🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:python网络爬虫从基础到实战 欢迎订阅!后面的内容会越来越有意思~
💡往期推荐:
⭐️前面比较重要的基础内容:
【Python爬虫开发基础⑧】XPath库及其基本用法
【Python爬虫开发基础⑨】jsonpath和BeautifulSoup库概述及其对比
【Python爬虫开发基础⑩】selenium概述
【Python爬虫开发基础⑫】requests库概述(文件上传、cookies处理、状态码处理、异常处理等)
【Python爬虫开发基础⑬】Scrapy库概述(简介、安装与基本使用)
⭐️爬虫的实战文章:
【Python爬虫开发实战①】使用urllib以及XPath爬取可爱小猫图片
【Python爬虫开发实战②】使用urllib以及jsonpath爬取即将上映电影信息
大家可以复制代码感受一下爬虫的魅力~
💡本期内容:上一篇文章我们简单的介绍了Scrapy,这一篇文章我们接着来深入的讲一下它的架构:组织架构和工作原理
1 Scrapy的组件介绍
Scrapy 是一个用于爬取网站数据和执行抓取任务的Python框架。它提供了一系列的组件,用于构建和管理爬虫项目。下面是对 Scrapy的几个重要组件的介绍:

- Spider(爬虫)
Spider 是 Scrapy 的最基本组件,用于定义如何抓取特定网站的数据。每一个 Spider 都包含了一些用于抓取站点的初始URL和如何跟进页面中的链接的规则。Spider 通过解析页面的内容来抓取所需的数据。
- Item(数据项)
Item 用于定义要从网页中提取的结构化数据。你可以根据需要创建多个 Item,每个 Item 包含了一组字段,用于保存特定的数据。在 Spider 解析页面时,可以从页面中提取相关数据,并将其存储到 Item 中。
- Pipeline(管道)
Pipeline 可以定义对 Item 进行的数据处理操作。在 Spider 解析页面并提取数据后,可以将数据传递给 Pipeline,在 Pipeline 中执行数据清洗、验证、存储等操作。可以有多个 Pipeline,它们按照优先级顺序依次处理 Item。
- Project(项目)
Project 是指整个基于 Scrapy 的爬虫项目。它包含了所有的配置信息、Spider、Item、Pipeline、中间件等组件。一个项目可以包含多个 Spider,每个 Spider 负责爬取特定的网站或特定的数据。通过命令行工具或脚本,可以管理和运行项目,执行爬取任务。
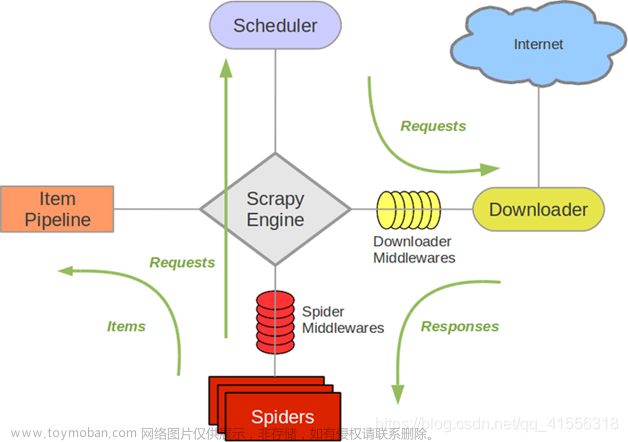
2 Scrapy架构组成
Scrapy 是一个基于异步网络框架 Twisted,采用了事件驱动的设计理念,具有高度的灵活性和可扩展性。下面是 Scrapy的详细架构组成:

- Spiders(爬虫)
Spider 是 Scrapy 框架中的主要组件,用于定义网站的抓取逻辑。每个 Spider 都包含了一些用于抓取站点的初始 URL 和如何跟进页面中的链接的规则。Spider 通过解析页面的内容来抓取所需的数据。
- Scheduler(调度器)
Scheduler 用于管理爬取任务的调度和队列,它接收由 Spider 生成的请求,并根据一定的策略进行排队。Scheduler 负责将请求发送给下载器进行处理,以确保爬虫能按照预定的顺序爬取数据。
- Downloader(下载器)
Downloader 负责下载请求的内容并将其返回给 Spider 进行解析。它可以处理使用 HTTP、HTTPS、FTP 等协议的请求,支持自动处理重定向、Cookies、代理等功能,并能够使用并发技术提高下载效率。
- Item Pipeline(数据管道)
Item Pipeline 是用于处理由 Spider 提取的 Item 对象的组件。它负责对 Item 进行处理、清洗、验证、存储等操作。可以有多个 Item Pipeline,它们按照优先级顺序依次处理 Item。
- Downloader Middleware(下载器中间件)
Downloader Middleware 是位于下载器和调度器之间的一层处理组件。它可以拦截下载请求和下载响应,对它们进行修改和处理。常见的应用场景包括设置请求的 Headers、处理代理、处理 Cookies 等。
- Spider Middleware(爬虫中间件)
Spider Middleware 是位于 Spider 和调度器之间的一层处理组件。它可以拦截 Spider 的输入和输出,对它们进行修改和处理。常见的应用场景包括处理抓取结果、处理异常、处理重定向等。
- Item Loader(数据加载器)
Item Loader 是用于填充 Item 对象的组件。它负责从爬取的数据中解析出字段的值,并进行预处理、格式化等操作。可以通过定义 Item Loader 来指定每个字段的处理规则。
- Engine(引擎)
Engine 是 Scrapy 的核心调度器,负责控制整个爬取流程的运行。它通过调度器、下载器、Spider 等组件的协同工作,实现了请求的调度和处理、页面的解析和数据的提取等功能。
- Spider Loader(爬虫加载器)
Spider Loader 负责加载和实例化 Spider,以及管理 Spider 的配置和设置。它可以根据配置文件或命令行参数自动发现和加载项目中的 Spider。
3 Scrapy工作原理

Scrapy的工作原理如下:
- 引擎(Engine)从 Spider 获取要抓取的初始 URL,并向调度器(Scheduler)提交请求。
- 调度器根据一定的策略将请求入队,等待下载器(Downloader)进行处理。
- 下载器从调度器获取请求,并将其发送到指定的网站服务器,获取响应。
- 下载器将响应返回给引擎,引擎将其传递给 Spider 进行解析和处理。
- Spider 解析网页,提取所需的数据,并生成新的请求,以及要存储的数据项(Item),并将它们返回给引擎。
- 引擎将新生成的请求交给调度器处理,将存储的数据项传递给 Item Pipeline 进行处理。
- 在 Item Pipeline 中,对数据项进行各种处理操作,如数据清洗、验证、存储等。
- 经过 Item Pipeline 处理后,最终的数据项被存储起来,或者根据配置将其发送到其他目标。
- 如果有新的请求生成,引擎将重复以上步骤,直到调度器中没有更多的请求。
Scrapy 的工作原理是基于异步的事件驱动模型实现的。整个过程中各个组件的协同工作使得爬取任务得以高效地进行。在处理请求和响应过程中,Scrapy 支持并发处理,通过使用异步网络框架 Twisted,从而提高了爬虫的速度和效率。此外,Scrapy 还提供了许多可定制和扩展的机制,如中间件、数据管道等,使得开发者能够根据自己的需求进行灵活的配置和操作。文章来源:https://www.toymoban.com/news/detail-580855.html
总结来说,Scrapy 的工作原理是:引擎从 Spider 获取初始 URL,通过调度器将请求入队,下载器发送请求获取响应,Spider 解析网页提取数据并生成新的请求和数据项,引擎将其传递给相应组件进行处理,最终实现数据的提取、处理和存储。这个循环过程不断重复,直到所有的请求都被处理完毕或达到停止条件。文章来源地址https://www.toymoban.com/news/detail-580855.html
到了这里,关于【Python爬虫开发基础⑭】Scrapy架构(组件介绍、架构组成和工作原理)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!