伪分布模式的特点
- 在单机上,模拟一个分布式的环境
- 具备Hadoop的所有的功能
- 用于开发和测试
-
HDFS:NameNode、DataNode、SecondaryNameNode -
Yarn:ResourceManager、NodeManager
部署伪分布模式
前提:部署好hadoop的本地模式
点击设置hadoop的本地模式
伪分布模式的部署主要是将下面的参数文件的配置参数进行更改。
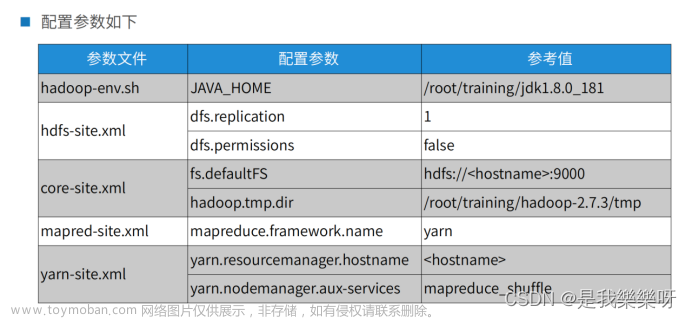
hadoop-env.sh
注:如果在本地模式已经配置完成,这个文件则不需要重复配置。
路径:/root/training/hadoop-2.7.3/etc/hadoop($HADOOP_HOME/etc/hadoop)
更改第25行 export JAVA_HOME=/root/training/jdk1.8.0_181
hdfs-site.xml
进入 /root/training/hadoop-2.7.3/etc/hadoop/ 路径找到 hdfs-site.xml 文件进行编辑。
vi hdfs-site.xml
将下面xml代码添加该文件
<!--数据块的冗余度,默认是3-->
<!--一般来说,数据块冗余度跟数据节点的个数一致,最大不超过3-->
<!--由于这是伪分布模式,所以这里冗余度设置为1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
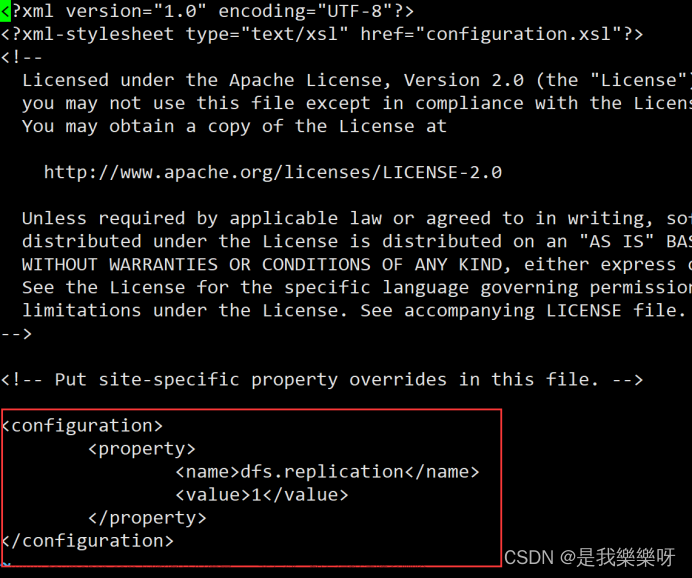
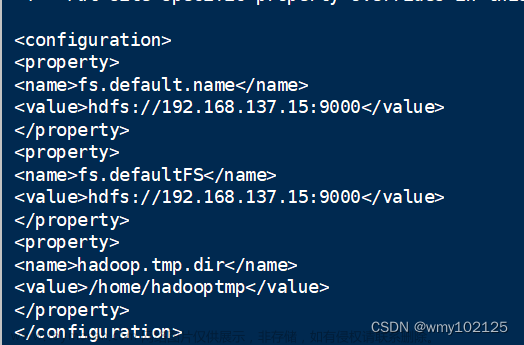
core-site.xml
需要在hadoop目录下,先创建出tmp文件,作为HDFS对应的操作系统目录。
mkdir /root/training/hadoop-2.7.3/tmp
编辑操作与上面文件相同,则不演示。
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
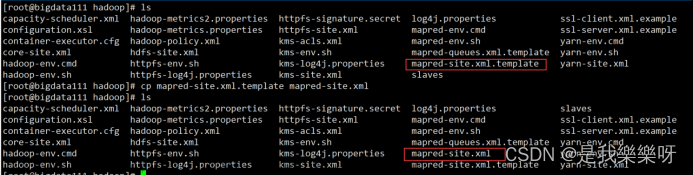
mapred-site.xml
这个文件默认没有,需要我们先复制
cp mapred-site.xml.template mapred-site.xml
<!--配置MapReduce运行的框架是Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
对NameNode进行格式化
执行下面这条命名
hdfs namenode -format
成功则出现下面这句话。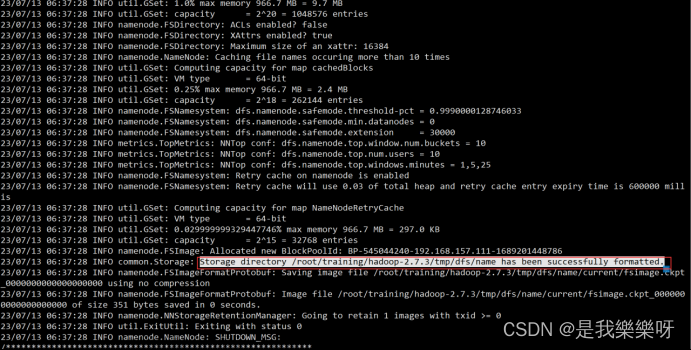
启动Hadoop
start-all.sh
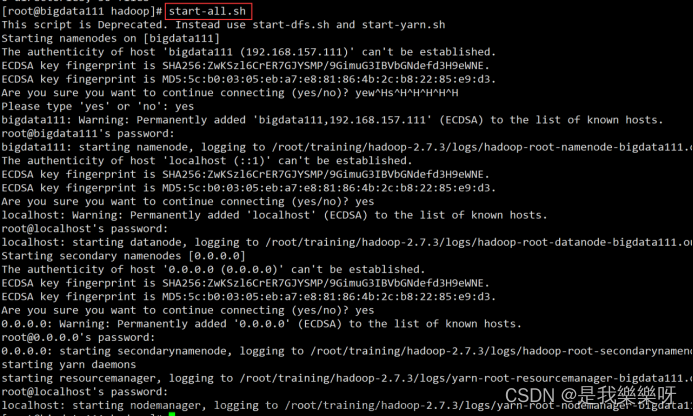
需要输入4次密码和yes。
至此部署完成,下面进行测试!
对部署是否完成进行测试
将本地文件上传到hdfs
进入/root/training/hadoop-2.7.3/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output/wc

停止集群
stop-all.sh
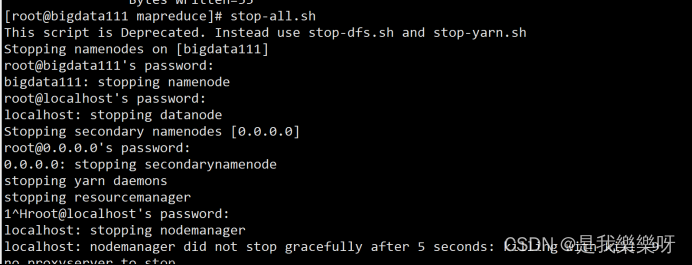
也需要输入4次密码,输入密码太麻烦,所以我们还需要配置免密码模式。
免密码模式
免密码模式的原理(重要)
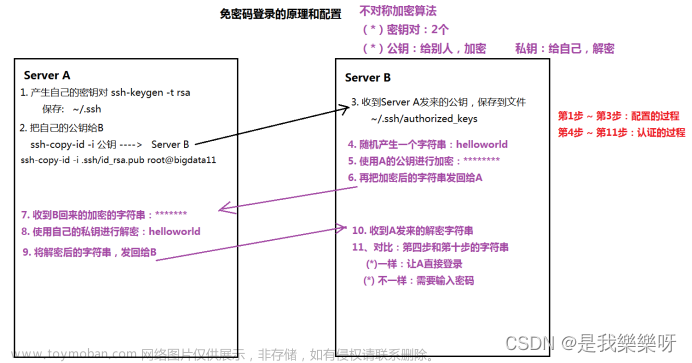
免密码模式的配置
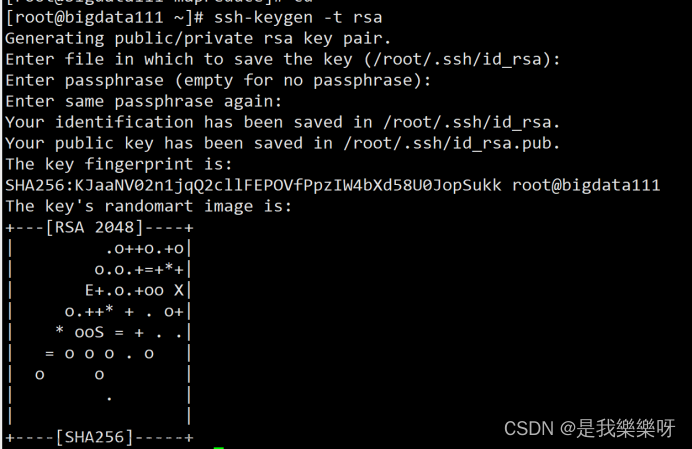
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
注:root@bigdata111 是你当前的主机名

 文章来源:https://www.toymoban.com/news/detail-583867.html
文章来源:https://www.toymoban.com/news/detail-583867.html
免密码模式配置完成!文章来源地址https://www.toymoban.com/news/detail-583867.html
到了这里,关于【hadoop】部署hadoop的伪分布模式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!