Abstract
Segment Anything (SA) project: a new task, model, and dataset for image segmentation.
we built the largest segmentation dataset to date (by far:迄今为止), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks.The Segment Anything Model (SAM) and corresponding dataset (SA-1B) releasing at SA to foster research into foundation models for computer vision.
Introduction
Large language models pre-trained on web-scale datasets are revolutionizing NLP (彻底改变)with strong zero-shot and few-shot generalization. These “foundation models” can generalize to tasks and data distributions beyond those seen during training. (zero-shot and few-shot generalization零样本和少样本泛化)
Foundation models have also been explored in computer vision ,albeit to a lesser extent. (尽管程度较小)
Our goal is to build a foundation model for image segmentation. That is, we seek to develop a promptable model and pre-train it on a broad dataset using a task that enables powerful generalization. With this model, we aim to solve a range of downstream segmentation problems on new data distributions using prompt engineering.
The success of this plan hinges on(取决于) three components: task, model, and data. To develop them, we address the following questions about image segmentation:
1. What task will enable zero-shot generalization?
2. What is the corresponding model architecture?
3. What data can power this task and model?
These questions are entangled and require a comprehen- sive solution.(错综复杂需要一个综合的解决方案。)
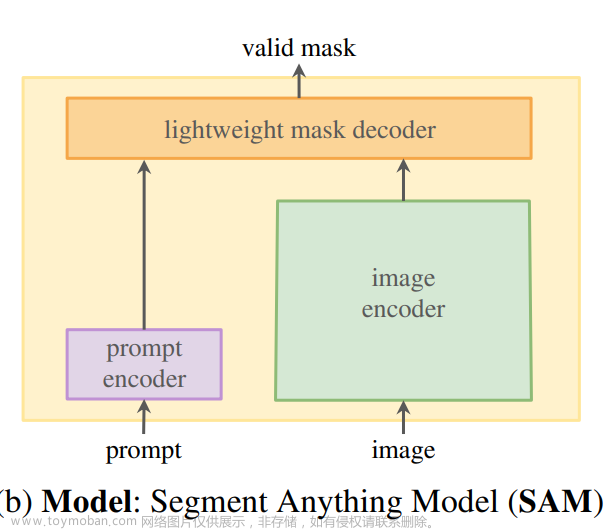
Surprisingly, we find that a simple design satisfies all three constraints: a powerful image encoder computes an image embedding, a prompt encoder embeds prompts, and then the two information sources are combined in a lightweight mask decoder that predicts segmentation masks. We refer to this model as the Segment Anything Model, or SAM .
data engine has three stages: 文章来源:https://www.toymoban.com/news/detail-577060.html
- assisted-manual
- semi-automatic
- and fully automatic
2. Segment Anything Task文章来源地址https://www.toymoban.com/news/detail-577060.html
到了这里,关于Segment Anything论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[自注意力神经网络]Segment Anything(SAM)论文阅读](https://imgs.yssmx.com/Uploads/2024/02/423006-1.png)