经典目标检测R-CNN系列(2)Fast R-CNN
-
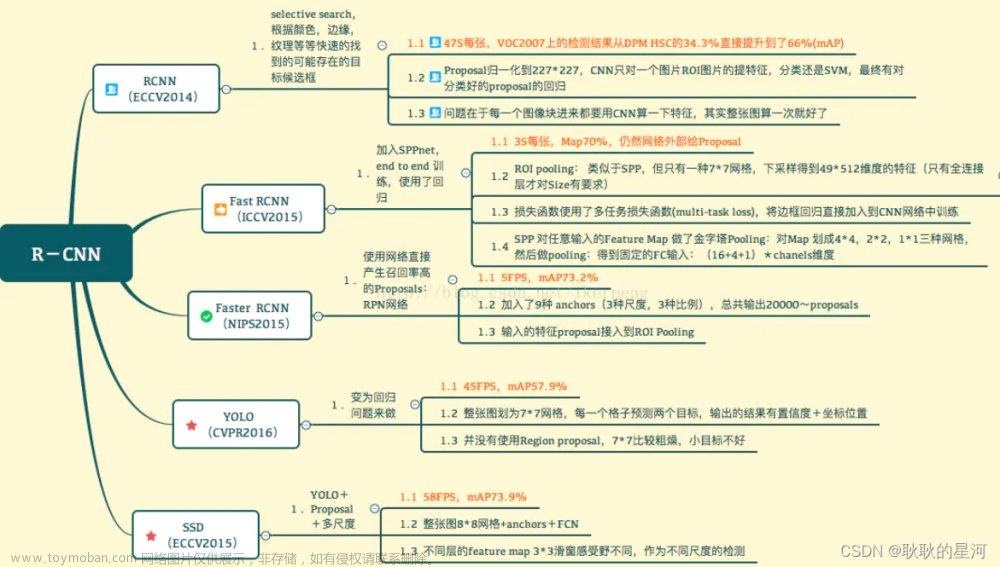
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。
-
同样使用VGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(Pascal VOC数据集上)。
1 Fast R-CNN的前向过程
Fast R-CNN算法流程可分为3个步骤
-
一张图像生成1K~2K个候选区域(使用Selective Search方法)
-
将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上,获得相应的特征矩阵
-
将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果

Fast R-CNN除了先以一个相对独立的步骤生成区域建议之外,其余4个主要环节均以整合在一起的神经网络结构来实现:卷积特征提取、RoI特征提取、类别预测和位置预测。目标检测的最后还包括后处理环节,实现包围框绝对位置计算、类别-位置绑定和基于NMS的冗余包围框去除。

1.1 卷积特征提取
-
R-CNN依次将候选框区域输入卷积神经网络得到特征。
-
Fast-RCNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算。

-
Fast-RCNN不限制输入图像的尺寸。
-
原始图像整体以全卷积(fully convolutional)方式输入CNN得到卷积特征图,以某一卷积层的特征图作为最终输出,得到卷积特征。
- 例如,主干网络结构采用VGG16,以卷积层conv5_3的输出作为特征图,则得到的特征图具有512个通道,降采样倍率为16【卷积特征提取仅使用conv1至conv5部分】。

1.2 RoI特征提取
-
RoI池化层以卷积特征和经过对应比例缩小的区域建议(在Fast R-CNN中称为RoI)作为输入,对投射在特征图上的RoI进行W×H的网格划分(
W和H为RoI池化层的超参数,分别表示网格的宽度和高度,也就是输出特征图的宽度和高度),逐通道在每个网格上做最大池化,各个通道独立操作。 -
与SPP-Net不同的是,RoI池化层的网格划分仅在一个固定尺度上进行。即RoI池化可以看作是SPP-Net中SPP层的单一尺度版本。
-
RoI池化得到的特征图随后输入若干层全连接层,进行进一步的特征变换。

1.3 类别预测和位置预测
1.3.1 类别预测
得到的RoI特征“兵分两路”,分别进行类别预测与位置预测。
在类别预测分支中,RoI特征被输入一个输出维度为目标类别数 K 的全连接层、配有softmax分类器的分支网络,得到类别分布预测,从而实现类别判定。

1.3.2 位置预测
-
位置预测分支中,RoI特征被输入以全连接层表示的包围框回归器
-
该全连接层的输出为C×4,这里 C 为目标检测类别数,这里的4表示形如(dx§,dy§,dw§,dh§)的包围框位置变换参数
-
可以看出Fast R-CNN包围框位置也是类别相关的

1.3.3 后处理
实现包围框绝对位置计算、类别-位置绑定和基于NMS的冗余包围框去除。
1.3.4 奇异值分解
-
在Fast R-CNN中,类别预测与位置预测均通过全连接层实现,全连接操作的本质为向量的线性变换。
-
例如产生的RoI数量为2000个(参考R-CNN中选择性搜索得到的区域建议个数),用于位置预测分支全连接层的乘法计算量将超过6.8亿次(具体为2000×84×4096=688128000次),如此大规模的计算需要大量的时间开销,严重限制了目标检测的速度。
-
所以为了提高目标检测速度,Fast R-CNN采用基于奇异值分解。实践表明,Fast R-CNN利用该方法,以MAP损失0.3%的代价换来30%的速度提升。
2 Fast R-CNN的损失函数
2.1 分类损失

Fast R-CNN类别预测分支为每个RoI预测C个类别的概率分布p=(p0,p1,…,pC−1)
在基于神经网络的模型中,概率分布一般由具有C个输出的全连接层配合softmax函数得到
设与RoI相关的GT类别为u(u=0,1,…,C−1),则类别预测的损失可以定义为交叉熵误差
L
c
l
s
(
p
,
u
)
=
−
l
o
g
p
u
L_{cls}(p,u)=−logp_u
Lcls(p,u)=−logpu
2.2 边界框回归损失

从上述函数定义可以看出,与R-CNN和SPP-Net使用的 L2 损失相比,平滑 L1 损失对包围框位置偏差的惩罚、尤其是对偏差很大情况下(离群点,outliers)的惩罚更加平滑,从而防止梯度过大造成梯度爆炸(exploding gradients)。
2.3 Fast R-CNN的优缺点
优点
-
Fast R-CNN借鉴了SPP-Net的思路,保持了支持任意尺寸输入这一优良特性。
-
将类别预测与位置预测结果作为模型的平行输出,与之对应的训练环节也以多任务模式同步完成。
-
除了区域建议生成,其他大部分环节实现端到端,训练和测试速度均得到大幅提升。
-
除此之外,Fast R-CNN在目标检测的准确率方面也达到很高的水平。
缺点
-
在速度方面,从利用CNN提取卷积特征到获得最终结果,Fast R-CNN处理一幅图像的时间大约为0.3秒,但是如果以基于选择搜索的方法进行
区域建议生成,仅此一步操作就需要2至3秒,可以说区域建议生成成为制约Fast R-CNN整体速度的瓶颈。文章来源:https://www.toymoban.com/news/detail-577836.html -
在流程方面,无论在训练阶段还是测试阶段,区域建议环节生成还是独立于CNN之外,还是没有完全实现端到端。文章来源地址https://www.toymoban.com/news/detail-577836.html
到了这里,关于经典目标检测R-CNN系列(2)Fast R-CNN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测](https://imgs.yssmx.com/Uploads/2024/02/731110-1.png)



