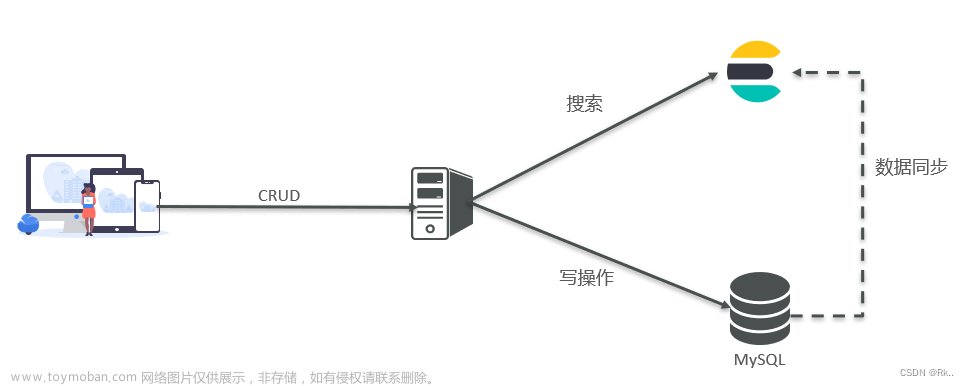
在SpringCloud系列(十五)[分布式搜索引擎篇] - 结合实际应用场景学习并使用 RestClient 客户端 API这篇文章中我们已经对 RestClient 有了初步的了解, 并且已经将一些数据进行了存储, 但是这并不是我们学习 ElasticSearch 的目的, ElasticSearch 最擅长的还是对数据的搜索及分析, 因此本篇博客将对 ElasticSearch 的数据搜索功能进行演示.
①DSL 对文档的查询
常见查询类型:
- 查询所有: 查询所有数据, 如 match_all;
- 全文检索查询(full text): 主要利用分词器对用户的输入内容进行分词, 然后去倒排索引库中进行匹配查询, 如 match_query / multi_match_query;
- 精确查询: 根据精确词条查询数据, 一般是用来查询日期 / 数值等类型的字段, 如 ids / range / term;
- 地理查询(geo): 通常根据经纬度进行查询, 如 geo_distance / geo_bounding_box;
- 复合查询(compound): 可以将上面的几种查询类型进行组合, 合并查询条件, 如 bool / function_score.
下面所有的查询语法基本如出一辙:
GET /索引库名/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
1.1 查询所有
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
因为是查询所有的数据, 所以没有查询条件, 查询类型为 match_all, 查询所有一般用不到, 使用场景也就仅限于测试的时候使用;
1.2 全文检索查询
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-1.png)
全文检索查询的使用场景比较多, 我们生活中也经常使用, 如在淘宝上买鞋子买衣服等, 都是搜索某一个牌子的名称或者是物品的名称, 也就是说需要拿着词条去索引库中匹配, 因此参与搜索的字段也必须是可分词的 text 类型的字段; 通过这个例子可以得到全文检索查询的基本流程如下:
- 对搜索的内容进行分词得到词条;
- 根据词条去倒排索引库中匹配, 得到文档 id;
-
根据文档 id 找到文档, 然后返回到页面中.
关于全文检索的查询主要包括 match / multi_match 两种, 一个是单字段查询, 一个是多字段查询, 多字段查询的意思就是任意一个字段符合条件就满足查询条件. 示例如下:
match:
GET /hotel/_search
{
"query": {
"match": {
"all":"喜来登"
}
}
}
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-2.png)
multi_match:
GET /hotel/_search
{
"query": {
"multi_match": {
"query":"上海喜来登",
"fields": ["name","business"]
}
}
}
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-3.png)
这里需要注意: multi_match 是根据多个字段进行查询, 参与的字段越多, 查询的效率就会越低, 因此一般使用 match 查询即可.
1.3 精准查询
精准查询的使用场景也是挺多的, 如查询某个日期范围内的数据, 或者是精确查询某一个地区的数据;
- term: 根据词条精确值进行查询, 如查询北京地区的喜来登酒店, 筛选出的数据就只有北京地区的喜来登;
-
range: 根据值得范围进行查询, 如查询 500 元以上的酒店数据.
term 查询:
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "上海"
}
}
}
}
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-4.png)
这里需要注意: 词条必须是精确的, 不能是多个词语组成的短语, 如果是北京上海, 是搜索不到结果的, 如下所示:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-5.png)
range 查询:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": "2000",
"lte":"5000"
}
}
}
}
查询到的是 2000 元到 5000 元价格酒店;![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-6.png)
1.4 地理坐标查询
出去游玩打车或者订酒店经常需要进行定位附近的快车及酒店, 地理坐标的查询就能实现这样的功能, 一种是根据地理坐标的经纬度进行查询, 如根据矩形范围进行查询:
GET /hotel/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
"lat": 31.35786,
"lon": 121.59324
},
"bottom_right": {
"lat": 31.35493,
"lon": 121.59838
}
}
}
}
}
这里首先要确定左上角的点的坐标及右下角的点的坐标, 比较复杂, 但是有一种简单的方式, 可以根据距离进行查询, 查询到指定中心点小于某个距离值的所有数据; 也就是说以我现在的位置为中心, 距离我某个距离的圆弧内都符合条件, 如下所示:
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": "39.94076,116.46099"
}
}
}
这里我查询的是以三里屯为中心点, 距离三里屯 5 km 所有的数据:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-7.png)
1.5 复合查询
复合查询可以将其简单的查询组合起来, 实现更加复杂的搜索逻辑, 主要有以下两种:
- function score: 算分函数查询, 通过控制文档相关性算分, 来控制文档的排名;
- bool query: 布尔查询, 主要利用逻辑关系组合多个查询, 实现复杂的搜索逻辑.
1.5.1 相关性算分
当我们使用 match 进行查询时, 文档结果会根据与搜索词条的关联度进行打分, 返回的结果也会按照分值的降序进行排序; ElasticSearch 早起使用的打分算法是 TF-IDF 算法, 关于算法的公式如下:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-8.png)
但是 TF-IDF 算法有一个缺陷: 当词条的频率越来越高的时候, 文档的得分也会越来越高, 单个词条对文档的影响较大. 针对这样的问题, ElasticSearch 将打分算法改进为 BM25, BM25 会让单个词条的算分有一个上限, 曲线更加的平滑.公式如下:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-9.png)
1.5.2 语法
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "北京"
}
},
"functions": [
{
"filter": {
"term": {
"id": "1"
}
},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-10.png)
如图所示, 可以看得出分数值是降序的, 具体的语法说明如下:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-11.png)
具体流程如下:
- 根据原始条件查询搜索文档, 并且计算相关性算分, 也就是 query score (原始算分);
- 根据过滤条件过滤掉不符合条件的文档;
- 基于算分函数运算得到函数得分 (function score);
- 将原始算分 (query score) 和 函数算分 (function score) 基于运算模式做运算, 得到相关性算分的最终结果.
例如: 给北京的喜来登排名靠前, 如下:
原始查询, 得分为 2.6944847;![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-12.png)
添加算分函数后, 得分为 4.6944847, 如下:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-13.png)
1.5.3 布尔查询
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-14.png)
布尔查询的使用场景还是挺多的, 如上图在淘宝上搜索 阿迪达斯, 我们可以进行选择筛选, 可以根据鞋码 / 性别等; 因为每一个字段都是不同的, 查询的条件或者方式也不一样, 因此肯定是多个不同的查询, 那么要组合这些查询就用到了布尔查询;
总之, 布尔查询也是一个或者多个字句的组合, 每一个字句都是一个子查询, 组合方式有:
- must: 必须匹配每个子查询, 类似 “与”;
- should: 选择性匹配子查询, 类似 “或”;
- must_not: 必须不匹配, 不参与算分, 类似 “非”;
- filter: 必须匹配, 不参与算分.
例子:文章来源:https://www.toymoban.com/news/detail-580205.html
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "北京"}}
],
"should": [
{"term": {"brand":"希尔顿"}},
{"term": {"brand":"喜来登"}}
],
"must_not": [
{"range": {"price": {"lte": 1200} }}
],
"filter": [
{"range": {
"score": {
"gte": 47
}
}},
{"geo_distance": {
"distance": "50km",
"location": {
"lat": 39.91979,
"lon": 116.41804
}
}}
]
}
}
}
代码解读:![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分),SpringCloud,微服务,spring cloud,分布式,搜索引擎](https://imgs.yssmx.com/Uploads/2023/07/580205-15.png)
这里需要注意的是: 搜索过程中, 参与打字的字段越多, 查询的性能就会越差劲, 因此多条件查询时, 需要注意以下两点:文章来源地址https://www.toymoban.com/news/detail-580205.html
- 搜索框的关键字搜索是全文检索查询, 使用 must 查询参与算分;
- 其他的过滤条件采用 filter 查询, 不参与算分.
② 搜索结果的处理
③ RestClient 查询文档
④ 案例
到了这里,关于SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!