一、准备工作-服务器
1、先准备一个服务器(以阿里云为例子)
-
1、先准备一个云服务器,比如阿里云服务器新人免费使用3个月 , 或者腾讯云服务器,又或者华为云服务器都可以,
但是提醒注意下,新用户的首单资格优惠力度最大,所以最好在一年有活动的时候买,比如618或者双十一,当然免费的话最好月初的时候开始试用
-
2、注意注意:可能我是不熟悉,走了一个坑,如果你在一个月的月底开始试用3个月的话,那么那一个月就算用掉了,所以建议在月初的时候开始试用,薅羊毛获得最大时长;因为比如我就是5月22号试用的,到7月31号就到期了,这时候其实已经少试用了20多天了~~ ;
所以记得问下客服,如果现在开始试用,云服务器到期的具体时间点
-
3、购买服务器后,登录到这里,然后重置密码,然后强制重启


-
4、快捷跳到后台-跳到这个控制台也可以选择对应产品跳到过来

-
可能这个时候大多数小白和我一样没啥概念,反正就先有个认识,这三种服务器的类型分类如下,而我们
免费3个月的是云服务器ECS,所以点击这个进到对应后台
-
又比如腾讯云服务器,这里也有三种分类服务器,比如我第一次使用的是
轻量应用服务器,所以点这个进到对应后台,没啥概念的小白的我,反正就先这样~
-
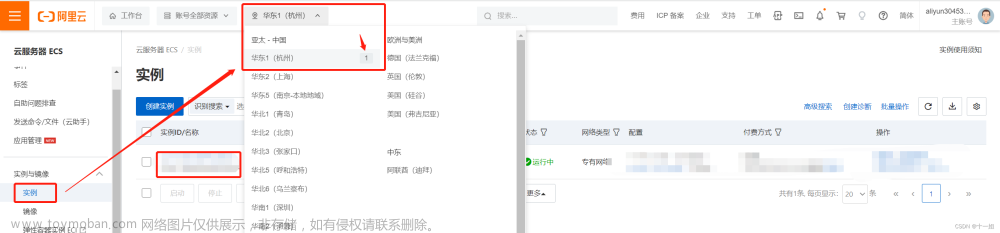
5、点击实例,如果没有显示你拥有的服务器,则地址位置看下是哪个区域,然后进行选择下
2、开通服务端口号访问权限
- 1、开通可以访问的端口号,只有开通了端口号,才能正常连接;在
安全组-管理规则-手动添加对应端口,和授权对象ip; 这里的意思是比如你要在服务器上启动一个服务比如http:0.0.0.1:4000/test , 想要别人能通过你的服务器外网ip访问到的话,你就得把端口权限打开
2、如下开端口、到https://www.ip138.com/可以看到你的IP
- 手动添加规则,注意指定的端口,和授权可以访问的ip即可,然后保存

- 那腾讯云轻量应用服务器也是在添加规则的位置,设定端口和授权ip


二、准备工作-Xshell登录服务器
-
1、Xshell/Xftp下载地址 ,简言之,
Xshell负责环境代码部署,Xftp负责文件或代码的同步与传输,搭配使用更方便
-
2、下载安装好后,如下,Xftp和Xshell的区别:我们在Xftp上的操作,在Xshell同样可以,只是Xftp通过可视化界面和点击、拖拽等方式可以实现文件上传/下载/删除/重命名/移动等,而Xshell则需要通过敲击命令的方式来实现;简言之,
Xshell负责环境部署,Xftp负责文件或代码的同步与传输
1、xshell基本登录操作
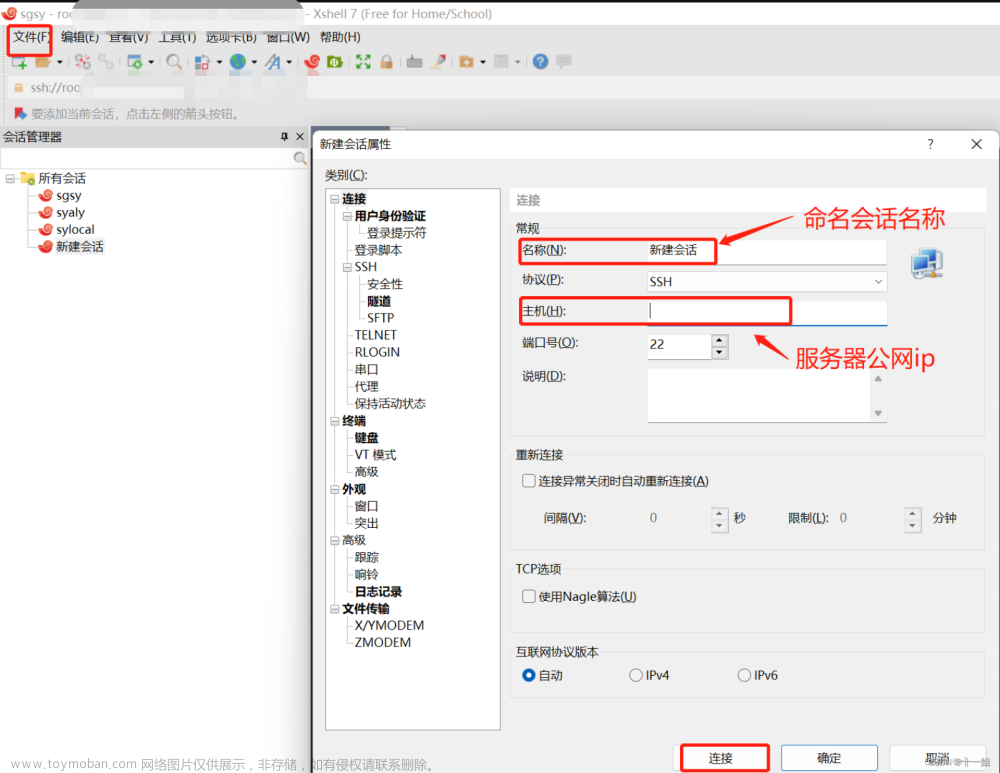
- 1、双击打开xshell,登录linux系统等服务器操作的软件,文件>新建会话>如下连接对应服务器>按提示即可连上

- 2、登录上xshell服务器后,试着输入python3,可以发现服务器自带python3,ctrl+d退出python;接着你可以cd /opt 目录下,去下载一些常用的解压安装部署

- 3、比如在linux服务器上安装node环境
cd /opt wget https://nodejs.org/dist/v16.15.0/node-v16.15.0-linux-x64.tar.xz tar -vxf node-v16.15.0-linux-x64.tar.xz mv node-v16.15.0-linux-x64 nodejs
2、xftp基本操作
- 1、Xftp是一个用于Windows系统平台上的FTP、STFP协议
文件传输程序,它能帮助用户安全地在Unix系统和Windows系统上进行快速的文件传输任务,并且它可对文件列表进行可视化展示,更符合Windows用户的使用习惯
- 2、双击打开后,依然是新建会话连上服务器
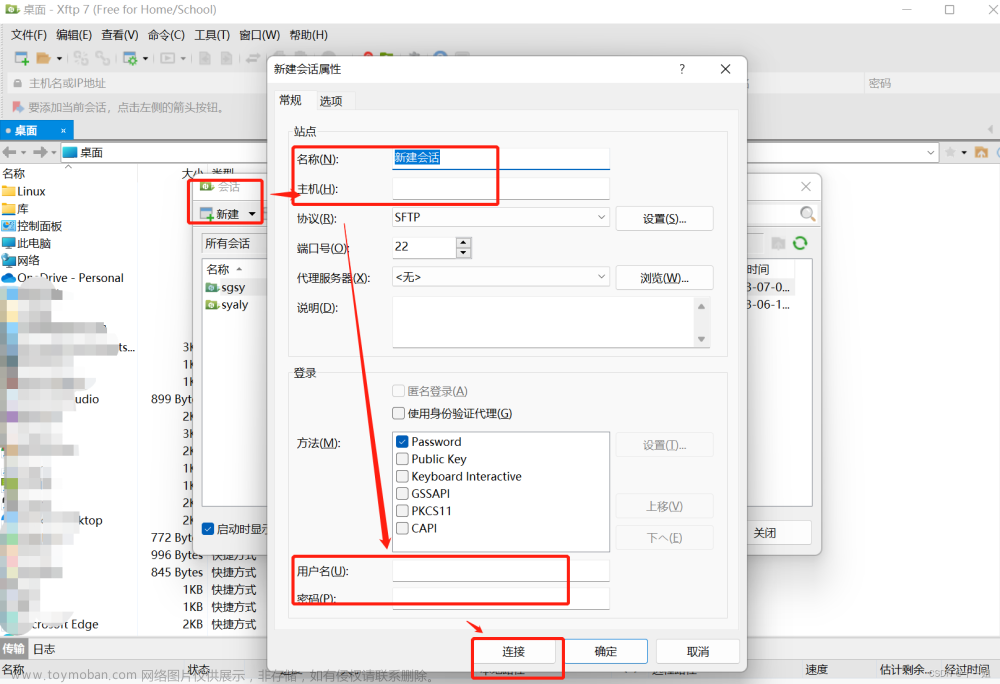
- 3、连上登录好后,就可以实现windows系统和服务器Unix系统的文件传输了,只需要选中指定文件进行拖拽即可

三、部署代码到服务器上
- 1、当然可以通过git的方式部署同步 ,如果你觉得xftp的方法麻烦的话,就用这个git的方法同步更新,
git不熟悉的话,部署还需要麻烦些,可以加vsjyjy 备注:CSDN交流群 - 2、但今天就简单介绍下临时几个文件的部署,以及常用命令等,所以就用xftp同步上线传文件即可,
小白第一次x学习使用推荐这种方式吧 - 3、当然还有其它方式部署爬虫,比如Scrapy等
1、部署一个python爬虫脚本在服务器上定时运行等
-
1、样例代码代码https://github.com/Shirmay1/MoreMoreLearn , 文章所有代码开源在git上,
csdn下载资源如果显示收费请到git上开源下
-
2、先在xsheel上命令创建一个目录data,专门用来存代码
cd / mkdir data -
3、打开xftp,上传代码到服务器/data目录下

-
4、然后在xshell界面操作cd /data目录下,ls查看当前目录下的文件,然后python3运行目标python文件,如下正常运行

-
5、如果我们要让他一直持续运行到后台,并且定时启动呢,
nohup python3 crawl_news.py >/dev/null 2>&1 &,开个定时脚本,并logger.add('crawl_news.log', encoding='utf-8')可以存储日志文件,loguru日志库学习logger.add('crawl_news.log', encoding='utf-8') scheduler = BlockingScheduler(timezone='Asia/Shanghai') scheduler.add_job(list_main, 'cron', hour=2, minute=30, args=(), max_instances=100, misfire_grace_time=360) scheduler.start() -
6、如图,就成功部署好一个python爬虫脚本了,通过scheduler每天定时启动,
ps -ef | grep crawl_news搜索包含crawl_news的后台进程,如图进程号3562
2、部署一个python服务接口他人调用访问等
- 1、样例代码 ,本地直接运行打开http://127.0.0.1:8444/get_ip , 服务器上运行,则把对应的
127.0.0.1改成对应的外网地址# -*- coding: utf-8 -*- # @Time : 2023/7/2 # @Author: sy # @公众号: 逆向OneByOne # @desc: 部署python flask的接口调用测试; vsjyjy 注:CSDN交流 from flask import Flask, request from loguru import logger logger.add('flask_api.log', encoding='utf-8') app = Flask(__name__) @app.route("/get_ip", methods=['get']) def get_ip(): ip = request.remote_addr logger.info(f"ip is {ip}") return f"your ip is {ip}" if __name__ == '__main__': app.run(host="0.0.0.0", port=8444, debug=True) - 2、xftp拖文件到对应服务器上

- 3、将文件部署到服务器上,然后后台持续运行,
nohup python3 flask_api.py >/dev/null 2>&1 &
- 4、然后如下,打开服务器公网的接口如下访问,此时已经返回正常数据,说明部署成功 ; 如果你的访问不起来的话,可能你服务器安全组-规则端口没有打开权限

3、部署一个js服务接口他人调用访问等
-
1、代码https://github.com/Shirmay1/MoreMoreLearn,express用法 , 先启动express的js服务,然后python尝试调用
# -*- coding: utf-8 -*- # @Time : 2023/7/2 # @Author: sy # @公众号: 逆向OneByOne # @desc: express接口调用案例 import requests from loguru import logger logger.add('express_api.log', encoding='utf-8') lat_lng = { "lng": 120.5811424828, "lat": 31.3010678543, "Se": "inner", "num": 12 } url = f"http://127.0.0.1:8444/lj_enc" resp = requests.post(url, data=lat_lng, timeout=10) logger.success(f"req_response {resp.text}")
-
2、xftp上传部署文件

-
3、启动服务,我们在xshell上面,先node express_api.js看看有没有报错,测试下报错的话安装相关模块,
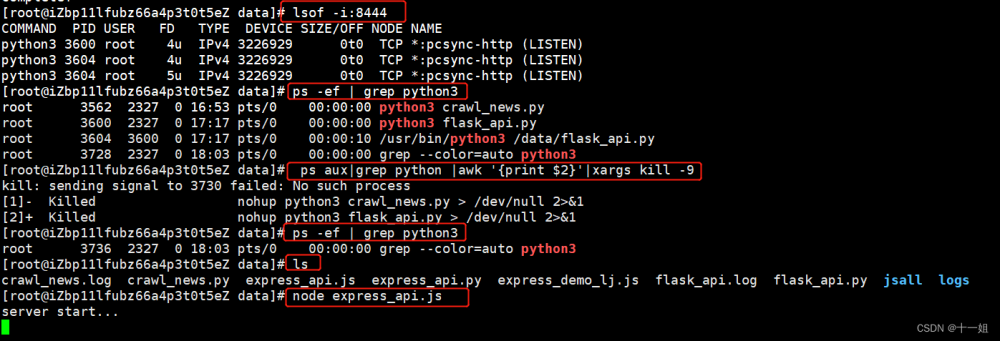
-
4、打开测试下,服务器正常打印日志,然后python脚本运行下,正常返回数据,说明没接口调通,如果失败,看下服务器端口权限是否打开


-
5、正式部署,用PM2部署js ,
pm2 start express_api.js --max-memory-restart200M(使用 --max-memory-restart 选项指定内存阈值) pm2

4、启动一个企业微信群告警的方式
- 1、企业微信建一个群聊,然后添加一个群机器人
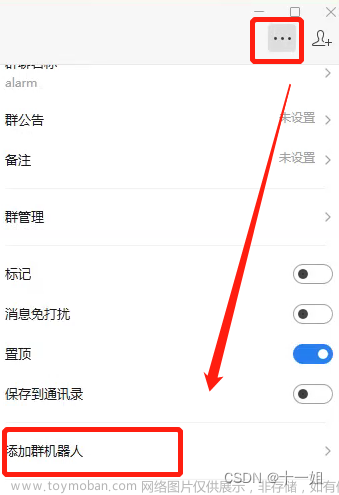
- 2、代码https://github.com/Shirmay1/MoreMoreLearn

5、通过git的方式部署
- 1、GitHub/Gitee/Gitlab平台:都可以,选择一个注册账号即可,平常写的代码是在
工作区,通过git add命令是到暂存区, 通过git commit命令是到本地仓库,通过git push是到线上远程仓库


-
2、安装下载与用户名密码配置, git安装下载

-
3、本地点击git bash后输入以下命令,配置用户名/密码,红色部分换成自己对应的
- 显示当前的配置:git config --list
- 设置用户名: git config --global user.name
Shirmay - 设置用户名邮箱: git config --global user.email
Shirmay@qqqqq.com - 系统用户级别设置:git config --global
-
4、在你刚刚新建的远程仓库,克隆线上远程仓库, 建议通过ssh的连接方式登录,参考该文档目录十二ssh登录配置操作 , 按文档将sshkey复制到线上配置即完成第一步

-
5、本地新建一个空文件夹,记得github先建一个仓库,然后点击code这里复制ssh命令,然后打开git bash窗口输入命令:
git clone git@github.com:Shirmay1/MoreMoreLearn.git,即可完成远程仓库克隆到本地的操作

-
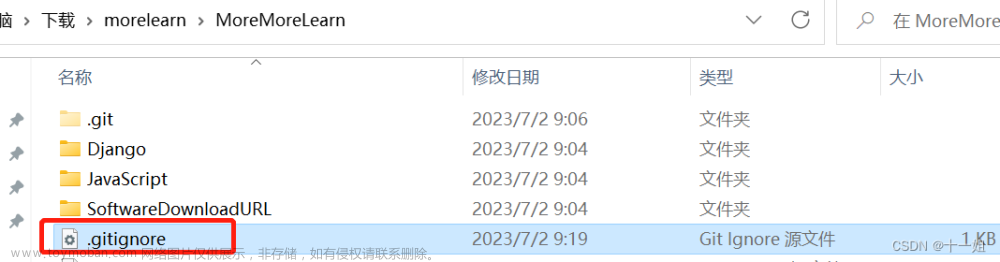
6、git忽略 pycache 和 .pyc文件
-
在文件目录下新建.gitignore文件, 文件内容添加**/pycache,这样可以把文件夹中的__pycache__文件夹忽略,并且子文件夹中的__pycache__也一并忽略

-
如果意外的已经通过git上传了那些文件的话,可以本地使用命令删除
rm -rf 文件 git rm --cached 文件
-
-
7、常用命令
- git status:查看本地工作区与本地仓库代码的差别
- git diff 文件名: 比较本地与线上仓库代码差异点
- git restore 文件名: 将本地文件还原成本地仓库的文件
- git add 文件名:将本地文件上传到暂存区,git add xx命令可以将xx文件添加到暂存区,如果有很多改动可以通过 git add -A .来一次添加所有改变的文件。注意 -A 选项后面还有一个句点。 git add -A表示添加所有内容, git add . 表示添加新文件和编辑过的文件不包括删除的文件; git add -u 表示添加编辑或者删除的文件,不包括新添加的文件
- git commit -m ‘说明’:将暂存区代码提交到本地仓库
- git push -u origin:将本地仓库提交到线上仓库
- git remote -v:查看本地分支情况
- git reset --hard: 回退到上一个版本
- git pull origin master:从线上仓库拉取最新代码
- git push origin master:将本地仓库的代码推到线上
- 如下是本地常用的操作命令步骤,一般先git pull origin master , 然后再git push
四、常用操作命令
1、linux常用命令:
- pwd:查看当前目录
- ls : 查看目录下的文件 , 或者 ll 或者 la
- ps -ef | grep .js : 搜索包含.js的进程
- ps -ef | grep python : 搜索包含python的进程
- ps aux|grep python |awk ‘{print $2}’|xargs kill -9 : 杀掉包含python的进程
- nohup python epub_add.py >/dev/null 2>&1 & : 后台启python文件进程
- mv: 移动文件/文件重命名
- mkdir : 创建一个目录,-p用户创建多层目录
- rm -rf:强制删除文件夹
- df -h :查看磁盘空间
- free -h : 查看内存使用
- lsof -i:1110 查看1110端口占用 (yum install lsof -y)
2、windows常用命令
- wmic process where name=“python.exe” list brief : 查看使用python的进程
- netstat -ano |findstr “9110” : 看到端口占用
- taskkill -f /pid 110108 : 杀掉进程
3、node常用命令
-
直接启动运行js : node app2.js
-
pm2需要全局安装npm install -g pm2 , pm2
-
启动进程/应用 pm2 start app2.js
-
重新启动进程/应用 pm2 restart app2
-
重新启动所有进程/应用 pm2 restart all
-
列出所有进程/应用 pm2 list
-
查看某个进程/应用具体情况 pm2 describe app2
-
结束进程/应用 pm2 stop app2
-
结束所有进程/应用 pm2 stop all
-
删除进程/应用 pm2 delete app2
-
删除所有进程/应用 pm2 delete all
-
查看pm2的日志 pm2 logs
-
查看某个进程/应用的日志,使用 pm2 logs www
-
查看进程/应用的资源消耗情况 pm2 monit文章来源:https://www.toymoban.com/news/detail-583799.html
-
重命名进程/应用 pm2 start app2.js --name aaa文章来源地址https://www.toymoban.com/news/detail-583799.html
到了这里,关于爬虫小白入门在服务器上-部署爬虫或者开服务接口并供给他人访问的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!