1.安装工作
1.1 准备工作
前提是把jJDK8安装好,hadoop3.x最低需要jdk8。
然后打开共享把远程登陆打开,不打开说是后面会报错,

到终端输入命令:ssh localhost

生成新的keygen否则后面会报错 Permission denied 命令:ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

注册关键字,命令为如下:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys1.2 安装hadoop
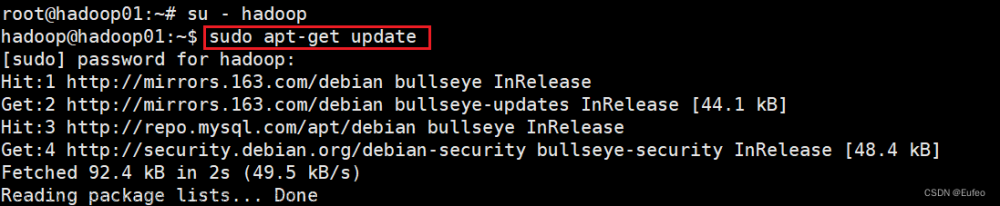
安装hadoop,命令为我用的是brew,没有的话可以自行搜索先安装这个,很简单,然后安装Hadoop,命令为:brew install hadoop,如果出现如下的hadoop就代表安装好了,这里我安装了很多遍网不好的时候包下载不下来,选择wifi足的地方,哈哈哈!

此时可以在终端输入 :hadoop,我的jdk环境和hadoop没设置,报错如下ERROR: JAVA_HOME @@HOMEBREW_JAVA@@ does not exist.。
1.3jdk环境配置
你安装了 JDK,你需要设置 JAVA_HOME 环境变量。在终端中输入以下命令来查找 JDK 的安装路径:命令为:/usr/libexec/java_home,我的路径如下:

编辑你的 ~/.bash_profile 文件,可以使用以下命令来打开该文件:命令为:vi ~/.bash_profile
在打开的文件中,添加以下行来设置 JAVA_HOME 环境变量(将路径替换为你自己的安装路径)
export JAVA_HOME=/Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home保存并关闭文件。然后执行以下命令来使修改生效:命令为:source ~/.bash_profile
然后再执行hadoop ,不报这个错了

1.4 hadoop配置文件配置
我hadoopd安装的目录在这,在安装hadoop时控制台会告诉你hadoop安装在哪里,我的路径你这个 /opt/homebrew/Cellar/hadoop/3.3.6/ ,从这里边找到配置文件进行修改,
我的配置文件目录如下: /opt/homebrew/Cellar/hadoop/3.3.6/libexec/etc/hadoop下

配置hadoop-env.sh配置文件,可以用vi指令,也可以打开文件更改,找到export jJAVA_HOME把#号去掉,将java的环境变量加进来,注意加引号,我就是没加引号一直报环境变量的错误,哎.
export JAVA_HOME="/Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home"
找到core-site.xml文件,添加如下配置,注意(fs.defaultFS的value配置的值,代码要访问hdfs必须和这个ip匹配,我因为是另一个机器访问所以这里要配上本机ip,端口号的使用也要能对身上,我后期使用时一直报连接拒绝就是这里的问题,端口配置的和使用的不一样,这里写错了
)
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/libexec/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.4:8082</value>
</property>
</configuration>
HDFS的配置,在hdfs-site.xml里配置了临时存储,与访问权限
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/libexec/tmp/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/libexec/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml配置,这里的配置主要是mapReduce的。
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml配置如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>配置文件完毕!
1.5 hadoop启动
对文件系统进行格式化,先进入到 /usr/local/Cellar/hadoop/3.2.1_1/libexec/bin 路径中,在终端输入如下命令:hdfs namenode -format

得到图片的信息代表成功了!

然后 cd /opt/homebrew/Cellar/hadoop/3.3.6/sbin 到此目录下,启动hadoop,执行命令:./start-dfs.sh

页码输入:http://localhost:9870,出现如下结果:我们可以通过浏览器访问http://你的容器IP:9870/来查看 HDFS 面板以及详细信息

相同目录下执行命令:./start-yarn.sh 启动yarn,hadoop的调度系统

网页输入:http://localhost:8088,出现如下界面:

到此hadoop安装完成!
可以用 hdfs dfsadmin -report 命令来获取有关集群状态的详细信息。
关闭hadoop命令为:stop-dfs.sh
1.6 问题一,native不存在
安装完操作hdfs,比如查看文件 ,命令为:hadoop fs -ls /
结果会报这个,说是不能加载hadoop的native,
2023-07-17 17:13:28,448 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable网上搜索找到了原因,是因为我采用的brew是没有这个/lib/native环境的,要么找对应版本下载,要么需要到官网下载编译,我是在git上找到的,虽然和我的版本差的多,但能用,
找到目录以后直接放入,配置文件配置一下即可,我放到了此目录下: /opt/homebrew/Cellar/hadoop/

执行命令:vi ~/.bash_profile
添加如下这一行,路径为你自己放的路径
export HADOOP_OPTS="-Djava.library.path=/opt/homebrew/Cellar/hadoop/lib/native"
然后执行这个命令:source ~/.bash_profile
再执行如下这个命令,此命令为查看Hadoop里的hdf的相对文件,如果里边没有文件为空,里边有文件则显示文件夹以及文件数量
hadoop fs -ls / 
1.7 问题二,Datanode没有启动起来
测试上传文件输入如下命令:
# 上传文件
hadoop fs -put hello.txt /hello/报这个错的主要原因是因为Datanode没有启动起来,你可以用jps这个命令查看下,如果没有Datanode进程就代表没启动起来。
There are 0 datanode(s) running and 0 node(s) are excluded in this operation.jps 看一直没有DataNode,/opt/homebrew/Cellar/hadoop/3.3.6/libexec/tmp/data下的current文件删除,关闭(stop-dfs.sh)启动下(start-dfs.sh)就有了 。
before

after

在执行上传文件,就ok了,我们可以执行查看文件内容也是ok的!
# 上传文件
hadoop fs -put hello.txt /hello/
# 下载文件
hadoop fs -get /hello/hello.txt
# 输出文件内容
hadoop fs -cat /hello/hello.txt 文章来源:https://www.toymoban.com/news/detail-577183.html
文章来源:https://www.toymoban.com/news/detail-577183.html
文章来源地址https://www.toymoban.com/news/detail-577183.html
到了这里,关于大数据第一步-Mac安装Hadoop3的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!