm --no-check-certificate
rpm -ivh ceph-release-1-1.el7.noarch.rpm
yum install -y ceph
#######根据规划设置主机名
hostnamectl set-hostname client
su
####配置 hosts 解析
vim /etc/hosts
192.168.242.69 admin
192.168.242.66 node01
192.168.242.67 node02
192.168.242.68 node03
192.168.242.70 client
###在客户端创建工作目录
mkdir /etc/ceph
###在 ceph 的管理节点给客户端拷贝 ceph 的配置文件 ceph.conf 和账号的秘钥环文件 zhangsan.keyring、lisi.keyring
scp ceph.conf zhangsan.keyring lisi.keyring client:/etc/ceph
###在客户端制作秘钥文件
cd /etc/ceph
ceph-authtool -n client.zhangsan -p zhangsan.keyring > zhangsan.key
###把 zhangsan 用户的秘钥导出到 zhangsan.keyl
ceph-authtool -n client.lisi -p lisi.keyring > lisi.key
###把 lisi 用户的秘钥导出到 lisi.key

客户端挂载
方式一:基于内核
###语法格式:
mount -t ceph node01:6789,node02:6789,node03:6789:/ <本地挂载点目录> -o name=<用户名>,secret=<秘钥>
mount -t ceph node01:6789,node02:6789,node03:6789:/ <本地挂载点目录> -o name=<用户名>,secretfile=<秘钥文件>
示例一
mkdir -p /data/zhangsan
mount -t ceph node01:6789,node02:6789,node03:6789:/ /data/zhangsan -o name=zhangsan,secretfile=/etc/ceph/zhangsan.key
df -hT
示例二
mkdir -p /data/lisi
mount -t ceph node01:6789,node02:6789,node03:6789:/ /data/lisi -o name=lisi,secretfile=/etc/ceph/lisi.key
###验证用户权限
cd /data/lisi
echo 123 > 2.txt
-bash:2.txt:权限不够
echo 123 > test/2.txt
cat test/2.txt
123

示例三
###停掉 node02 上的 mds 服务
ssh root@node02 "systemctl stop ceph-mds@node02"
ceph -s
###测试客户端的挂载点仍然是可以用的,如果停掉所有的 mds,客户端就不能用了

方式二:基于 fuse 工具
###在 ceph 的管理节点给客户端拷贝 ceph 的配置文件 ceph.conf 和账号的秘钥环文件 zhangsan.keyring、lisi.keyring
scp ceph.client.admin.keyring client:/etc/ceph
###在客户端安装 ceph-fuse
yum install -y ceph-fuse
###客户端挂载
mkdir -p /data/aa
cd /data/aa
ceph-fuse -m node01:6789,node02:6789,node03:6789 /data/aa -o nonempty
#挂载时,如果挂载点不为空会挂载失败,指定 -o nonempty 可以忽略

Ceph 块存储系统 RBD 接口
服务端
创建存储池和镜像
---node01---
###创建一个名为 rbd-demo 的专门用于 RBD 的存储池
ceph osd pool create rbd-demo 64 64
---node01---
###将存储池转换为 RBD 模式
ceph osd pool application enable rbd-demo rbd
---node01---
###初始化存储池
rbd pool init -p rbd-demo
# -p 等同于 --pool
---node01---
###创建镜像
rbd create -p rbd-demo --image rbd-demo1.img --size 10G
###可简写为:
rbd create rbd-demo/rbd-demo2.img --size 10G

管理镜像
###查看存储池下存在哪些镜像
rbd ls -l -p rbd-demo
###查看镜像的详细信息
rbd info -p rbd-demo --image rbd-demo1.img
###结果展示
rbd image 'rbd-demo.img':
size 10 GiB in 2560 objects
#镜像的大小与被分割成的条带数
order 22 (4 MiB objects)
#条带的编号,有效范围是12到25,对应4K到32M,而22代表2的22次方,这样刚好是4M
snapshot_count: 0 #快照数量
id: 5fc98fe1f304 #镜像的ID标识
block_name_prefix: rbd_data.5fc98fe1f304 #名称前缀
format: 2 #使用的镜像格式,默认为2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #当前镜像的功能特性
op_features: #可选的功能特性
flags:

###修改镜像大小
rbd resize -p rbd-demo --image rbd-demo1.img --size 20G
rbd info -p rbd-demo --image rbd-demo1.img
###使用 resize 调整镜像大小,一般建议只增不减,如果是减少的话需要加选项 --allow-shrink
rbd resize -p rbd-demo --image rbd-demo1.img --size 5G --allow-shrink

###直接删除镜像
rbd rm -p rbd-demo --image rbd-demo2.img
rbd remove rbd-demo/rbd-demo2.img
###删除镜像
###推荐使用 trash 命令,这个命令删除是将镜像移动至回收站,如果想找回还可以恢复
rbd trash move rbd-demo/rbd-demo1.img
rbd ls -l -p rbd-demo
rbd trash list -p rbd-demo ###查看回收站的镜像
5fc98fe1f304 rbd-demo1.img
###还原镜像
rbd trash restore rbd-demo/5fc98fe1f304
rbd ls -l -p rbd-demo

客户端
-
客户端使用 RBD 有两种方式:
- 通过内核模块KRBD将镜像映射为系统本地块设备,通常设置文件一般为:/dev/rbd*
- 另一种是通过librbd接口,通常KVM虚拟机使用这种接口。
-
本例主要是使用Linux客户端挂载RBD镜像为本地磁盘使用。
-
开始之前需要在所需要客户端节点上面安装ceph-common软件包,因为客户端需要调用rbd命令将RBD镜像映射到本地当作一块普通硬盘使用。
-
并还需要把ceph.conf配置文件和授权keyring文件复制到对应的节点。
镜像挂载
--admin---
###在管理节点创建并授权一个用户可访问指定的 RBD 存储池
###指定用户标识为client.osd-mount,对另对OSD有所有的权限,对Mon有只读的权限
ceph auth get-or-create client.osd-mount osd "allow * pool=rbd-demo" mon "allow r" > /etc/ceph/ceph.client.osd-mount.keyring
--admin---
###修改RBD镜像特性,CentOS7默认情况下只支持layering和striping特性,需要将其它的特性关闭
rbd feature disable rbd-demo/rbd-demo1.img object-map,fast-diff,deep-flatten
--admin---
###将用户的keyring文件和ceph.conf文件发送到客户端的/etc/ceph目录下
cd /etc/ceph
scp ceph.client.osd-mount.keyring ceph.conf client:/etc/ceph
---client---
###安装 ceph-common 软件包
yum install -y ceph-common
###执行客户端映射
cd /etc/ceph
rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
###查看映射
rbd showmapped
rbd device list
###断开映射
rbd unmap rbd-demo/rbd-demo1.img

###格式化并挂载
mkfs.xfs /dev/rbd0
mkdir -p /data/bb
mount /dev/rbd0 /data/bb

###在线扩容
###在管理节点调整镜像的大小
rbd resize rbd-demo/rbd-demo1.img --size 30G
###在客户端刷新设备文件
xfs_growfs /dev/rbd0 #刷新xfs文件系统容量
resize2fs /dev/rbd0 #刷新ext4类型文件系统容量
df -hT

快照管理
- 对 rbd 镜像进行快照,可以保留镜像的状态历史
- 另外还可以利用快照的分层技术,通过将快照克隆为新的镜像使用。
###在客户端写入文件
echo 1111 > /data/bb/11.txt
echo 2222 > /data/bb/22.txt
echo 3333 > /data/bb/33.txt
###在管理节点对镜像创建快照
rbd snap create --pool rbd-demo --image rbd-demo1.img --snap demo1_snap1
可简写为:
rbd snap create rbd-demo/rbd-demo1.img@demo1_snap1
###列出指定镜像所有快照
rbd snap list rbd-demo/rbd-demo1.img
##用json格式输出:
rbd snap list rbd-demo/rbd-demo1.img --format json --pretty-format

回滚镜像到指定
在回滚快照之前,需要将镜像取消镜像的映射,然后再回滚。
###在客户端操作
rm -rf /data/bb/*
umount /data/bb
rbd unmap rbd-demo/rbd-demo1.img

###在管理节点操作
rbd snap rollback rbd-demo/rbd-demo1.img@demo1_snap1

###在客户端重新映射并挂载
rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
mount /dev/rbd0 /data/bb
ls /data/bb #发现数据还原回来了

###限制镜像可创建快照数
rbd snap limit set rbd-demo/rbd-demo1.img --limit 3
###解除限制
rbd snap limit clear rbd-demo/rbd-demo1.img
###删除快照
###删除指定快照:
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap1
#删除所有快照:
rbd snap purge rbd-demo/rbd-demo1.img


快照分层
- 快照分层支持用快照的克隆生成新镜像,这种镜像与直接创建的镜像几乎完全一样,支持镜像的所有操作。
- 唯一不同的是克隆镜像引用了一个只读的上游快照,而且此快照必须要设置保护模式。
###快照克隆
##将上游快照设置为保护模式:
rbd snap create rbd-demo/rbd-demo1.img@demo1_snap666
rbd snap protect rbd-demo/rbd-demo1.img@demo1_snap666
###克隆快照为新的镜像
rbd clone rbd-demo/rbd-demo1.img@demo1_snap666 --dest rbd-demo/rbd-demo666.img
rbd ls -p rbd-demo
###命令查看克隆完成后快照的子镜像
rbd children rbd-demo/rbd-demo1.img@demo1_snap666

快照展平
###通常情况下通过快照克隆而得到的镜像会保留对父快照的引用,这时候不可以删除该父快照,否则会有影响。
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666
#报错 snapshot 'demo1_snap666' is protected from removal.
###如果要删除快照但想保留其子镜像,必须先展平其子镜像,展平的时间取决于镜像的大小
###展平子镜像
rbd flatten rbd-demo/rbd-demo666.img
###取消快照保护
rbd snap unprotect rbd-demo/rbd-demo1.img@demo1_snap666
###删除快照
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666
rbd ls -l -p rbd-demo
#在删除掉快照后,查看子镜像依然存在

###挂载子镜像
###在服务端,给子镜像做映射
rbd map rbd-demo/rbd-demo666.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
###解挂原始镜像的挂载
umount /dev/rbd0
mkdir -p /data/cc
###挂载子镜像
mount /dev/rbd1 /data/cc

镜像的导出导入
###导出镜像
rbd export rbd-demo/rbd-demo1.img /opt/rbd-demo1.img
###导入镜像
#卸载客户端挂载,并取消映射
umount /data/bb
rbd unmap rbd-demo/rbd-demo1.img
###清除镜像下的所有快照,并删除镜像
rbd snap purge rbd-demo/rbd-demo1.img
rbd rm rbd-demo/rbd-demo1.img
rbd ls -l -p rbd-demo


###导入镜像
rbd import /opt/rbd-demo1.img rbd-demo/rbd-demo1.img
rbd ls -l -p rbd-demo

OSD 故障模拟与恢复
模拟 OSD 故障
###模拟 OSD 故障
###如果 ceph 集群有上千个 osd,每天坏 2~3 个太正常了,我们可以模拟 down 掉一个 osd
###如果 osd 守护进程正常运行,down 的 osd 会很快自恢复正常,所以需要先关闭守护进程
ssh root@node01 systemctl stop ceph-osd@0
###down 掉 osd
ceph osd down 0
ceph osd tree

将坏掉的 osd 踢出集群
方法一
###将 osd.0 移出集群,集群会开始自动同步数据
ceph osd out osd.0
###将 osd.0 移除 crushmap
ceph osd crush remove osd.0
###删除守护进程对应的账户信息
ceph auth rm osd.0
ceph auth list

###删掉 osd.0
ceph osd rm osd.0
ceph osd stat
ceph -s

方法二
ceph osd out osd.0
###使用综合步骤,删除配置文件中针对坏掉的 osd 的配置
ceph osd purge osd.0 --yes-i-really-mean-it
把原来坏掉的 osd 修复后重新加入集群
###在 osd 节点创建 osd,无需指定名,会按序号自动生成
cd /etc/ceph
ceph osd create

---admin---
###创建账户
ceph-authtool --create-keyring /etc/ceph/ceph.osd.0.keyring --gen-key -n osd.0 --cap mon 'allow profile osd' --cap mgr 'allow profile osd' --cap osd 'allow *'
---admin---
###导入新的账户秘钥
ceph auth import -i /etc/ceph/ceph.osd.0.keyring
ceph auth list

###更新对应的 osd 文件夹中的密钥环文件
ceph auth get-or-create osd.0 -o /var/lib/ceph/osd/ceph-0/keyring
---admin---
###加入 crushmap
ceph osd crush add osd.0 1.000 host=node01 #1.000 代表权重
###加入集群
ceph osd in osd.0
ceph osd tree
 文章来源:https://www.toymoban.com/news/detail-576395.html
文章来源:https://www.toymoban.com/news/detail-576395.html
---osd节点---
###重启 osd 守护进程
systemctl restart ceph-osd@0
ceph osd tree #稍等片刻后 osd 状态为 up
 文章来源地址https://www.toymoban.com/news/detail-576395.html
文章来源地址https://www.toymoban.com/news/detail-576395.html
###如果重启失败
报错:
Job for ceph-osd@0.service failed because start of the service was attempted too often. See "systemctl status ceph-osd@0.service" and "journalctl -xe" for details.
To force a start use "systemctl reset-failed ceph-osd@0.service" followed by "systemctl start ceph-osd@0.service" again.
####运行
systemctl reset-failed ceph-osd@0.service && systemctl restart ceph-osd@0.service
到了这里,关于10.Ceph接口使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[分布式] Ceph实战应用](https://imgs.yssmx.com/Uploads/2024/02/579407-1.png)