一、前言
在大多数资料中,神经网络都被描述成某种正向传播的矩阵乘法。而本篇博文通过将神经网络描述为某种计算单元,以一种更加简单易懂的方式介绍神经网络的功能及应用。
二、神经网络的架构——以手写数字识别
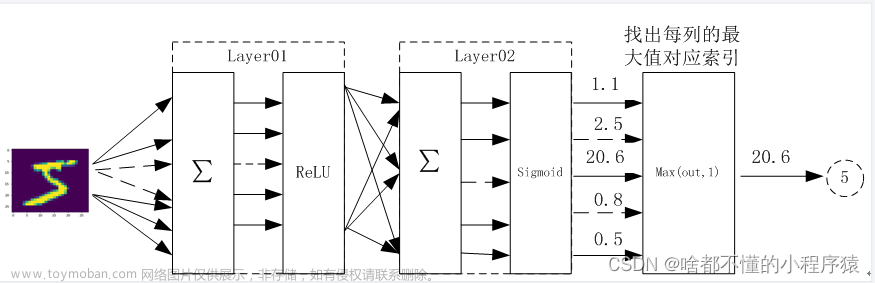
广义上讲,神经网络就是要在输入数据中找寻某种规律,就像这个经典的例子:手写数字识别。即给定一个手写数字图像,如何识别图像中的是数字几呢?神经网络通过对大量带标签图像的训练,找到其中的规律,进而解决手写数字识别问题。
我们将手写数字图像的像素值作为神经网络的输入,然后通过隐藏层处理,最终输出层有10个对应类别。我们选取输出层中最大值的神经元作为最终的识别结果。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-1.png)
有了这些信息,神经网络就能够对从未见过的图像进行分类,这是它的用处所在。也就是说,我们不仅能够用神经网络对函数进行建模,还可以用其对数据进行分类。
神经网络是一种分层结构,它有输入层、隐藏层和输出层,其每一层都有许多神经元组成。此例中,输入层是由图像的像素值组成(28*28=784)。由于每个数字只有10种可能,所以输出层将有10个神经元用来表示识别到的数字。隐藏层的层级以及其神经元的个数都要通过反复试验来确定。
三、神经网络的工作
1、单输入单输出感知器函数
神经网络到底是如何工作的呢?让我们从最简单的单输入单输出网络开始讲起。假设这个神经网络是用来将天气分为好坏两种类型:假定输出为1时表示好天气,0表示坏天气,这种输出二值型的神经网络也叫感知器。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-2.png)
可以把感知器想象成一个开关,如果打开它,就输出1,否则输出0。假设温度高于20℃时,为好天气。该例的输入空间就是一维的,就像一条数轴,决策边界就是在20℃处画一条线,任何大于或等于20℃的输入都将激活感知器。而对于低于20℃的输入,感知器都出于未激活状态。
实际上,当我们训练一个神经网络时,我们所作的就是确定这些边界的位置。让我们讨论一下,为什么其输出可以表示成y=H(x-20)这种形式。其中H代表跃迁函数,当x≥0时,其输出为1;当x≤0时,其输出为0.即:正1负0。而H(x-20)则表示,当x-20≥0时,其输出为1;当x-20<0时,其输出为0。如果我们假设超过20℃为坏天气,则相应的式子变为y=H(-x+20)即可。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-3.png)
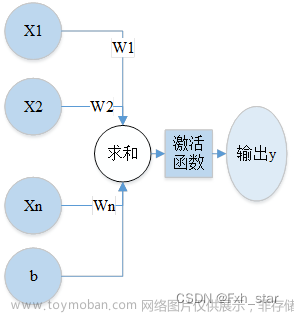
通常,我们可以将单输入单输出的感知器函数写作y=H(wx+b)。
2、二维输入参数
如果我们在例子中再添加一个输入,也就是说确定天气是否糟糕要看温度和湿度两个指标。这时相当于给输入空间增加了一个维度,即输入空间变为二维的了。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-4.png)
即当我们假定当温度或湿度值较大时,则为坏天气,反之为好天气。我们可以再输入空间划上一条直线,在其上方的点输出1,其下方点输出0。此时输出函数则可以写成y=H(w1x1+w2x2+b),此时的决策边界可以看做是一个平面,其与输入平面相交形成一条分界线。
我们也可以将上式写作矩阵相乘的形式:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-5.png)
我们可以用W来代替矩阵,用x代替向量。从专业的角度讲,W为权重矩阵,b为偏置:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-6.png)
3、三维输入参数
三维的情况也能够描述,比如我们再考虑风速的影像。现在输入就是三维的了,所以决策边界可以用一个超平面来表示。此时的输入矩阵是3*1的,式子的输出任然是0或1。
一般来说,神经元的输入x是一个多维向量,然后将其乘以一个权重矩阵,然后加上偏置,再传给激活函数,最终得到神经元的输出。此例中,激活函数使用的是跃迁函数。
四、激活函数
1、激活函数
让我们再看看其他激活函数。有时候,连续输出会比这种二值输出函数更有用。也就是说,比如传递给激活函数的值是0.0001,虽然它非常接近0,但跃迁函数还是输出1。我们可以用这种函数来产生连续的输出:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-7.png)
我们可以将该激活函数的输出看作频率。如果该激活函数的输出为0.5,那么我们可以预测该事件发生的概论为50%。我们之所以能将其看作概率,是因为该激活函数的输出值在0到1之间。
2、ReLU激活函数
另一个常用的激活函数是ReLU。ReLU有两部分,输入为负,输出为0;输入为正,输出为输入本身,即max(0,x)。ReLU常用于神经网络的隐藏层中。需要注意的是:这些函数都不是线性的,这点非常重要。
至此,我们有了一个可以用来划分数据的模型。如果我们的数据集变得越发复杂时,该怎么办呢?![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-8.png)
3、非线性激活函数
以这个数据集为例子,我们希望创建一个模型,在给定x和y坐标的情况下来预测该点的颜色。我们可以用一个两个输入的感知器来完成,其决策边界如上方的黄线所示,我们称这种类型的数据集是线性可分的。
但如果我们的数据集变成这种样子,此时就不能用一条线性函数来作划分了。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-9.png)
我们可以组合多个神经元,利用其激活函数的非线性就能构造出非常复杂的决策边界。为了理解神经网络是如何工作的,让我们来看一个两输入两输出的神经网络:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-10.png)
(1)二输入二输出的神经网络的架构
首先来看第一个输出神经元,其输出为:y=σ(w11x1+w12x2+b),其中激活函数选择sigma。权重的第一个下标表示该神经元在本层的序号,第二个下标为其输入在上一层的序号。类似的,我们可以写出第二个输出神经元的输出表达式。有没有办法将这两个方程合二为一呢?
(2)方程矢量化
首先,我们可以对方程进行矢量化,将输入输出都写成向量形式。此时我们再将系数转换为矩阵形式,即权重矩阵。这样我们就能将其推广到任意数量的输入、输出神经元中了。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-11.png)
(3)设置不同的权重矩阵和偏置因子
此外,我们可以对每一层都使用相同的方程,差别仅仅是各层的权重矩阵和偏置因子不同。现在让我们在这两者之间加一个隐藏层,该层的输入输出关系如上所示。 ![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-12.png)
(4)其他矩阵变换
注意:隐藏层使用的激活函数是ReLU,也可以使用其他的激活函数,比如sigmoid。接下来就是输出层的关系表达式了,矩阵与向量相乘,其实质就是线性变换。现在,让我们先忽略激活函数,只考虑Wx+b的结果。如何理解线性变换呢?我们可以将矩阵的第一列看成线性变换后的单位向量i,矩阵的第二列为线性变换后的单位向量j。在线性变换中,我们只允许进行旋转、缩放、翻转等操作,即线性变换后坐标原点保持不变。文章来源:https://www.toymoban.com/news/detail-584734.html
4、线性激活函数和非线性激活函数
回到神经网络,假设该神经网络权值和偏置已经进行随机初始化了。首先让我们从输入数据集开始,本例中,它是一个正方形中均匀分布的一组点:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-13.png)
第一个操作时乘以权重矩阵,这是一个线性变换(旋转、缩放、翻转等操作的组合)。接下来加上权重因子,可以将其理解为平面内的移动。
现在我们来看激活函数,这里我们使用的是ReLU作为激活函数,也就是说,任何负的输出都是0,只留下正的部分。显然,第一象限是唯一一个符合要求的象限,ReLU会将其他象限的值映射到第一象限上,其结果就剩下第一象限这一块了。注意:若采用线性变换,你将无法得到这样的结果:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-14.png)
这就是激活函数非线性的重要性,它能够帮助我们构造复杂的决策边界。接着,我们再乘以一个矩阵,加上偏置,最后sigmoid函数将其压缩至这个单元格中,因为sigmoid函数的输出是0到1之间的值。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-15.png)
我们也可以在三维空间中进行上述变换,例如有一个神经网络,其隐藏层有三个神经元,假定权值与偏置都已随机初始化了。![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-16.png)
本例的数据集也是平面中一个正方形内均匀分布的一组点,但现在我们是要将其映射到三维空间中(隐藏层有三个神经元)。我们将平面旋转,然后增加一个维度,然后我们就可以将其乘以权重矩阵(也就是线性变换),再加上偏置。然后我们再实现ReLU,只保留输入中为正的部分。二维时,其输出只再第一象限,推广到三维,其输出只在第一卦限。因此,我们将其他卦限上的点都折叠到第一卦限上来:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-17.png)
然后我们接着进行下一个线性变换并添加偏置。注意:用线性变换永远得不到如下的图像:![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数],人工智能,深度学习,神经网络,人工智能,信息可视化,机器学习,图像处理,python](https://imgs.yssmx.com/Uploads/2023/07/584734-18.png)
这也再次强调了激活函数非线性的重要性,它能帮助我们建立复杂的决策模型。文章来源地址https://www.toymoban.com/news/detail-584734.html
到了这里,关于[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!