文章首发地址
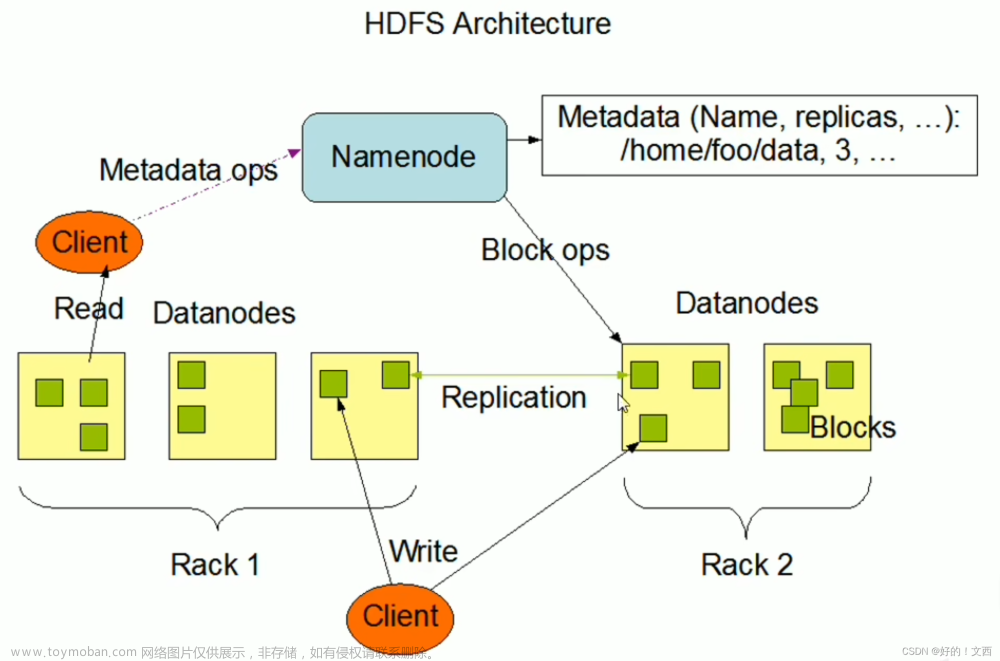
HDFS的数据存储
- HDFS的数据存储包括两块:
- 一块是HDFS内存存储
- 另一块是HDFS异构存储
HDFS内存存储是一种十分特殊的存储方式,将会对集群数据的读写带来不小的性能提升,而HDFS异构存储则能帮助我们更加合理地把数据存到应该存的地方。文章来源:https://www.toymoban.com/news/detail-579661.html
HDFS内存存储
- 异步存储的大体步骤可以归纳如下:
- 对目标文件目录设置StoragePolicy为LAZY_PERSIST的内存存储策略。
- 客户端进程向NameNode发起创建/写文件的请求。
- 客户端请求到具体的DataNode后DataNode会把这些数据块写入RAM内存中,同时启动异步线程服务将内存数据持久化写到磁盘上。
内存的异步持久化存储是内存存储与其他介质存储不同的地方。这也是LAZY_PERSIST名称的源由,数据不是马上落盘,而是懒惰的、延时地进行处理。文章来源地址https://www.toymoban.com/news/detail-579661.html
LAZY_PERSIST内存存储
- LAZY_PERSIST相关结构如下:
- FsDatasetImpl:FsDatasetImpl,它是一个管理DataNode所有磁盘读写的管家
- RamDiskReplica
- FsDatasetImpl:FsDatasetImpl,它是一个管理DataNode所有磁盘读写的管家
到了这里,关于HDFS的数据存储的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!