正则表达式
常用元字符
. 匹配除换行符以外的任意字符
\w 匹配字幕或数字或下划线
\s 匹配任意空白字符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始 # 开发常用
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或b
() 匹配括号内的表达式,也表示一个组
[…] 匹配字符组中的字符
[^…] 匹配除字符组中字符的所有字符,**[ ]中的^**表示“非”
量词
* 重复0次或更多次
+ 重复1次或更多次
? 重复0次或1次
{n} 重复n次
{n,} 重复n次或更多次
{n,m}重复n到m次
贪婪匹配,爬虫常用
.* 贪婪匹配
.*? 惰性匹配,尽可能间隔少的匹配
python-re
import re
# findall:匹配字符串中所有正则内容
lst = re.findall(r"\d+", "我的电话是10086,我孩子的电话是10010")
print(lst)
['10086', '10010']
# finditer:匹配字符串中所有的内容【返回是迭代器】,从迭代器中拿到内容需要.group()
# 最常用,效率高
it = re.finditer(r"\d+", "我的电话是10086,我孩子的电话是10010")
for i in it:
print(i.group())
10086
10010
# search:返回的是match对象,拿数据需要.group()
# 找到一个结果就返回,不找了
# 常用
s = re.search(r"\d+", "我的电话是10086,我孩子的电话是10010")
print(s.group())
10086
# match:从头匹配,拿数据需要.group()
s = re.match(r"\d+", "10000我的电话是10086,我孩子的电话是10010")
print(s.group())
10000
# 预加载正则,后面没有r''
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话是10086,我孩子的电话是10010")
for j in ret:
print(j.group())
# 可以反复用
bhq = obj.findall("疑是银河落九天,为啥不还10000000")
print(bhq)
10086
10010
['10000000']
s = """
<div class='red'><span id='1'>西游记</span></div>
<div class='green'><span id='2'>三国演义</span></div>
<div class='blue'><span id='3'>水浒</span></div>
<div class='yellow'><span id='4'>红楼666</span></div>
"""
obj = re.compile(r"<div class='.*?'><span id='\d+'>.*?</span></div>", re.S)
obj2 = re.compile(r"<div class='.*?'><span id='\d+'>(?P<wahaha>.*?)</span></div>", re.S)
# re.S 让.能匹配换行符
# (?P<分组名字>正则) 可以从正则匹配的内容中提取一部分
result = obj2.finditer(s)
for it in result:
print(it.group("wahaha"))
代理
# 设置代理
proxies = {
"https": "https://210.60.8.83:3129"
}
# 添加代理
resp = requests.get("https://www.baidu.com", proxies =proxies)
resp.encoding = 'utf-8'
print(resp.text)
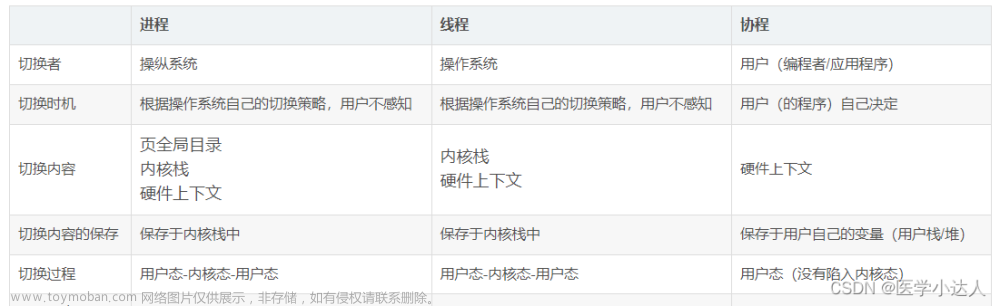
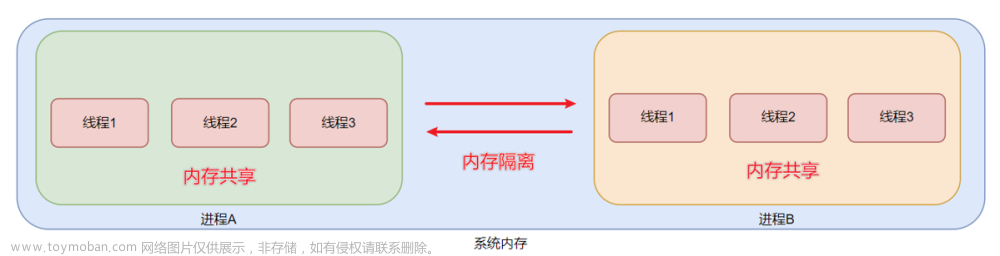
多线程
进程 - 资源单位
线程 - 执行单位
每个进程里至少一个线程,启动一个程序,默认都有一个主线程
方法一:
from threading import Thread
def func():
for i in range(1000):
print("func", i)
if __name__ == '__main__':
t = Thread(target=func) # 目标线程
t.start() # 多线程状态为开始工作状态,具体执行时间由cpu决定
for i in range(1000):
print("main", i)
# 传参
def func(name):
for i in range(1000):
print(name, i)
if __name__ == '__main__':
t = Thread(target=func, args=("周杰伦",)) # 目标线程,,args参数必须是 元组 传参
t.start() # 多线程状态为开始工作状态,具体执行时间由cpu决定
for i in range(1000):
print("main", i)
方法二:
# 传参时,定义构造函数,def __init__(self):
class myThread(Thread):
def run(self):
for i in range(1000): # 固定的 - > 当线程被执行的时候,被执行的就是run()
print("子线程", i)
if __name__ == '__main__':
t = myThread()
# t.run() # 此为方法的调用 - >仍然单线程进行
t.start() # 开启线程
for i in range(1000):
print("主线程", i)
# 多进程使用,创建多进程资源远远大于多线程
# 写法跟线程一模一样,降低开发者记忆成本,资源使用完全不一样
from multiprocessing import Process
def func():
for i in range(1000):
print("func", i)
if __name__ == '__main__':
p = Process(target=func) # 目标线程
p.start() # 多线程状态为开始工作状态,具体执行时间由cpu决定
for i in range(1000):
print("main", i)
线程池
一般思路,先写单个实现,然后放到线程池
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def func(name):
for i in range(1000):
print(name, i)
if __name__ == '__main__':
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
# t.submit(func, name=f"线程-{i}")
t.submit(func, name="changjiang")
# 等待线程池中的任务全部执行完毕,才能继续执行(守护)
print(123)
协程
当程序处于IO操作时,线程都会处于阻塞状态,cpu不为我工作
例如:input(),sleep() ,request.get(),等等
协程:当程序预见IO操作时,可以选择切换到其他任务上,为我工作!把cpu绑在我的程序上
在微观上,是一个任务一个任务的进行切换,切换条件一般就是IO操作
在宏观上,我们能看到其实是多个任务一起执行,多任务异步操作
# @desc : 写爬虫的模板,协程应用,效率极高,相当于单线程
import asyncio
async def download(url):
print("准备开始下载")
await asyncio.sleep(2) # 网络请求; # requests.get() 是不行的
print("下载完成")
async def main():
urls = [
"http://www.baidu/com",
"http://www.bilibili.com",
"http://www.163.com"
]
tasks = []
for url in urls:
# d = download(url) # python3.11之后会被干掉
d = asyncio.create_task(download(url)) # python3.8之后的写法
tasks.append(d)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
爬虫视频处理
一般的视频网站怎么做的?
用户上传 -> 转码(把视频做成,2k,1080,标清) -> 切片处理(把单个的文件进行拆分) 60
用户在进行拉动进度条时候,处理方式
==================
需要一个文件记录:1.视频播放顺序。2.视频存放的路径。
M3U8 txt json =>文本
想要抓取一个视频:
找到m3u8(各种手段)
通过m3u8下载到ts文件文章来源:https://www.toymoban.com/news/detail-577134.html
可以通过各种手段(不限于编程手段)把ts文件合并成一个mp4文件文章来源地址https://www.toymoban.com/news/detail-577134.html
到了这里,关于python正则+多线程(代理)+线程池+协程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[python] 协程学习从0到1,配合案例,彻底理解协程,耗费资源不增加,效果接近多线程](https://imgs.yssmx.com/Uploads/2024/02/433386-1.png)