中间件为什么学?如何学?如何成为一个优秀的程序员?
我觉得优秀程序员要满足两点:1.扎实的编程语言基础数据结构基础,要能实现各种基本的crud需求,这是基础;2、就是了解工程上需要了解的知识,编程是一个系统性的工程。各个公司有自己的代码框架差异很大暂不讨论,但是常用的中间件能够帮助更好地编程实现,非常有用。所以要学。第三就是性能优化架构优化,当有了对整体系统的认知,准确找到性能瓶颈根据业务需求进行改进。
而在中间件这方面:
首先我现阶段注重的是广度和共性,系统观打牢,每个组件只是简单实践了一下(docker运行服务,nginx部署负载均衡,rpc简单使用),了解一下大体怎么运作的,没有更多复杂功能的尝试。要广泛了解各种中间件比如缓存,代理,容器,消息队列,rpc的架构思想,优秀的设计理念(比如抽象层次k8s,vfs,设计模式等)和数据结构(红黑树+链表,跳表等)。因为暂时没有业务环境,专注于某个组件钻牛角尖,可能以后都不会用到。所以注重整体学习,了解共性。
性能方面,对组件相应修改和自己创造,正在学习,比如在学习linux内核,性能之巅这本书。需要不断提高自己,才能不被轻易替代。
(中间件和性能方面,我觉得已知的未知更重要,也就是知道该从哪些方面做,只是还没有去做。)
**
docker:
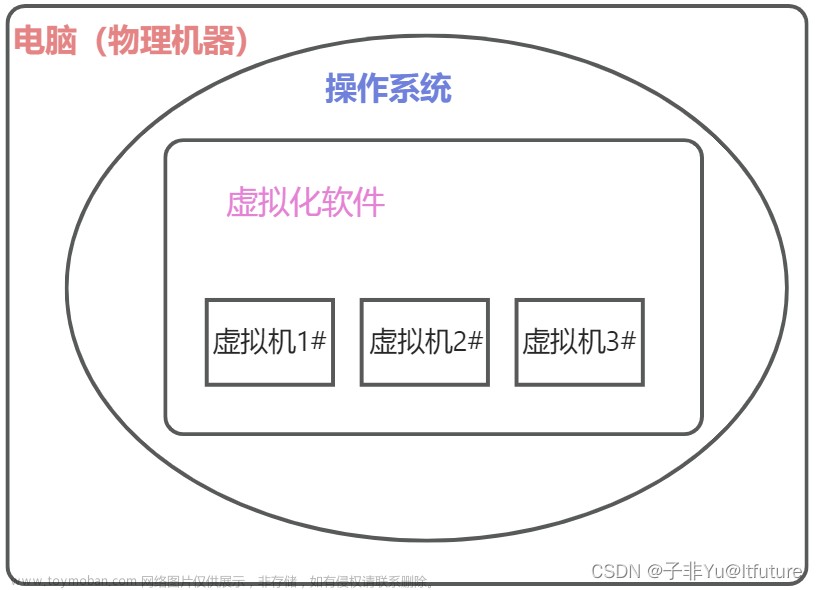
** 出现是因为相比于虚拟机,资源复用更加灵活,虚拟机是一个完整的操作系统,占用空间大,启动慢;docker容器技术可以根据也无需求,配置不同的环境,不会互相影响。镜像操作方便迁移,实现build once run everywhere
docker主要就是隔离和标准化。核心技术是namespace技术和cgroup技术。
namespace是让不同容器看起来没有关联,防止不同空间命名冲突,比如pid,用户Id,ip地址等。
每一个容器有自己的ns, 就和多进程一样,一个进程的1234地址和另一个进程的1234地址不是一个物理地址(虚拟地址)。不同ns中相同的命名也不是真正相同的资源。
可以通过proc/pid/ns文件夹查看进程所属的ns,然后想要修改的话可以用nsenter进入指定的别的ns空间。
cgroup是用起来隔离的技术。树状结构组织,若干个进程组成cgroup,若干个cgroup树状排列,同时有很多树,代表不同的系统资源,CPU,内存,网络,设备等
可以进行一些资源的监控限制等操作,比如限制mysql一组进程核绑定,占用多大CPU时间,内存和带宽,可以访问哪些设备等等。
常用操作,
先拉取镜像 docker pull ubuntu
然后启动一个容器 docker run -i -t -name 名字 cmd
如果是交互式的话就是/bin/bash
docker image查看镜像
docker ps 查看容器 docker inspect c_id查看具体容器信息
docker top 容器id 查看其中的进程
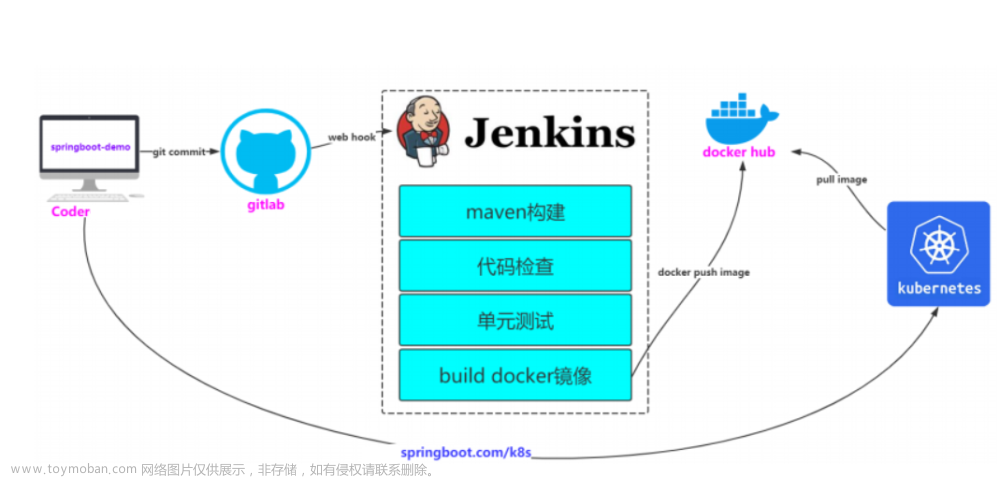
编译dockfile还可以post发布镜像到docker_hub库里面,没试过。
我用它主要在两个方面,一个是计算机系统实验中,每次实验要装不同的环境,而且是不兼容的,所以为了方便,就用了docker加载镜像。不然的话就要卸载。
还有一个就是在docker部署网站。(静态)
步骤是,1.端口映射一下,docker run -p 80指定80端口。
2、下载nginx和vim. 写一个简单的html文件,修改nginx配置为那个文件,启动nginx。然后ctrl+Q退出,保证容器还是在运行的。然后docker port web查看一下映射情况,通过宿主机地址127.0.0.1加映射端口访问
**
k8s
**
要知道k8s出现的原因,其实就是数据中心的操作系统,为了管理很多机器的软硬件资源的。
主要组成和操作系统类似。
调度器controller 进程线程进程组(docker pod service) 网络(每个pod有ip地址)存储(文件存储,对象存储,块存储,有自己的接口管理)和包管理工具helm
关注一下Kubernetes 会将 Service DNS的名字作为域名解析成为一个虚拟的 Cluster IP,然后通过负载均衡,转发到后端的 Pod。虽然 Pod 可能漂移,IP 会变,但是 Service 会一直不变。(Service就相当于一组pod,也就是实现某种功能的一个进程集合,比如mysql的一组进程,也就是说,在进行service作为虚拟ip的时候,真正到的pod会变飘逸的,但是service不会变的,有点类似于NAT,可以实现负载均衡了。)
k8s解决的核心问题是?
服务发现和负载均衡
也就是说给你一个程序,你需要决定在哪个机器的pod上运行。k8s的容器本身就可以指定资源大小CPU,内存等。它有自己的DNS和ip地址公开开容器,流量大的时候还可以负载均衡。
还有存储编排(可选择对象,文件,块存储)
自我修复,高可用。
架构:传统的客户端服务端架构
服务端由一组master节点(存储状态,调度分配资源)和一系列worker节点组成。
主节点结构:
它主要负责接收客户端的请求,安排容器的执行并且运行控制循环,将集群的状态向目标状态进行迁移。(主要有API和客户端交互接口,etcd键值数据库存储状态,调度器主要负责的是让pod在特定空闲节点运行,调度的策略包括资源的需求,亲和性(一组进程最好在一台主机进行,通信方便)还有一个controler控制器,负责故障的通知转移,以及副本,令牌控制等)
其他的 Worker 节点实现就相对比较简单了,它主要由 kubelet 和 kube-proxy 两部分以及运行时(docker)组成。
kubelet: 是工作节点执行操作的 agent,负责具体的容器生命周期管理,根据从数据库中获取的信息来管理容器,并上报 pod 运行状态等。
kube-proxy: 是一个简单的网络访问代理,同时也是一个 Load Balancer。它负责将访问到某个服务的请求具体分配给工作节点上同一类标签的 Pod。
kube-proxy 实质就是通过操作防火墙规则(iptables,service ip到pod ip的映射)来实现 Pod 的映射。(客户端通过services的cluster ip来访问,这个代理会根据iptable规则重定向到其中的pod,流量大的时候还可以负载均衡)service就是一组pod,保证健壮性。
Pod、Service、Volume 和 Namespace 是 Kubernetes 集群中四大基本对象,它们能够表示系统中部署的应用、工作负载、网络和磁盘资源,共同定义了集群的状态。Kubernetes 中很多其他的资源其实只对这些基本的对象进行了组合。
配置文件用yaml写,kubectl 是 Kubernetes 自带的客户端,可以用它来直接操作 Kubernetes 集群。
介绍一下k8s。先说是数据中心的操作系统,整体架构什么样(主节点和worker节点) 抽象层次值得学习(docker,pod,service,volume,ns)
关于存储有几种存储方式接口统一;
关于网络有pod唯一ip地址和service cluster ip地址,自己的网络模型;
关于客户端有自己的kubectl 和helm包管理工具。
如何在k8s上发布服务?
NodePort、LoadBalancer、Ingress控制器三种方式将服务公开
NodePort:30000-32767)范围内分配一个端口,每个节点都将该端口代理到您的服务
LoadBalance服务类型会自动部署一个外部负载均衡器,该外部负载均衡器与特定的IP地址关联,并将外部流量路由到集群中的Kubernetes服务
Ingress控制器通常不会消除对外部负载均衡器的需要,只是在负载均衡器后面增加了一个额外的路由和控制层。
**
k8s基本命令了解
get describe log
**
最常用的就是查看某个ns下资源pod的使用情况 : kubectl get pod -n ns. 在正式使用中,我们永远不会把资源发布在默认命名空间。所以,永远不要忘记在get命令后面加上-n。
kubectl describe pod <pod名> -n <命名空间>来获取一个 pod 的基本信息。比如node信息知道pod在哪个机器上,label知道pod主要用途是什么,controll by知道创建pod上层资源是什么,继续查看上层资源定位信息。container包含了每个docker的信息
如果出现问题的话,可以在获取到的信息的末尾看到Event段落,其中记录着导致 pod 故障的原因。
kubectl logs <pod名>来查看pod的日志 通过添加-f参数可以持续查看日志.
kubectl create 创建资源 从yaml配置文件创建 和 简易创建.
kubectl explain 解释配置,配置信息太多,抽象层次多。
kubectl delete 删除一切!
kubectl edit <资源类型> <资源名>在实际使用中更偏向于人工修改某个配置项来解决问题,例如修改镜像地址解决拉取不到镜像的问题。kubectl apply -f <新配置文件名.yaml>例如你通过kubectl apply -f https://some-network-site/resourse.yaml命令从一个网站上部署了你的资源,这样当它的管理者更新了这个配置文件后,你只需要再次执行这个命令就可以应用更新后的内容了,而且完全不用关心修改了哪些配置项。
nginx介绍和实战
**
nignx是正向代理(为客户端代理,服务端不知道),反向代理,负载均衡和动静分离。特点是内存小,高性能高并发。
nignx还可以实现高可用,keeplived选项可以增加nginx服务器的数量;
Nginx配置文件(内部也是epoll,接收客户端新连接,然后子进程线程处理它和服务器连接(负载均衡))
全局块 :影响 nginx 服务器整体运行的配置指令。比如worker_process越大代表支持并发数越多。
events块:主要影响Nginx服务器与用户的网络连接。比如: worker_connections 1024; ,支持的最大连接数。
第三部分 http块
http 块又包括 http 全局块和 server 块,是服务器配置中最频繁的部分,包括配置代理、缓存、日志定义等绝大多数功能。
server块:配置虚拟主机的相关参数。
location块:配置请求路由,以及各种页面的处理情况。
比如下面这个例子:在浏览器地址栏输入 http://192.168.4.32/example/a.html ,平均到 5000 和 8080 端口中,实现负载均衡效果。
upstream myserver {
server 192.167.4.32:5000;
server 192.168.4.32:8080;
}
server {
listen 80; #监听端口
server_name 192.168.4.32; #监听地址
location / {
root html; #html目录
index index.html index.htm; #设置默认页
proxy_pass http://myserver; #请求转向 myserver 定义的服务器列表
}
}
在server里面监听你要访问的那个网站和端口(http是80) 然后定义自己的服务器的ip+port。在location里面 proxy_pass设置为自己的地址, index设置默认的网页。
其中,负载均衡的形式可以是默认轮询,或者weight权重,或者 ip_hash,fair响应时间短的得到;
location ~代表正则表达式匹配
Nginx 缓存 expires 3d; 通过 expires 参数设置,可以使浏览器缓存过期时间之前的内容,减少与服务器之间的请求和流量。
动静分离:设置动静两个地址,然后location匹配,如果是jsp,php需要和后端交互的,就到动态网址,静态的比如jpg,css等就不需要和服务端交互了。
高可用怎么实现:
首先要安装keeplivd程序, 相当于一个路由,它通过一个脚本来检测当前服务器是否还活着,如果还活着则继续访问,否则就切换到另一台备份服务器。
修改配置文件,keepalived 将 nginx 服务器绑定到一个虚拟 ip , nginx 高可用集群对外统一暴露这个虚拟 ip,客户端都是通过访问这个虚拟 ip 来访问 nginx 服务器 。
nignx原理:只是转发操作,真正的处理请求是后端服务器做的。
一个master和若干worker进程。客户端发送一个请求首先要经过 master,管理员收到请求后会将请求通知给 worker,多个 worker 以争抢的机制来抢夺任务,得到任务的 worker 会将请求经由 tomcat(应用容器) 等做请求转发、反向代理、访问数据库等
一个 master 和多个 worker 的好处?
可以使用 nginx -s reload 进行热部署。
每个 worker 是独立的进程,如果其中一个 worker 出现问题,其它 worker 是独立运行的,会继续争抢任务,实现客户端的请求过程,而不会造成服务中断。
nignx的高级应用?
跨域问题:比如在一个前端项目里请求另一个后端;因为跨域所以请求无法响应。如果前后端都不想修改代码,可以在nignx的server块,add_header允许哪些跨域的请求、方法、cookie等。
配置SSL证书: 要在阿里云注册域名,和SSL证书;然后为nginx加上http_ssl_module(:网站如果没有备案,会被拦截,会导致不能访问,正规站点都是要备案的。)
防盗链配置 盗链通俗一点的理解就是别人的网站使用自己服务器的资源,比如常见的在一个网站引入其他站点服务器的图片等资源,这样被盗链的服务器带宽等资源就会额外被消耗,在一定程度上会损害被盗链方的利益,所以防盗链是必要的;这里通过nginx简单实现静态资源防盗链的案例,原理很简单,就是判断一下请求源是否被允许。在Location里面对于非法的直接return 403
总结:说一下是什么和特点,原理,以及配置文件配置过程完成负载均衡,缓存;高可用实现;高级应用。
(nginx,apache,tomcat区别)
首先nginx和apache都是只能处理静态请求的。二者区别是nginx简单一点内存低,apache支持的组件,配置,模块比较复杂;第二就是nginx采用的是epoll+多进程的非阻塞模型,高并发,apache是阻塞的多进程。
tomcat主要功能是处理动态元素(jsp,cgi,php等),是apache开发的符合servelet标准的容器。一般nignx动静分离后动态的就给tomcat处理。
rpc知识点(公司内部通信)
远程过程调用,在微服务分布式背景下,涉及到不同服务器的协作。rpc就是为了让调用远程方法根调用本地的一样,只要规定参数名和参数就可以。
既然有了 http,为什么还要用 rpc 调用?
通信协议并不是rpc重点。rpc是一个方法,而http是一种协议.所以,更多的是封装了 “服务发现”,“负载均衡”,“熔断降级” 一类面向服务的高级特性。可以这么理解,rpc框架是面向服务的更高级的封装。
(rpc优点:效率高二进制但是不绝对因为http2也是二进制; 简洁,方法多了后需要记住很多函数和参数(get,post等),rpc把方法存根在本地序列化传送;最重要是封装了高级特性) 缺点:可读性低,双方架构需要一致。
http优点:可读性高,双方语言架构不需要一致。
常见的rpc: grpc,brpc, thrift,dubbo等
rpc调用框架
rpc调用框架是:服务端有个stub,他可以把服务B的接口对象(函数,参数)作为参数序列化,然后通过传输协议(http2,protobuf等)给B,B反序列化然后计算得到结果返回给A。
涉及到的技术:
1**.序列化协议**很重要的一部分
在网络传输中,需要二进制传输,所以要把对象转换成字节序列。
序列化协议有哪些:
最早期的cobra com等太复杂需要汇编淘汰了 java自带的库,xml,json等(可读性好但是时空效率低)protobuf 、Hessian2
protobuf核心就是消息message和接口service.服务端与服务端之间只需要关注接口方法名(service)和参数(message)即可通信,而不需关注繁琐的链路协议和字段解析,极大降低了服务端的设计开发成本。
动态代理
RPC的调用内部核心技术采用的就是动态代理。
也就是要像调用本地方法一样调用远程。RPC 会自动给我们生成一个动态代理类,当我们在项目中注入接口的时候,运行过程中实际绑定是这个接口生成的代理类,这样在接口方法被调用的时候,它实际上是被生成代理类拦截了,这样我们就可以在生成的代理类里面,加入远程调用的逻辑。
服务注册发现
(1)注册与发现流程
服务注册:服务提供方将对外暴露的接口发布到注册中心内,注册中心为了检测服务的有效状态,一般会建立双向心跳机制。
服务订阅:服务调用方去注册中心查找并订阅服务提供方的 IP,并缓存到本地用于后续调用。
(2)如何实现:基于ZK
A. 在 ZooKeeper 中创建一个服务根路径,可以根据接口名命名(例
如:/micro/service/com.laowang.orderService),在这个路径再创建服务提供方与调用方目录(server、
client),分别用来存储服务提供方和调用方的节点信息。
B. 服务端发起注册时,会在服务提供方目录中创建一个临时节点,节点中存储注册信息。
C. 客户端发起订阅时,会在服务调用方目录中创建一个临时节点,节点中存储调用方的信息,同时watch 服务提供方的目录(/micro/service/com.laowang.orderService/server)中所有的服务节点数据。当服务端产生变化时ZK就会通知给订阅的客户端。
ZooKeeper方案的特点:
强一致性,ZooKeeper 集群的每个节点的数据每次发生更新操作,都会通知其它 ZooKeeper 节点同时执行更新。
服务端调用代码:生成一个zk类,开启,发布节点(包括服务和方法,服务是永久节点,方法是临时节点,还会加ip+port)
客户端:只要使用get_data方法就可以实现找到服务器的ip+port
客户端还可以watch监听服务,一旦有变化就能知道。
健康监测 心跳机制
负载均衡和熔断限流
负载均衡可以自己实现,一个计分器和指标采集器,对cpu,内存等打分,随机 权重,轮询,ip hash等策略进行负载均衡。
限流:最简单的是计数器,还有平滑限流的滑动窗口、漏斗算法以及令牌桶算法等等。比如响应时间超过阈值那么接下来的时间窗口的服务都不接受。
一个服务 A 调用服务 B 时,服务 B 的业务逻辑又调用了服务 C,这时服务 C 响应超时,服务 B 就可能会因为堆积大量请求而导致服务宕机,由此产生服务雪崩的问题。
优雅开启优雅关闭
启动预热,防止cache不热;通过调用方通过服务发现获取服务提供方的启动时间, 然后进行降权,减少被负载均衡选择的概率,从而实现预热过程。
总结:如何实现一个rpc框架
1、服务端、客户端、zk
先进行服务的注册和发现,客户端注册,服务端发现(ip,port),以及监听
客户端通过动态代理调用服务端的接口(里面有远程调用逻辑),然后序列化协议传参数,反序列化,计算结果,返回结果。
kafka介绍实战
消息系统作用:解耦,异步,削峰。
整体架构介绍一下。生产者,消费者。 Kafka集群中,一个kafka服务器就是一个broker,Topic只是逻辑上的概念,partition在磁盘上就体现为一个目录。不同分区可以在不同的broker上,增强并行能力。消费者组,控制节点借助zookeepr进行集群的管理。
副本节点分布在不同的broker实现高可用。
kafka优秀架构的思考:
高并发:三层网络架构:多selector- 多线程 -> 队列的设计(NIO).比传统的reactor多了一层processor
高可用:副本机制
高性能: 写方面实现了顺序写磁盘:先写到os内核,在顺序写磁盘,和rocks代表差不多,lsm树。读利用sendfile操作实现零拷贝操作,直接在内核读,不用拷贝到用户。
以及一些日志分段存储,以及isr机制保证可用性和一致性找到一个平衡,以及日志有offset,position两个信息,稀疏索引写在log里面,二分法查找。文章来源:https://www.toymoban.com/news/detail-578944.html
生产环境:根据流量大小,按照最高的若干倍,评估需要多少物理机(以及硬盘若干T,内存几十个G,CPU32个,网速千兆万兆)文章来源地址https://www.toymoban.com/news/detail-578944.html
到了这里,关于docker和k8s、nginx、rpc的学习介绍和实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!