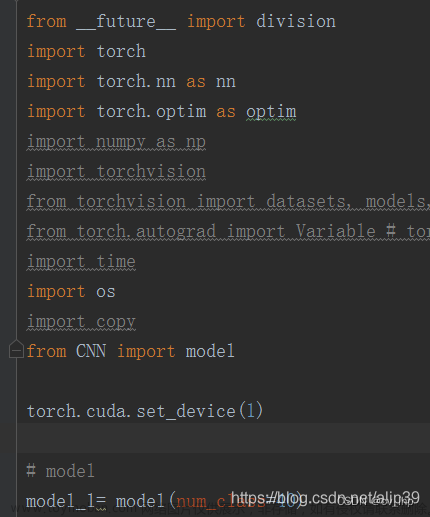
方法一 .cuda()
我们可以通过对网络模型,数据,损失函数这三种变量调用 .cuda() 来在GPU上进行训练。
# 将网络模型在gpu上训练
model = Model()
if torch.cuda.is_available():
model = model.cuda()
# 损失函数在gpu上训练
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 数据在gpu上训练
for data in dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
方法二 .to(device)
指定 训练的设备
device = torch.device("cpu") # 使用cpu训练
device = torch.device("cuda") # 使用gpu训练
device = torch.device("cuda:0") # 当电脑中有多张显卡时,使用第一张显卡
device = torch.device("cuda:1") # 当电脑中有多张显卡时,使用第二张显卡
#单卡推荐
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
使用 GPU 训练
model = model.to(device)
loss_fn = loss_fn.to(device)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
查看GPU使用情况
nvidia-smi.exe -l 5

文章来源地址https://www.toymoban.com/news/detail-580397.html文章来源:https://www.toymoban.com/news/detail-580397.html
到了这里,关于Pytorch调用GPU训练两种方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!