参考文献:chatglm2ptuning
注意问题1:AttributeError: ‘Seq2SeqTrainer’ object has no attribute 'is_deepspeed_enabl
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
可能是版本太高,可以参考chatglm2的环境
1. ChatGLM2-6B的P-Tuning微调
ChatGLM2-6B:https://github.com/THUDM/ChatGLM2-6B
模型地址:https://huggingface.co/THUDM/chatglm2-6b
详细步骤同:ChatGLM-6B的P-Tuning微调详细步骤及结果验证
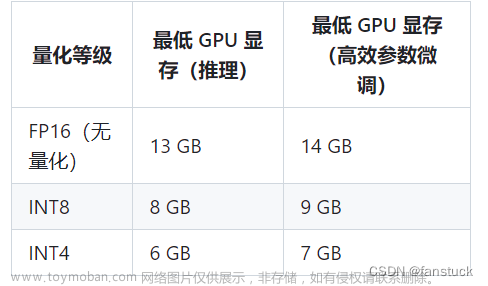
注:ChatGLM2-6B官网给的环境P-Tuning微调报错 (python3.8.10/3.10.6 + torch 2.0.1 + transformers 4.30.2),
AttributeError: ‘Seq2SeqTrainer’ object has no attribute 'is_deepspeed_enabl
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:

应该是transformers版本太高了,用ChatGLM-6B环境(ChatGLM-6B部署教程)即可,即
Python 3.8.10
CUDA Version: 12.0
torch 2.0.1
transformers 4.27.1
- 1
- 2
- 3
- 4
2. 模型微调情况
2.1 数据集&调参
训练集:412条
验证集:83条
max_source_length:3500
max_target_length:180
问题长度:
 文章来源:https://www.toymoban.com/news/detail-582777.html
文章来源:https://www.toymoban.com/news/detail-582777.html
2.2 模型训练
A100 80G 2块,占用率16%,3000轮训练时间21h


 文章来源地址https://www.toymoban.com/news/detail-582777.html
文章来源地址https://www.toymoban.com/news/detail-582777.html
2.3 模型预测
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
import os
tokenizer = AutoTokenizer.from_pretrained(“…/THUDM-model”, trust_remote_code=True)
CHECKPOINT_PATH = ‘./output/adgen-chatglm2-6b-pt-64-2e-2/checkpoint-3000’
PRE_SEQ_LEN = 64
config = AutoConfig.from_pretrained(“…/THUDM-model”, trust_remote_code=True, pre_seq_len=PRE_SEQ_LEN)
model = AutoModel.from_pretrained(“…/THUDM-model”, config=config, trust_remote_code=True).half().cuda()
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, “pytorch_model.bin”))
new_prefix_state_dict = {
}
for k, v in prefix_state_dict.items():
if k.startswith(“transformer.prefix_encoder.”):
new_prefix_state_dict[k[len(“transformer.prefix_encoder.”):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
#model = AutoModel.from_pretrained(CHECKPOINT_PATH, trust_remote_code=True)
model = model.eval()
response, history = model.chat(tokenizer, “你好”, history=[]
参照p-tuning readme,需注意:
(1) 注意可能需要将 pre_seq_len 改成训练时的实际值。
(2) 如果是从本地加载模型的话,需要将 THUDM/chatglm2-6b 改成本地的模型路径(注意不是checkpoint路径); CHECKPOINT_PATH路径需要修改。
(3) 报错”RuntimeError: “addmm_impl_cpu_” not implemented for ‘Half’“
需要在model = AutoModel.from_pretrained(“…/THUDM-model”, config=config, trust_remote_code=True) 后加 .half().cuda()
495条数据,无history,单轮,模型加载+预测时间3min
1. ChatGLM2-6B的P-Tuning微调
ChatGLM2-6B:https://github.com/THUDM/ChatGLM2-6B
模型地址:https://huggingface.co/THUDM/chatglm2-6b
详细步骤同:ChatGLM-6B的P-Tuning微调详细步骤及结果验证
注:ChatGLM2-6B官网给的环境P-Tuning微调报错 (python3.8.10/3.10.6 + torch 2.0.1 + transformers 4.30.2),
AttributeError: ‘Seq2SeqTrainer’ object has no attribute 'is_deepspeed_enabl
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
应该是transformers版本太高了,用ChatGLM-6B环境(ChatGLM-6B部署教程)即可,即
Python 3.8.10
CUDA Version: 12.0
torch 2.0.1
transformers 4.27.1
- 1
- 2
- 3
- 4
2. 模型微调情况
2.1 数据集&调参
训练集:412条
验证集:83条
max_source_length:3500
max_target_length:180
问题长度:
2.2 模型训练
A100 80G 2块,占用率16%,3000轮训练时间21h
2.3 模型预测
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
import os
到了这里,关于手把手带你实现ChatGLM2-6B的P-Tuning微调的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!