ChartGPT最近特别火,但是收费,而且国内访问不太方便,所以找了个类似的进行学习使用
ChatGLM-6B,开源支持中英文的对话大模型,基于 General Language Model (GLM) 架构,具有62亿参数,简单说非常不错,可能和chart GPT比较有些差距,但是开源免费,并且可以在本地部署,支持中文,这就很nice了
首先安装环境,当前本机电脑win10,pycharm2020,python3.9,Anaconda3。文章涉及到的相关资源会在文章最下面公共号中提供,这里也注意,部分软件根据电脑本身需要改动版本
安装
1、需要安装CUDA和cudnn
由于要使用GPU(不用也可以,不过是有点慢),需要安装CUDA和cudnn,CUDA是显卡厂商NVIDIA推出的运算平台,cuDNN是用于深度神经网络的GPU加速库, CUDA看作是一个工作台,cuDNN是具体工具
在控制面板查看支持的版本

或者敲命令
nvidia-smi

确定CUDA版本,去网站下载
https://developer.nvidia.com/cuda-toolkit
我下在的就是12的
然后下载cudnn,这里也注意,网站需要注册登录下载,最好在谷歌浏览器上面走,火狐上容易卡住
https://developer.nvidia.com/rdp/cudnn-archive
下载的时候注意cuda版本

安装的时候如果遇见什么错误,可以查看https://blog.csdn.net/anmin8888/article/details/127910084这个博客上安装流程
2、下载代码
装完环境后接下来可以开始下载代码,这里推荐使用pycharm直接从Git上直接下载,然后通过软件创建环境,这里的话通过软件一步一步下一步就完了,然后等待相关jar包下载完毕即可
下载完成后可以创建一个py文件运行下面代码
运行
import torch
print(torch.__version__)
print(torch.cuda.is_available())
会打印torch版本以及是否能使用cuda,如果一切正常会打印
2.0.1+cu117
True
需要注意的是 “ cu117 ” 和 “ True ” ,这样表示一切正常
如果打印的是CPU,说明torch版本不是GPU的,需要卸载重装
pip uninstall torch torch-2.0.1.dist-info torchgen
torch官网地址 :https://pytorch.org/get-started/locally/#no-cuda-1
然后在pycharm的Terminal面板下运行,等待下载安装完成
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
如果最后打印为false,则可能是torch和cuda的版本不兼容,需要安装对应版本
3、下载模型
完整模型在Hugging Face Hub网站上,地址:https://huggingface.co/THUDM/chatglm-6b
命令下载
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b
但是这样下载太慢,而且由于网络问题且模型特别大,容易下载不下来,所以最后一个一个下,尤其是那些模型,动不动一两个G的

下载完成后在pycharm项目根目录下创建文件夹chatglm-6b,然后存入所有相关文件

4、使用
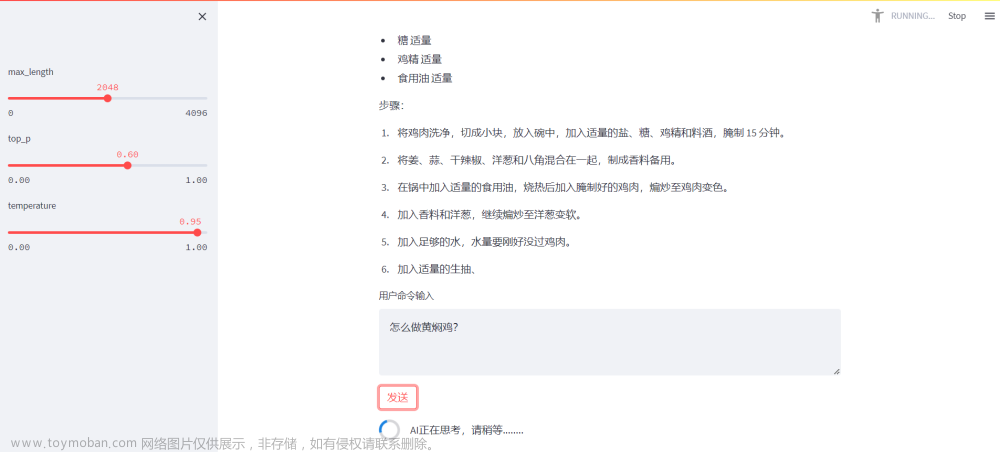
接下来就可以使用了,使用方式有通过网页访问,命令行访问,API访问三种,在README.md文档中都有说明,这里使用API的方式访问
创建一个application文件夹存放相关自己代码,创建一个py文件,然后写入,运行文件即可
from transformers import AutoTokenizer, AutoModel
import os
modelPath = os.path.abspath('../chatglm-6b')
tokenizer = AutoTokenizer.from_pretrained(modelPath,
trust_remote_code=True)
model = AutoModel.from_pretrained(modelPath,
trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
除此之外也可以启动 web_demo.py ,在页面上进行交互使用,需要注意修改文件中模型文件所在位置
异常
Torch not compiled with CUDA enabled
Torch CUDA 版本没有一致,卸载重装对应版本
CUDA out of memory文章来源:https://www.toymoban.com/news/detail-577067.html
内存不足,加 .quantize(8) , 还是报这个错的话可以再减数字
model = AutoModel.from_pretrained(modelPath,
trust_remote_code=True).quantize(4).half().cuda()
后记
如果感觉下载一切比较麻烦的话,可以关注公共号 有意思的GitHub,回复chatglm,源码,模型,工具,安装包,都在对应百度云盘文章来源地址https://www.toymoban.com/news/detail-577067.html
到了这里,关于ChatGLM-6B的windows本地部署使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!