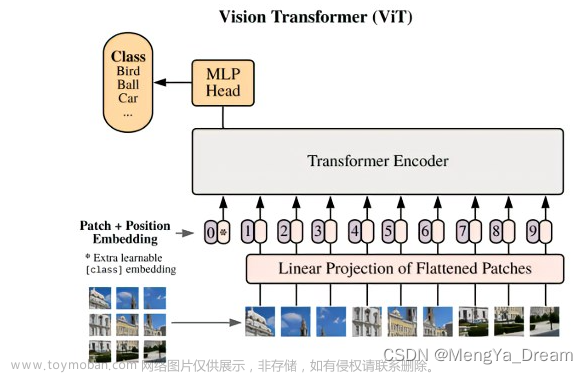
先把上一篇中的遗留问题解释清楚:上图中,代码中的all_head_dim就是有多少head。把他们拼接起来。
Encoder在Multi-Head Self-Attention之后,维度一直是BND`,一直没有变。

Layer Normalization

不论是BN(Batch Normalization)还是LN(Layer Normalization),都是对batch来做的。只是他们的归一化方式不同。我们在求mean和var时,是按照图中的灰色阴影来求的。BN的mean=(A, B, C)。假设batch是一摞书,总共做N本书,每一本书有C页,每一页有H行和W列的文字。BN做的就是把每本书的第一页抽出来,再取一个平均和方差,在做归一化。然后再把每本书的第2页抽出来,再做一遍均值,方差,归一化。一直到每本书做完。
LN还是假设我们有N本书,我们取第一本书的所有页,把他们都加起来做均值,方差,归一化。接着做第二本书的,一直做完N本书。
那么,为什么要在Transformer中用LN,而不用BN呢?又为何在CNN中用BN呢?BN主要关注的不同batch同channel的特征提取,LN关注的同batch不同channel的特征提取。CNN中,每一个channel学习的是一个固定的feature,每个channel学习某一个特征的固定表示,或颜色,或纹理,或位置,或其它表征信息。
实验中,Transformer也可以BN,但效果可能没有LN好,所以就沿用了LN。另外,第一,可能在Transformer中batch size不会特别大,第二,数据不定长,第三,同一个句子词之间有关系,但不同句子之间关系可能没有那么紧密。一个batch里可以存放不同的句子。
2种不同位置的Layer Normalization:PostNorm & PreNorm

两种不同的位置。先MSA后LN,先LN后MSA。实现表明,Pre更容易收敛。PostNorm更容易爆掉。但是在Postnorm没有爆掉的里面,比PreNorm更好,参考下这2篇文章。
Xiong, Ruibin, et al. "On layer normalization in the transformer
architecture."International Conference on Machine Learning. PMLR,
2020.
Liu L, Liu X, Gao J, et al. Understanding the difficulty of training
transformers[J]. arXivpreprint arXiv:2004.08249, 2020.
Classification Token
AveragePool是把所有的token做一个平均,再送入classifier里做分类。
但是还有一种更NLP的方法,如下图:
我们做CNN的时候,总是把feature做一个融合。或者做Transformer时,把patch进行融合。然后得到一个低维度的向量,去做分类。但在NLP里有一个Claas Token。我们单独添加一个token:Class Token(默认值给一个随机数),它的维度和我们的Visual Token(Patch Embedding)的维度是一样的。它的任务是学习分类,它去看每一个序列的信息,然后提取出图像分类相关的信息,用来作为自己的feature表征,送到Classifier。Class Token可以看到所有token的信息。SwinTransformer是用的Avg,没有用Class Token。
Position embeedding
我们前2篇说的,它少了一个位置编码。位置编码器为什么重要,先从NLP解释。比如下面两句话:
A:大叔曾经说自己很爱学习
B:大叔说自己曾经很爱学习
两个曾经的位置不同,含义也不一样。我当然不喜欢B这个表述,而更喜欢A。
在图像领域,图像中物体的位置也是有关系的,所以在视觉Transformer也是重要的。
TransformerInput = VisualToken + PosEmbed文章来源:https://www.toymoban.com/news/detail-579058.html
更推荐Position Embedding,可学习的。Visual Token和Position Embedding怎么结合,直接相加,或者concat也可以。Position Embedding的初始化,我们可以给它一个随机值。文章来源地址https://www.toymoban.com/news/detail-579058.html
Vit代码全流程
# ViT Online Class
# Author: Dr. Zhu
# Project: PaddleViT (https:///github.com/BR-IDL/PaddleViT)
# 2021.11
import copy
import paddle
import paddle.nn as nn
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class Mlp(nn.Layer):
def __init__(self, embed_dim, mlp_ratio, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim * mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim * mlp_ratio), embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# TODO
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class PatchEmbedding(nn.Layer):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.):
super().__init__()
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embedding = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
# TODO: add class token
self.class_token = paddle.create_parameter(
shape=[1, 1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.Constant(0.))
# TODO: add position embedding
self.position_embedding = paddle.create_parameter(
shape=[1, n_patches+1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02))
def forward(self, x):
# [n, c, h, w]
cls_tokens = self.class_token.expand([x.shape[0], -1, -1])
x = self.patch_embedding(x) # [n, embed_dim, h', w']
x = x.flatten(2)
x = x.transpose([0, 2, 1])
print("cls_tokens shape: ", cls_tokens.shape)
print("x shape: ", x.shape)
x = paddle.concat([cls_tokens, x], axis=1)
x = x + self.position_embedding
return x
class Attention(nn.Layer):
"""multi-head self attention"""
def __init__(self, embed_dim, num_heads, qkv_bias=True, dropout=0., attention_dropout=0.):
super().__init__()
self.num_heads = num_heads
self.head_dim = int(embed_dim / num_heads)
self.all_head_dim = self.head_dim * num_heads
self.scales = self.head_dim ** -0.5
self.qkv = nn.Linear(embed_dim,
self.all_head_dim * 3)
self.proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
self.attention_dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(axis=-1)
def transpose_multihead(self, x):
# x: [N, num_patches, all_head_dim] -> [N, n_heads, num_patches, head_dim]
new_shape = x.shape[:-1] + [self.num_heads, self.head_dim]
x = x.reshape(new_shape)
x = x.transpose([0, 2, 1, 3])
return x
def forward(self, x):
B, N, _ = x.shape
qkv = self.qkv(x).chunk(3, axis=-1)
q, k, v = map(self.transpose_multihead, qkv)
attn = paddle.matmul(q, k, transpose_y=True)
attn = attn * self.scales
attn = self.softmax(attn)
attn = self.attention_dropout(attn)
out = paddle.matmul(attn, v)
out = out.transpose([0, 2, 1, 3])
out = out.reshape([B, N, -1])
out = self.proj(out)
out = self.dropout(out)
return out
class EncoderLayer(nn.Layer):
def __init__(self, embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0, dropout=0., attention_dropout=0.):
super().__init__()
self.attn_norm = nn.LayerNorm(embed_dim)
self.attn = Attention(embed_dim, num_heads)
self.mlp_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim, mlp_ratio)
def forward(self, x):
h = x # residual
x = self.attn_norm(x)
x = self.attn(x)
x = x + h
h = x # residual
x = self.mlp_norm(x)
x = self.mlp(x)
x = x + h
return x
class Encoder(nn.Layer):
def __init__(self, embed_dim, depth):
super().__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer()
layer_list.append(encoder_layer)
self.layers = nn.LayerList(layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
# TODO
for layer in self.layers:
x = layer(x)
x = self.norm(x)
return x
class VisualTransformer(nn.Layer):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratio=4,
qkv_bias=True,
dropout=0.,
attention_dropout=0.,
droppath=0.):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size, patch_size, in_channels, embed_dim)
self.encoder = Encoder(embed_dim, depth)
self.classifier = nn.Linear(embed_dim, num_classes)
def forward(self, x):
# x:[N, C, H, W]
x = self.patch_embedding(x) #[N, embed_dim, h', w']
x = x.flatten(2) # [N, embed_dim, h' * w'], h' * w'=num_patches
# x = x.transpose([0, 2, 1]) # [N, num_patches, embed_dim]
x = self.encoder(x) # x:[N, ]
print(x.shape)
x = self.classifier(x[:, 0])
def main():
vit = VisualTransformer()
print(vit)
paddle.summary(vit, (4, 3, 224, 224)) # must be tuple
if __name__ == "__main__":
main()
到了这里,关于图解Vit 3:Vision Transformer——ViT模型全流程拆解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!