目录
一、理论
1.数据备份
2.完全备份与恢复
3.完全备份与恢复应用
4.增量备份与恢复
5.增量备份与恢复应用
6.使用脚本备份
7.日志管理
二、实验
1.完全备份与恢复
2.增量备份与恢复
3.使用脚本备份
三、问题
1.mysqldump报错
四、总结
一、理论
1.数据备份
(1)重要性
① 备份的主要目的是灾难恢复
② 在生产环境中,数据的安全性至关重要
③ 任何数据的丢失都可能产生严重的后果
④ 造成数据丢失的原因:
1)程序错误
2)人为操作错误
3)运算错误
4)磁盘故障
5)灾难(如火灾、地震)和盗窃
(2)分类
①从物理与逻辑的角度
1)物理备份: 对数据库操作系统的物理文件(如数据文件、日志文件等)的备份。
按照备份时数据库的运行状态,可以分为三种:
表1 物理备份方法
| 分类 | 数据库状态 | 数据库操作 |
| 冷备份(脱机备份) | 停库、停服务 | 不可读不可写,下线 |
| 温备份:数据库锁定表格 | 不停库、不停服务,会锁表 | 可读不可写 |
| 热备份(联机备份) | 不停库、不停服务,不会锁表 | 可读可写 |
2)逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份
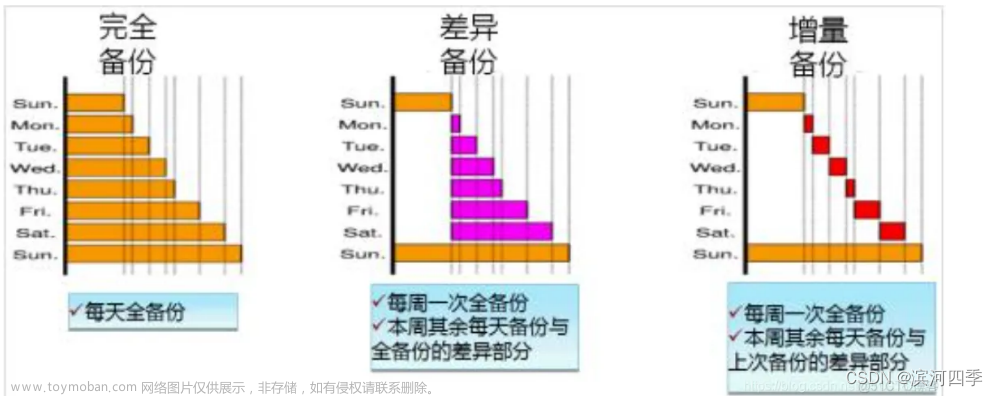
② 从数据库的备份策略角度

表2 备份策略角度分类
| 类型 | 功能 |
| 完全备份 | 每次对数据库进行完整的备份 |
| 差异备份 | 备份自从上次完全备份之后被修改过的文件 |
| 增量备份 | 只有在上次完全备份或者增量备份后被修改的文件才会被备份 |

针对上述三种备份方案,恢复数据方法:
# 1、全量备份的数据恢复
只需找出指定时间点的那一个备份文件即可,即只需要找到一个文件即可
# 2、差异备份的数据恢复
需要先恢复第一次备份的结果,然后再恢复最近一次差异备份的结果,即需要找到两个文件
# 3、增量备份的数据恢复
需要先恢复第一次备份的结果,然后再依次恢复每次增量备份,直到恢复到当前位置,即需要找到一条备份链
综上,对比三种备份方案
1、占用空间:全量 > 差异 > 增量
2、恢复数据过程的复杂程度:增量 > 差异 > 全量(3)常用备份方法
针对不同的场景下, 应该制定不同的备份策略对数据库进行备份:
表3 备份方法
| 备份策略 | 针对场景 |
| 直接cp,tar复制数据库文件 | 如果数据量较小, 可以使用第一种方式, 直接复制数据库文件 |
| mysqldump+复制BIN LOGS | 如果数据量还行, 可以使用第二种方式, 先使用mysqldump对数据库进行完全备份, 然后定期备份BINARY LOG达到增量备份的效果 |
| lvm2快照+复制BIN LOGS | 如果数据量一般, 而又不过分影响业务运行, 可以使用第三种方式, 使用lvm2的快照对数据文件进行备份, 而后定期备份BINARY LOG达到增量备份的效果 |
| xtrabackup+复制BIN LOGS** | 如果数据量很大, 而又不过分影响业务运行, 可以使用第四种方式, 使用xtrabackup进行完全备份后, 定期使用xtrabackup进行增量备份或差异备份 |
① 物理冷备: (完全备份)
备份时数据库处于关闭状态,直接打包数据库文件
备份速度快,恢复时也是最简单的
② 专用备份工具mydump或mysqlhotcopy (完全备份,逻辑备份)
mysqldump常用的逻辑备份工具 (导出为sql脚本)
mysqlhotcopy仅拥有备份MyISAM和ARCHIVE表
③ 启用二进制日志进行增量备份 (增量备份)
进行增量备份,需要刷新二进制日志
④ 第三方工具备份
免费的MySQL热备份软件Percona XtraBackup
(阿里云的工具:dts,支持热迁移)
(4)mysqldump命令
① 语法
mysqldump -h 服务器 -u用户名 -p密码 选项与参数 > 备份文件.sql②选项与参数
1、-A/--all-databases 所有库
2、-B/--databases bbs db1 db2 多个数据库
3、db1 数据库名
4、db1 t1 t2 db1数据库的表t1、t2
5、-F 备份的同时刷新binlog
6、-R 备份存储过程和函数数据(如果开发写了函数和存储过程,就备,没写就不备)
7、--triggers 备份触发器数据(现在都是开发写触发器)
8、-E/--events 备份事件调度器
9、-d 仅表结构
10、-t 仅数据
11、--master-data=1 备份文件中 change master语句是没有注释的,默认为1
用于已经制作好了主从,现在想扩展一个从库的时候使用
如此备份,扩展添加从库时导入备份文件后
便不需要再加mater_pos了
change matser to
master_host='10.0.0.111'
master_user='rep'
master_password=123
master_log_pos=120
master_log_file='master-bin.000001'
12、--master-data=2 备份文件中 change master语句是被注释的
13、--lock-all-tables 备份过程中所有表从头锁到尾,简单粗暴
在mysqldump导出的整个过程中以read方式锁住数据库中所有表,类似 flush tables with read lock 的全局锁),
这是一个全局读锁,只允许读不允许写,以此保证数据一致性。
比如当前数据库有如下schema:
information_schema(不会导出)
mysql
performance_schema(不会导出)
sys(不会导出)
test
test1
test2
那么我们在使用mysqldump导出时:
mysqldump --lock-all-tables --set-gtid-purged=on -AER > test.sql
指定--lock-all-tables参数,那么从一开始就对整个mysql实例加global read lock锁。
这整个全局读锁会一直持续到导出结束。
所以在这个过程中,数据库实际严格处于read only状态。
所以导出的数据库在数据一致性上是被严格保证的,也就是数据是一致性的。
由于这个参数会将数据库置于read only状态(也相当于不可使用状态),所以默认不加该参数。
这相当于脱机备份的感觉,所以生产数据库的备份策略上,也很少使用该参数。
该参数本身默认off,但使用该参数的话,也会自动将 --single-transaction 及 --lock-tables 参数置于 off 状态,他们是互斥的。
对于支持事务的表例如InnoDB和BDB,推荐使用--single-transaction选项,因为它根本不需要锁定表
14、--single-transaction: 快照备份 (搭配--master-data可以做到热备)
保证各个表具有数据一致性快照。
指定 --single-transaction 参数,那么导出过程中只能保证每个表的数据一致性(利用多版本特性实现,目前只能针对InnoDB事务表)。
比如有一个大表,mysqldump对该表的导出需要1分钟,那么在这1分钟的过程中,该表时可以被正常访问的。
(正常访问包括增删改查,但是alter table等对表结构发生更改的语句要被挂起。)
mysqldump能够保证从开始对该表进行导出,一直到对该表的导出结束,该表的数据都是开始的一致性数据快照状态。
所以该参数明显不能保证各个表之间的数据一致性(特别是外键约束的父表和子表之间)。
但是该参数能够让数据库处于可使用(就是应用感觉数据库可用)状态,相当于联机备份,所以被经常使用。
该参数默认off。
15、--lock-tables:如果是备份所有库,那么备份到某个库时只锁某个库,其他库可写,而--lock-all-tables是从始自终都全都锁定
保证各个schema具有数据一致性快照。
指定 --lock-tables 参数,那么在导出过程中能够保证各个schema的数据一致性。
比如导出 cms 库(该库有155张表)时:
mysqldump --lock-tables --set-gtid-purged=off -ER -B cms>test.sql
从命令开始,就对 cms 库的155张表加类似 lock table xxx read 的读锁。
这会导致在导出整个cms库的过程中,cms库实际上整体处于read only状态。
但是如果我们指定如下命令:
mysqldump --lock-tables --set-gtid-purged=on -AER >test.sql
来导出全部mysql库,那么当导出cms库的过程中,其他 schema 实际上是可以被正常访问的。
这个正常访问就是可以接受所有合法的sql语句。
所以该参数只能保证各个schema自己的数据一致性快照。
该参数默认on。
#==========完整语句
mysqldump -uroot -pEgon@123 -A -E -R --triggers --master-data=2 --single-transaction > /backup/full.sql
#====文件太大时可以压缩 gzip ,但是gzip不属于mysql独有的命令,可以利用管道
mysqldump -uroot -pEgon@123 -A -E -R --triggers --master-data=2 --single-transaction | gzip > /tmp/full$(date +%F).sql.gz
#====导出时压缩了,导入时需要解压,可以使用zcat命令,很方便
zcat /backup/full$(date +%F).sql.gz | mysql -uroot -p123(5)binlog内容定位固定的点
===> 1、grep过滤
===> 2、检查事件:依据End_log_pos的提示,来确定某一个事件的起始位置与结束位置
mysql> show binlog events in 'mybinlog.000001';
如果事件很多,可以分段查看
mysql> show binlog events in 'mybinlog.000001' limit 0,30;
mysql> show binlog events in 'mybinlog.000001' limit 30,30;
mysql> show binlog events in 'mybinlog.000001' limit 60,30;
===> 3、利用mysqlbinlog命令
生产中很多库,只有一个库的表被删除,我不可能把所有的库都导出来筛选,因为那样子binlog内容很多,辨别复杂度高,我们可以利用
[root@egon mysql]# mysqlbinlog -d db1 --start-position=123 --stop-position=154 mybinlog.000001 --base64-output=decode-rows -vvv | grep -v 'SET'
参数解释:
1)-d 参数接库名
mysqlbinlog -d database --base64-output=decode-rows -vvv mysql-bin.000002
2)--base64-output 显示模式
3)-vvv 显示详细信息(6)物理备份之Xtrabackup
①简介
Xtrabackup是由percona提供的mysql数据库备份工具,据官方介绍,这也是世界上惟一一款开源的能够对innodb和xtradb数据库进行热备的工具。
② 特点
1)备份过程快速、可靠;
2)备份过程不会打断正在执行的事务;
3)能够基于压缩等功能节约磁盘空间和流量;
4)自动实现备份检验;
5)还原速度快;
③使用xtrabackup使用InnoDB能够发挥其最大功效, 并且InnoDB的每一张表必须使用单独的表空间, 我们需要在配置文件中添加 innodb_file_per_table = ON 来开启
④安装
版本选择
mysql 5.7以下版本,可以采用percona xtrabackup 2.4版本
mysql 8.0以上版本,可以采用percona xtrabackup 8.0版本,xtrabackup8.0也只支持mysql8.0以上的版本
比如,接触过一些金融行业,mysql版本还是多采用mysql 5.7,当然oracle官方对于mysql 8.0的开发支持力度日益加大,新功能新特性迭代不止。生产环境采用mysql 8.0的版本比例会日益增加。(7)存储引擎支持备份情况
| 备份类型 | MyISAM | InnoDB |
| 热备 | × | √ |
| 温备 | √ | √ |
| 冷备 | √ | √ |
2.完全备份与恢复
(1)概念
完全备份是对整个数据库、数据库结构和文件结构的备份;
保存的是备份完成时刻的数据库;
是差异备份与增量备份的基础。
(2)优缺点
①优点
备份与恢复操作简单方便。
②缺点
数据存在大量的重复;
占用大量的备份空间;
备份与恢复时间长。
(3)完全备份方法
1)物理冷备份与恢复
- 关闭MySQL数据库
- 使用tar命令直接打包数据库文件夹
- 直接替换现有MySQL目录即可
2)mysqldump备份与恢复
- MySQL自带的备份工具,可方便实现对MySQL的备份
- 可以将指定的库、表导出为SQL脚本
- 使用命令mysq|导入备份的数据
3.完全备份与恢复应用
(1)物理冷备份
①完全备份
先关闭数据库,之后打包备份
systemctl stop mysqld #先关闭服务
mkdir /backup/ #创建备份目录
rpm -q xz #使用xz工具进行压缩,检查xz工具是否已安装
yum install xz -y #如果没安装,可以先yum安装
tar Jcf /backup/mysql_all_$(date +%F).tar.xz /var/lib/mysql #打包数据库文件。 /usr/local/mysql/data 为编译安装数据库文件存放目录, /var/lib/mysql 为yum安装数据库文件存放目录。
cd /backup/ #切换到备份目录
ls #查看目录内容
tar tf mysql_all_2023-07-17.tar.xz #查看tar包内的文件
②完全恢复
将数据库迁移到另一台主机,测试完全恢复。
#主机A,使用scp命令将tar包传给另一台主机B
scp /backup/mysql_all_2023-07-17.tar.xz 192.168.204.11:/opt
##主机B的操作##
systemctl stop mysqld #关闭mysql
cd /opt/
mkdir /opt/bak/var/lib #创建备份目录
tar Jxf mysql_all_2023-07-17.tar.xz -C /opt/bak/ #将tar包解压到备份目录
cd /opt/bak/ #切换到tar包的解压目录
\cp -af mysql/ /var/lib/mysql #将data目录复制到/var/lib/mysql/目录下,覆盖原有文件
systemctl start mysqld #启动mysql
mysql -u root -p #登录数据库查看
show databases;
use school;
show tables;
select * from student;
(2)逻辑备份(使用mysqldump工具)
①mysqldump完全备份
1)完全备份一个或多个完整的库(包括库中所有的表)
mysqldump -uroot -p[密码] --databases 库名1 [库名2].. >/备份路径/备份文件名.sql#导出的就是数据库脚本文件
示例:
mysqldump -u root -p --databases school > /opt/mysql_bak/school.sql #完全备份一个库
mysqldump -u root -p --databases mysql school > /opt/mysql_bak/mysql-school.sql #完全备份多个库,school库和mysql库
2)完全备份MySQL服务器中所有的库(包括库中所有的表)
mysqldump -u root -p[密码] --all-databases > / 备份路径/备份文件名.sql
示例:
mysqldump -u root -p --all-databases > /opt/mysql_bak/all.sql #完全备份所有的库
3)完全备份指定库中的部分表
注意:只备份表,sql语句中只有对表的操作,没有对库的操作。恢复时需要人为确认库存在。
mysqldump -u root -p[密码] [-d] 库名 表名1 [表名2] ... > /备份路径/备份文件名.sql
#使用“-d"选项,说明只保存数据库的表结构
#不使用“-d”选项,说明表数据也进行备份
示例:
mysqldump -u root -p school student > /opt/mysql_bak/school_student.sql
#完全备份school库中的student表
4)查看备份文件
备份文件中保存的是sql语句。即以sql语句的形式,把库、表结构、表数据保存下来。
cd /opt/mysql_bak
cat school.sql | grep -v "^--" |grep -v "^/" |grep -v "^$"
② mysqldump完全恢复
先启动mysql
systemctl start mysqld
1)恢复数据库
先删除数据库,之后进行恢复。
##删除数据库zzq好帅##
mysql -u root -p -e 'drop database school;'
#"-e"选项,用于指定连接MySQL后执行的命令,命令执行完后自动退出
mysql -u root -p -e 'SHOW DATABASES;' #查看当前有哪些数据库
##恢复数据库zzq好帅##
mysql -u root -p < /opt/mysql_bak/school.sql #重定向输入库文件
mysql -u root -p -e 'SHOW DATABASES;' #查看当前有哪些数据库
2)恢复数据表
当备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。
##备份school库中的student表##
mysqldump -uroot -p school student > /opt/mysql_bak/school_student.sql
##删除school库中的student表##
mysql -u root -p -e 'drop table school.student;'
mysql -u root -p -e 'show tables from school;' #查看school库中的表,已无student表
##恢复school库中的school表##
mysql -u root -p school < /opt/mysql_bak/school_student.sql #重定向导入备份文件,必须指定库名,且目标库必须存在
mysql -u root -p -e 'show tables from school;'
4.增量备份与恢复
(1)概念
是自上一次备份后增加/变化的文件或者内容。
(2)特点
没有重复数据,备份量不大,时间短;
恢复需要上次完全备份及完全备份之后所有的增量备份才 能恢复,而且要对所有增量备份进行逐个反推恢复。
(3)增量备份方法
①MySQL没有提供直接的增量备份方法
②可通过MySQL提供的二进制日志间接实现增量备份
③MySQL二进制日志对备份的意义:
1)二进制日志保存了所有更新或者可能更新数据库的操作
2)二进制日志在启动MySQL服务器后开始记录,并在文件达到 max_binlog_size所设置的大小或者接收到flush logs命令后重新 创建新的日志文件
3)只需定时执行flush logs方法重新创建新的日志,生成二进制文 件序列,并及时把这些日志保存到安全的地方就完成了一个时间 段的增量备份
(4)增量恢复方法
① 一般恢复
将所有备份的二进制日志内容全部恢复
②基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作;
可以基于精准的位置跳过错误的操作。
③基于时间点恢复
跳过某个发生错误的时间点实现数据恢复。
5.增量备份与恢复应用
(1)增量备份
①开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin #开启二进制日志。如果使用相对路径,则保存在/var/lib/mysql目录下
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED
server-id = 1
systemctl restart mysqld
ls -l /usr/bin/mysql*
-------------- 以下是注释 -----------------
#二进制日志(binlog)有3种不同的记录格式:
STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
STATEMENT (基于SQL语句):记录修改的sql语句。高并发的情况下,记录操作的sql语句时可能顺序会有错误,导致恢复数据时,数据丢失或有误差。效率高,但数据可能有误差。
ROW(基于行):记录每一行数据,准确,但恢复时效率低。
MIXED(混合模式):正常情况下使用STATEMENT,高并发的情况下会智能地切换到ROW。
②可每周对数据库或表进行完全备份
mysqldump -u root -p school student > /bak/school_student_$(date +%F).sql
mysqldump -u root -p --databases school > /bak/school_$(date +%F).sql
③可每天进行增量备份操作,生成新的二进制日志文件(例如mysql-bin.000002)
mysqladmin -u root -p flush-logs
④插入新数据,以模拟数据的增加或变更
use school;
INSERT INTO student VALUES(6, 'zhouliu',16, 666666, 'super member');
⑤再次生成新的二进制日志文件(例如mysql -bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后数据库数据再发生变化则保存在mysql-bin.00003文件中
⑥查看二进制日志文件的内容
cp /var/lib/mysql/mysql-bin.000002 /bak/
mysqlbinlog --no-defaults --base64-output=decode-rows -v /bak/mysql-bin.000002
#--base64-output=decode-rows:使用64位编码机制去解码并按行读取
#-v:显示详细内容
(2)增量恢复
①一般恢复
将所有备份的二进制日志内容全部恢复。
1)模拟丢失更改的数据的恢复步骤
use school;
delete from student where name='zhouliu'; #删除今天新增加的数据
#增量恢复(今天新增加的数据记录保存在mysql-bin.000002日志中)
mysqlbinlog --no-defaults /bak/mysql-bin.000002 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表中数据
2)模拟丢失表中所有数据的恢复步骤
mysql -u root -p -e 'drop table school.student;' #删除整个zzq帅表
mysql -u root -p -e 'show tables from school;' #查看zzq好帅库中的表
#先完全恢复历史数据
mysql -u root -p school < /bak/school_student_2023-07-17.sql
#再进行增量恢复今天新增的数据(mysql-bin.000002日志中保存了今天新增加的数据记录)
mysqlbinlog --no-defaults /bak/mysql-bin.000002 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表中数据
②断点恢复
向zzq帅表中插入3条数据,之后刷新二进制日志,移动前一个日志:
use yuji;
INSERT INTO student VALUES(7, 'guoqi',17,777777,'fuzhou', 'gold member');
INSERT INTO student VALUES(8, 'xueba',18,888888,'shenyang', 'silver member');
INSERT INTO student VALUES(9, 'hujiu',19,999999,'changchun', 'super member');
mysqladmin -u root -p flush-logs #刷新日志,生成新的二进制日志
cp /usr/local/mysql/data/mysql-bin.000003 /bak/ #将前一个日志复制到/bak/目录下
mysqlbinlog --no-defaults --base64-output=decode-rows -v /bak/mysql-bin.000003 > /bak/binlog.txt #将二进制文件内容重定向到binlog.txt文件中
1)基于位置的断点恢复
mysqlbinlog --no-defaults --start-position='位置点' 文件名 | mysql -u root -p
#从某一个位置点开始恢复,一直到日志结尾
mysqlbinlog --no-defaults --stop-position='位置点' 文件名 | mysql -u root -p
#从日志开头,一直恢复到某一个位置点前结束
mysqlbinlog --no-defaults --start-position='xxx'--stop-position='位置点' 文件名 | mysql -u root -p
#从某一个位置点开始恢复,一直到某一个位置点前结束
示例1:
只想恢复"xueba"和"hujiu"(即恢复最后两行,第8~9行)
use school;
delete from student where id between 7 and 9; #删除id为7到9的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到'xueba'的位置点
#从'xueba'的位置点3496一直恢复到结尾
mysqlbinlog --no-defaults --start-position='3496' /bak/mysql-bin.000003 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表数据
示例2:
只想恢复"王政"(即只恢复第5行)
use school;
delete from student where id between 7 and 9; #删除id为7到9的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到'guoqi'后面的位置点
#从头开始恢复,在"guoqi"的SQL语句后面截止
mysqlbinlog --no-defaults --stop-position='3496' /bak/mysql-bin.000003 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表数据
示例3:只想恢复"李嘉欣"(即只恢复第6行)
use school;
delete from student where id between 7 and 9; #删除id为7到9的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到"xueba"的位置点
#从“xueba”前面的位置点开始恢复,一直到"xueba"后面的位置点
mysqlbinlog --no-defaults --start-position='3496' --stop-position='3827' /bak/mysql-bin.000003 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表数据
2)基于时间点的断点恢复
注意:日期必须是"yyyy-mm-dd"的格式。
use school;
delete from student where id between 7 and 9; #删除id为7到9的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到"xueba"的位置点
#从“xueba”前面的位置点开始恢复,一直到"xueba"后面的位置点
mysqlbinlog --no-defaults --start-position='3496' --stop-position='3827' /bak/mysql-bin.000003 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表数据
示例:
只想恢复"xueba(即只恢复第8行)
use school;
delete from student where id between 7 and 9; #删除id为7到9的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到"李嘉欣"的时间点
#从“李嘉欣”前面的时间点开始恢复,一直到"李嘉欣"后面的时间点
mysqlbinlog --no-defaults --start-datetime='2023-07-17 19:16:21' --stop-datetime='2023-07-17 19:17:01' /bak/mysql-bin.000003 | mysql -u root -p
mysql -u root -p -e 'select * from school.student;' #查看表数据
6.使用脚本备份
(1)方法
①使用脚本每周三进行一次完全备份,之后每天进行增量备份。
如果数据量很大,可以一周做2次完全备份,比如星期一和星期四各一次。
②增量备份减少磁盘空间的占用,但恢复起来比较麻烦。需要一个一个恢复。
③一般使用crontab在凌晨进行备份。
(2)获取最新的二进制文件名称
查看索引文件,可获取最新的二进制文件。
tail -1 /var/lib/mysql/mysql-bin.index
或者
sed -n '$p' /var/lib/mysql/mysql-bin.index
(3)完全备份脚本(每周三完全备份一次)
vim /opt/mysqlquan.sh #编写脚本
#!/bin/bash
mysqldump -u root -p123456 --all-databases > /bak/all_$(date +%F).sql
chmod 700 /opt/mysqlquan.sh
crontab -e #定时任务执行脚本
0 1 * * 3 /opt/mysqlquan.sh #每周三凌晨1点备份一次
(4)增量备份脚本(每天凌晨3点备份一次)
vim /opt/binlog.sh
#!/bin/bash
#使用sed命令打印二进制日志文件最后一行内容作为filename变量的值
filename=$(sed -n '$p' /var/lib/mysql/mysql-bin.index | awk -F '/' '{print $2}')
#将二进制日志移动到备份目录下,并将移动后的文件名称加上日期
mv /var/lib/mysql/data/$filename /bak/binlog_$(date +%F)
#生成新的二进制日志文件
mysqladmin -uroot -p123456 flush-logs
chmod 700 /opt/binlog.sh
crontab -e
0 1 * * 3 /opt/mysqlquan.sh #完全备份,每周三凌晨1点备份一次
0 3 * * * /opt/binlog.sh #增量备份,每天凌晨3点备份一次
7.日志管理
(1)MySQL常用日志类型及开启
① 错误日志
指定日志的保存位置和文件名
log-error=/usr/local/mysql/data/mysql_error.log
#用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启②通用查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
#用来记录MySQL的所有连接和语句,默认是关闭的③二进制日志(binlog)
log-bin=mysql-bin
或
log_bin=mysql-bin
#用来记录所有当MySQL启动、停止或运行时发送的错误信息,默认是关闭的④慢查询日志
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
systemctl restart mysqld
#用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便于优化,默认是关闭的(2)查看日志状态
①查看通用查询日志是否开启
mysql -u root -p
show variables like 'general%'; ②查看二进制日志是否开启
show variables like 'log_bin%';③查看慢查询日功能是否开启
show variables like '%slow%'; 查看慢查询时间设置
show variables like 'long_query_time';在数据库中设置开启慢查询的方法
set global slow_query_log=ON;
该方法重启服务失效二、实验
1.完全备份与恢复
(1)物理冷备份
①完全备份
查看数据库

查看表

先关闭数据库,之后打包备份

②完全恢复
将数据库迁移到另一台主机,测试完全恢复。

切换到另一台主机B:


登录数据库查看

查看数据表

查看表内容
(2)逻辑备份(使用mysqldump工具)
①mysqldump完全备份
1)完全备份一个或多个完整的库(包括库中所有的表)

2)完全备份MySQL服务器中所有的库(包括库中所有的表)

3)完全备份指定库中的部分表
注意:只备份表,sql语句中只有对表的操作,没有对库的操作。恢复时需要人为确认库存在。
示例:


4)查看备份文件
备份文件中保存的是sql语句。即以sql语句的形式,把库、表结构、表数据保存下来。

② mysqldump完全恢复
先启动mysql

1)恢复数据库
先删除数据库,之后进行恢复。

查看数据库(school已删除)

重定向导入库文件并查看(school已恢复)

2)恢复数据表
当备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。

重启
2.增量备份与恢复
(1)增量备份
① 开启二进制日志功能



②可每周对数据库或表进行完全备份



③可每天进行增量备份操作,生成新的二进制日志文件(例如mysql-bin.000002)

④插入新数据,以模拟数据的增加或变更
⑤再次生成新的二进制日志文件(例如mysql -bin.000003)
之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后数据库数据再发生变化则保存在mysql-bin.00003文件中

⑥查看二进制日志文件的内容

(2)增量恢复
①一般恢复
将所有备份的二进制日志内容全部恢复。
1)模拟丢失更改的数据的恢复步骤
删除新增数据‘zhouliu’
增量恢复,被删除的数据已恢复
2)模拟丢失表中所有数据的恢复步骤
删除student表

完全恢复历史数据

再进行增量恢复今天新增的数据(mysql-bin.000002日志中保存了今天新增加的数据记录)

表中数据已恢复
②断点恢复
向student表中插入3条数据,之后刷新二进制日志,移动前一个日志:

刷新日志生成新的二进制日志,将前一个日志复制到/bak/目录下

将二进制文件内容重定向到binlog.txt文件中

1)基于位置的断点恢复
示例1:
只想恢复"xueba"和"hujiu"(即恢复最后两行,第8~9行)
删除id为7到9的数据记录

查看二进制文件内容,找到'xueba'的位置点

从'xueba'的位置点3496一直恢复到结尾,查看表数据
示例2:
只想恢复"guoqi"(即只恢复第7行)

从头开始恢复,在"guoqi"的SQL语句后面截止 ,查看表数据
示例3:只想恢复"xueba"(即只恢复第8行)


2)基于时间点的断点恢复
注意:日期必须是"yyyy-mm-dd"的格式。
示例:
恢复"hujiu"(恢复第9行)


3.使用脚本备份

(1)完全备份脚本
vim /opt/mysqlquan.sh #编写脚本
#!/bin/bash
mysqldump -u root -p123456 --all-databases > /bak/all_$(date +%F).sql
chmod 700 /opt/mysqlquan.sh
crontab -e #定时任务执行脚本
0 1 * * 3 /opt/mysqlquan.sh #每周三凌晨1点备份一次




(2)增量备份脚本
vim /opt/binlog.sh
#!/bin/bash
#使用sed命令打印二进制日志文件最后一行内容作为filename变量的值
filename=$(sed -n '$p' /var/lib/mysql/mysql-bin.index | awk -F '/' '{print $2}')
#将二进制日志移动到备份目录下,并将移动后的文件名称加上日期
mv /var/lib/mysql/$filename /bak/binlog_$(date +%F)
#生成新的二进制日志文件
mysqladmin -uroot -p123456 flush-logs
chmod 700 /opt/binlog.sh
crontab -e
0 1 * * 3 /opt/mysqlquan.sh #完全备份,每周三凌晨1点备份一次
0 3 * * * /opt/binlog.sh #增量备份,每天凌晨3点备份一次




三、问题
1.mysqldump报错
(1)故障描述
在对MySQL数据库备份时,执行mysqldump命令,报错如下:mysqldump: Got error: 2002: Can’t connect to local MySQL server through sock

(2)原因分析
上述报错已指明是因为mysql的socket接口连接不对/socket文件读取异常,导致socket无法连接所致。
1)确认当前MySQL的socket:

2)当没有服务运行时,启动mysqld服务
3)当有服务运行时,用正确的socket文件连接mysql,再次执行mysqdump命令:

mysqldump -u root -p --databases school socket=/var/lib/mysql/mysql.sock > /opt/mysql_bak/school.sql
四、总结
数据库备份可以分为物理备份和逻辑备份。物理备份又可以成为冷备份(脱机备份)、热备份(连接备份)和温备份。
从数据库的备份策略角度来看,备份又可分为完全备份、差异备份和增量备份。
全量备份的数据恢复:只需找出指定时间点的那一个备份文件即可,即只需要找到一个文件即可;
差异备份的数据恢复:需要先恢复第一次备份的结果,然后再恢复最近一次差异备份的结果,即需要找到两个文件;
增量备份的数据恢复:需要先恢复第一次备份的结果,然后再依次恢复每次增量备份,直到恢复到当前位置,即需要找到一条备份链;
综上,对比三种备份方案:
占用空间:全量 > 差异 > 增量
恢复数据过程的复杂程度:增量 > 差异 > 全量
文章来源:https://www.toymoban.com/news/detail-577598.html
文章来源地址https://www.toymoban.com/news/detail-577598.html
到了这里,关于数据库应用:MySQL备份与恢复的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!